Double Q-learning
Reinforcement Learning met Gymnasium in Python

Fouad Trad
Machine Learning Engineer
Q-learning
- Schat de optimale actie-waardefunctie
- Overschatt Q-waarden door te updaten op basis van max Q
- Kan tot suboptimale policy leiden

Double Q-learning
- Behoudt twee Q-tabellen
- Elke tabel wordt geüpdatet op basis van de ander
- Vermindert risico op overschatte Q-waarden
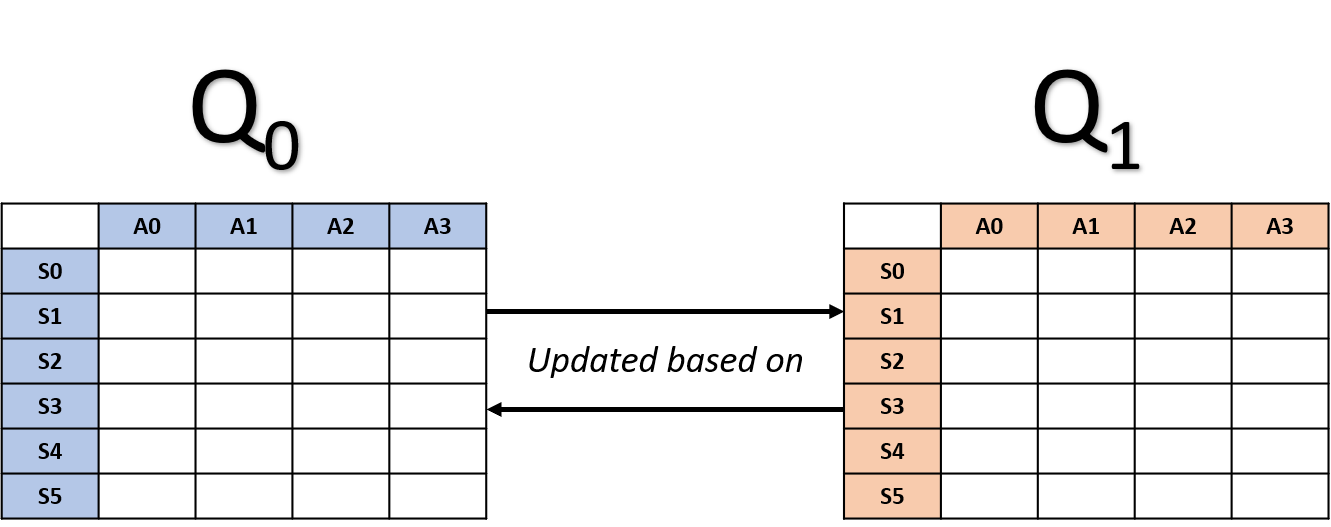
Double Q-learning-updates
- Kies willekeurig een tabel
Q0-update
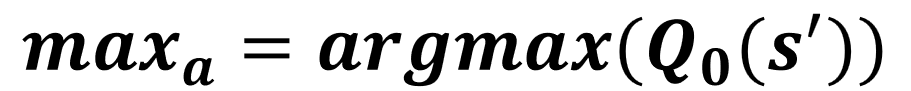
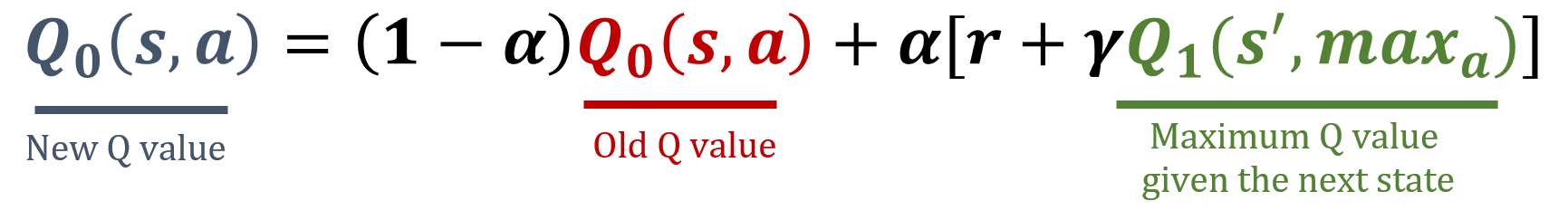
Q1-update
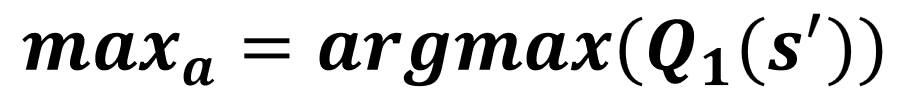
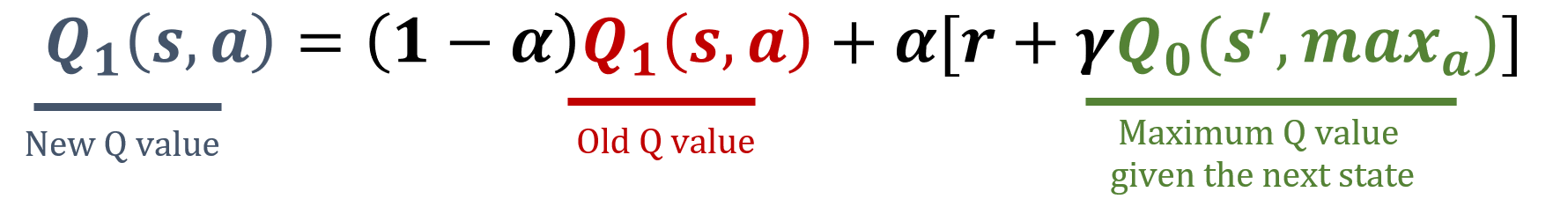
Double Q-learning
- Vermindert overschatting
- Wisselt updates tussen Q0 en Q1 af
- Beide tabellen dragen bij aan het leren
Implementatie met Frozen Lake

update_q_tables() implementeren
def update_q_tables(state, action, reward, next_state): # Select a random Q-table index (0 or 1) i = np.random.randint(2)# Update the corresponding Q-table best_next_action = np.argmax(Q[i][next_state])Q[i][state, action] = (1 - alpha) * Q[i][state, action] + alpha * (reward + gamma * Q[1-i][next_state, best_next_action])
Beleid van de agent