Multi-armed bandits
Reinforcement Learning met Gymnasium in Python

Fouad Trad
Machine Learning Engineer
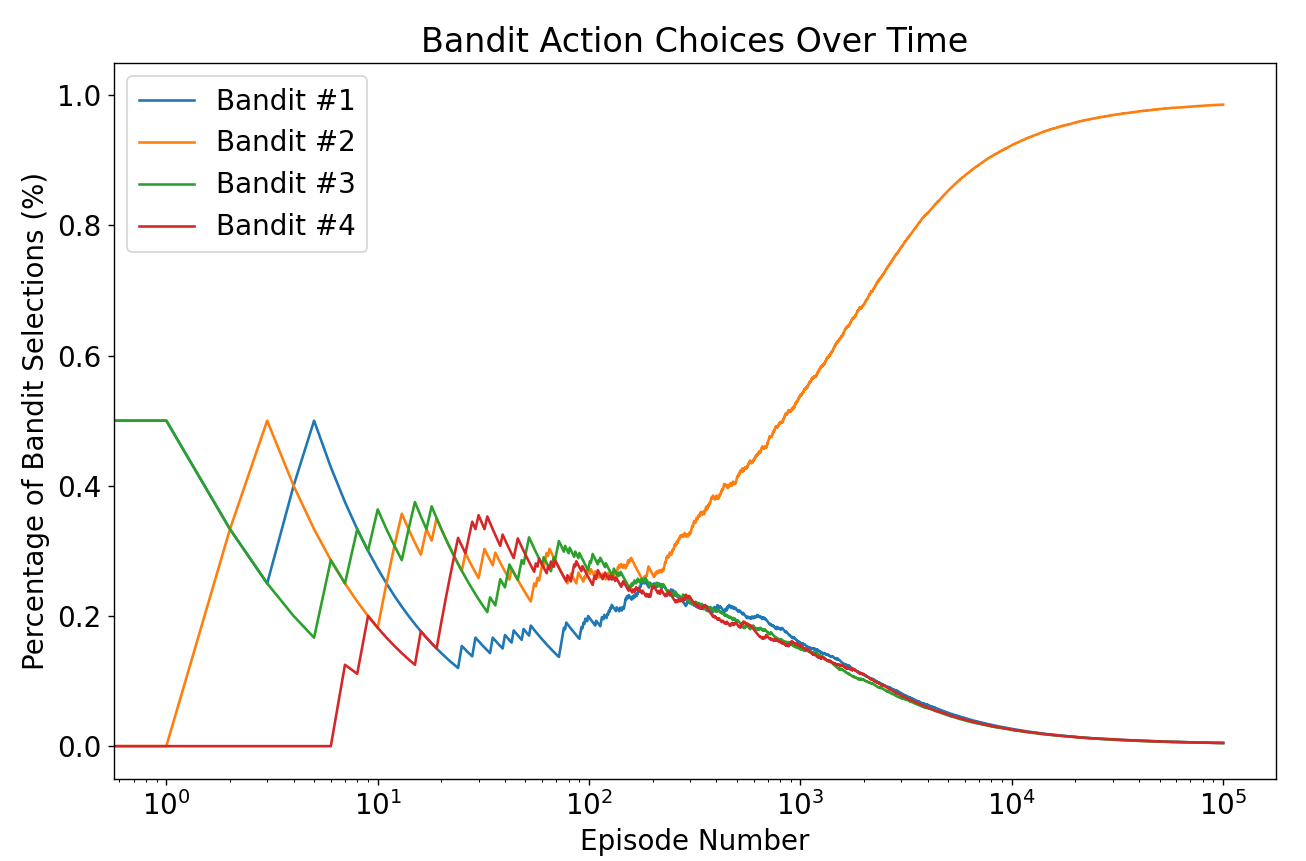
Multi-armed bandits

Fruitautomaten

- Beloning per arm is 0 of 1
- Doel van de agent → maximale totale beloning
De oplossing
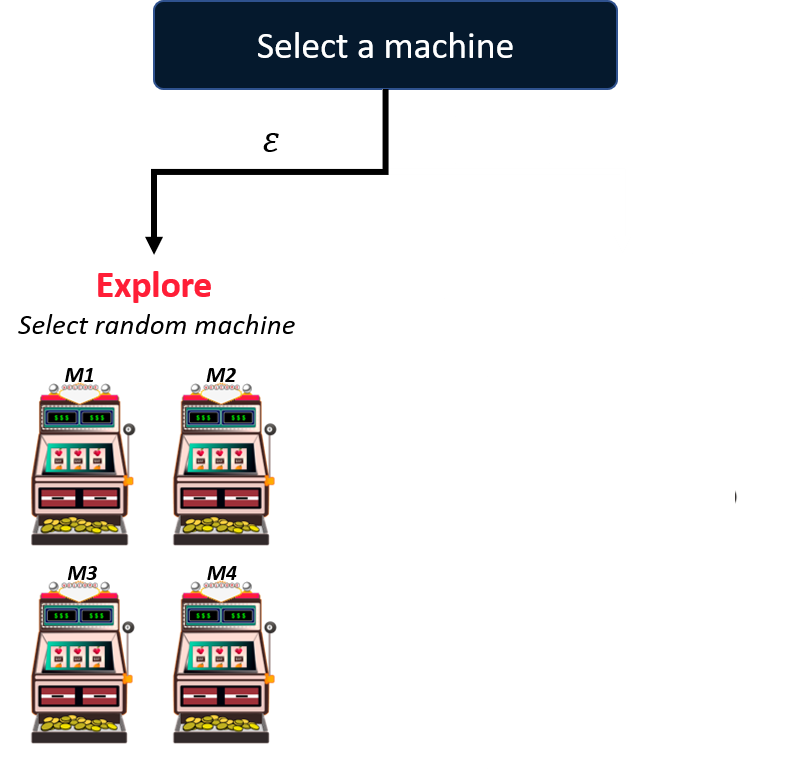
De oplossing

Selecties analyseren
selections_percentage = np.zeros((n_iterations, n_bandits))

Selecties analyseren
selections_percentage = np.zeros((n_iterations, n_bandits))for i in range(n_iterations): selections_percentage[i, selected_arms[i]] = 1
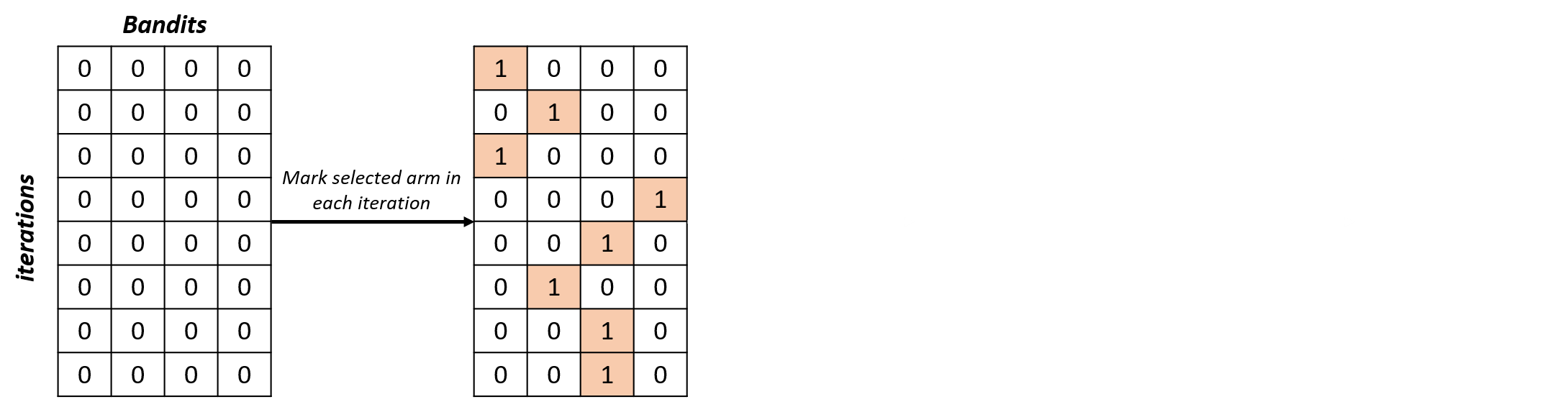
Selecties analyseren
selections_percentage = np.zeros((n_iterations, n_bandits))for i in range(n_iterations): selections_percentage[i, selected_arms[i]] = 1selections_percentage = np.cumsum(selections_percentage, axis=0) / np.arange(1, n_iterations + 1).reshape(-1, 1)
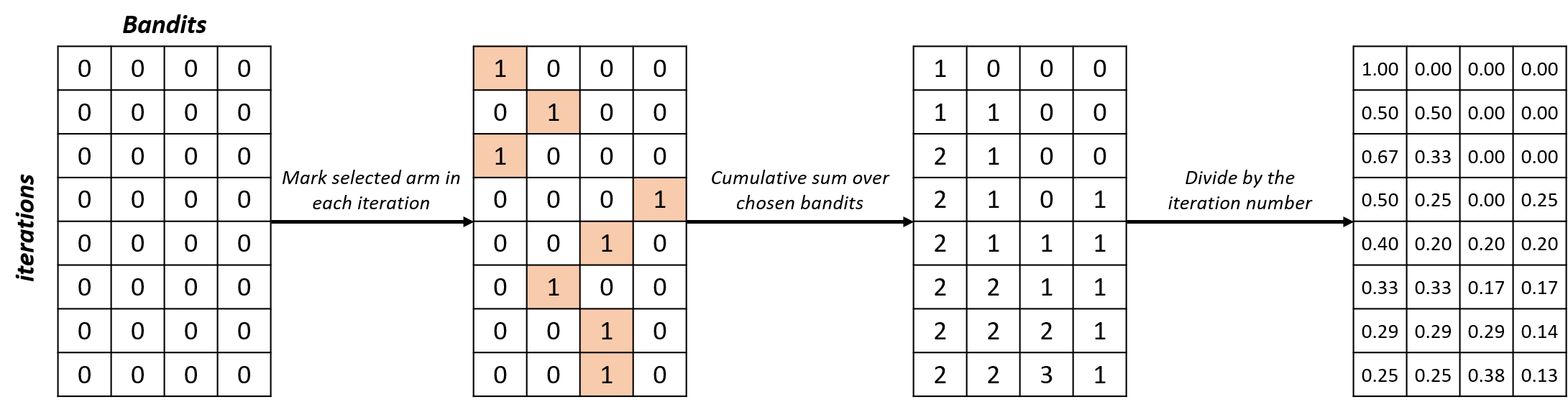
Selecties analyseren