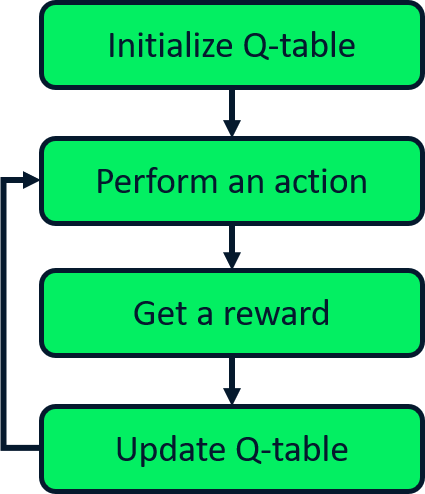
Q-learning
Reinforcement Learning met Gymnasium in Python

Fouad Trad
Machine Learning Engineer
Introductie tot Q-learning
Q-learning vs. SARSA
SARSA

- Update op basis van genomen actie
- On-policy learner
Q-learning

- Update onafhankelijk van genomen acties
- Off-policy learner
Q-learning-update
def update_q_table(state, action, reward, new_state):old_value = Q[state, action]next_max = max(Q[new_state])Q[state, action] = (1 - alpha) * old_value + alpha * (reward + gamma * next_max)
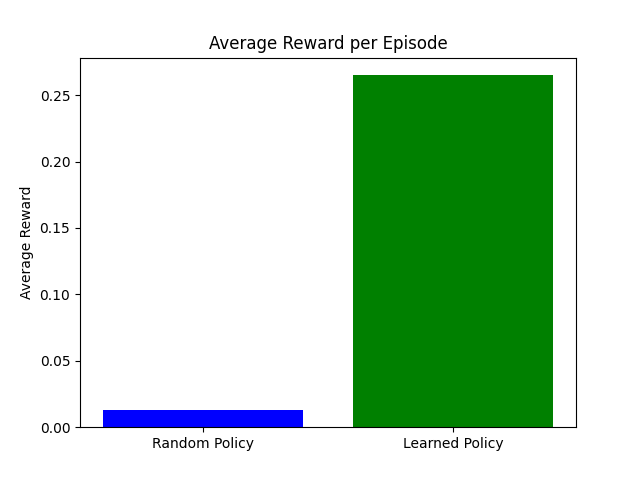
Q-learning-evaluatie