Policy-iteratie en value-iteratie
Reinforcement Learning met Gymnasium in Python

Fouad Trad
Machine Learning Engineer
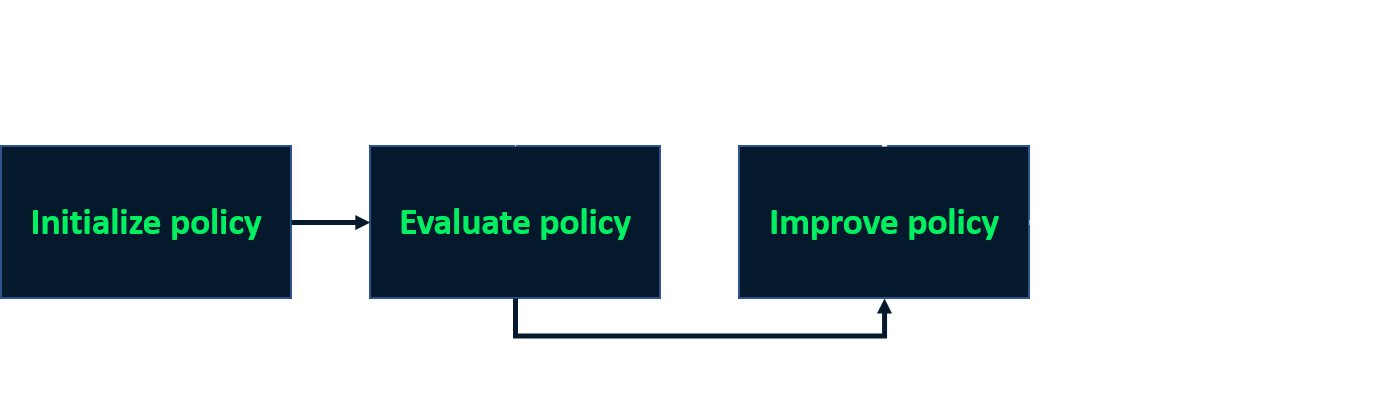
Policy-iteratie
- Iteratief proces om een optimale policy te vinden

Policy-iteratie
- Iteratief proces om een optimale policy te vinden

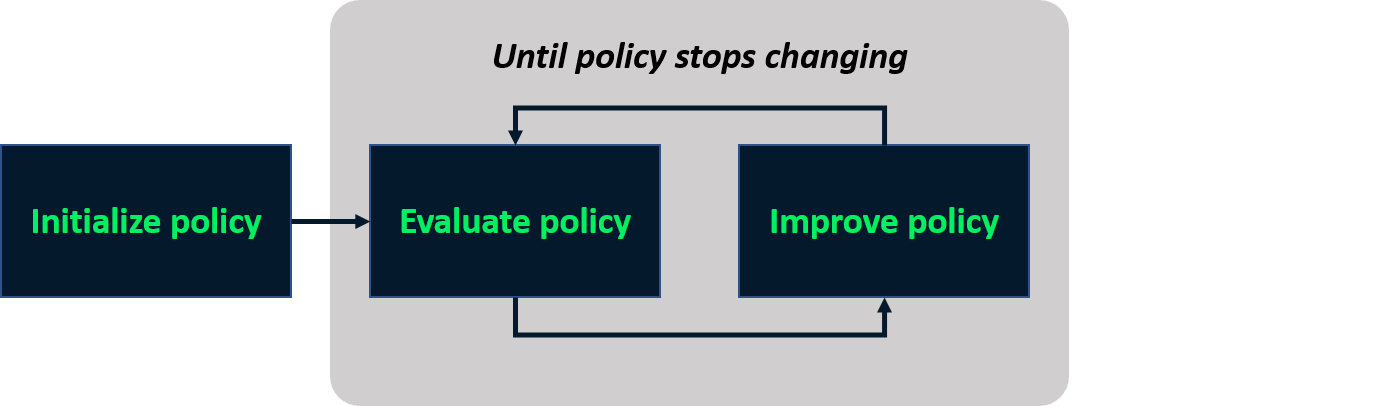
Policy-iteratie
- Iteratief proces om een optimale policy te vinden
Policy-iteratie
- Iteratief proces om een optimale policy te vinden
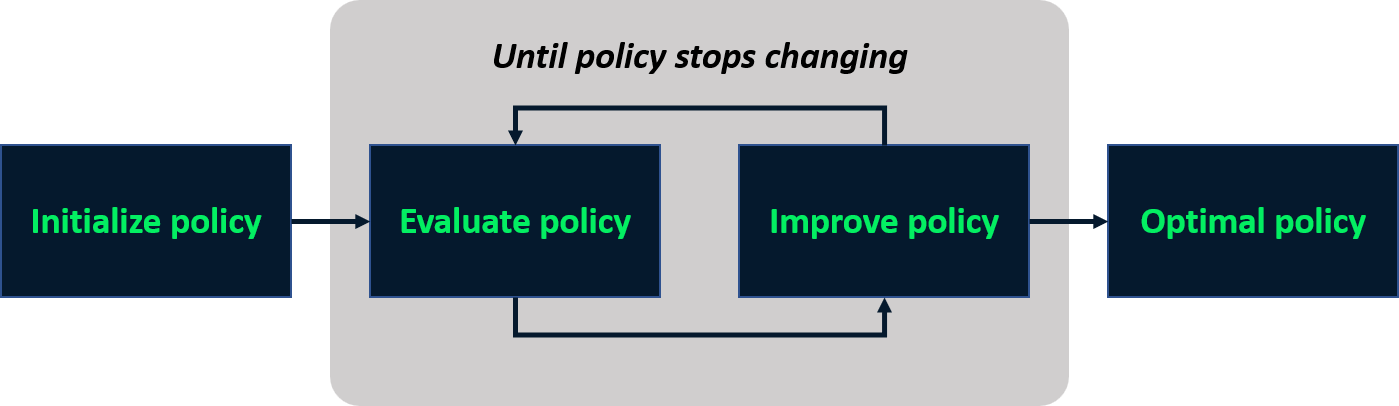
Policy-iteratie
- Iteratief proces om een optimale policy te vinden
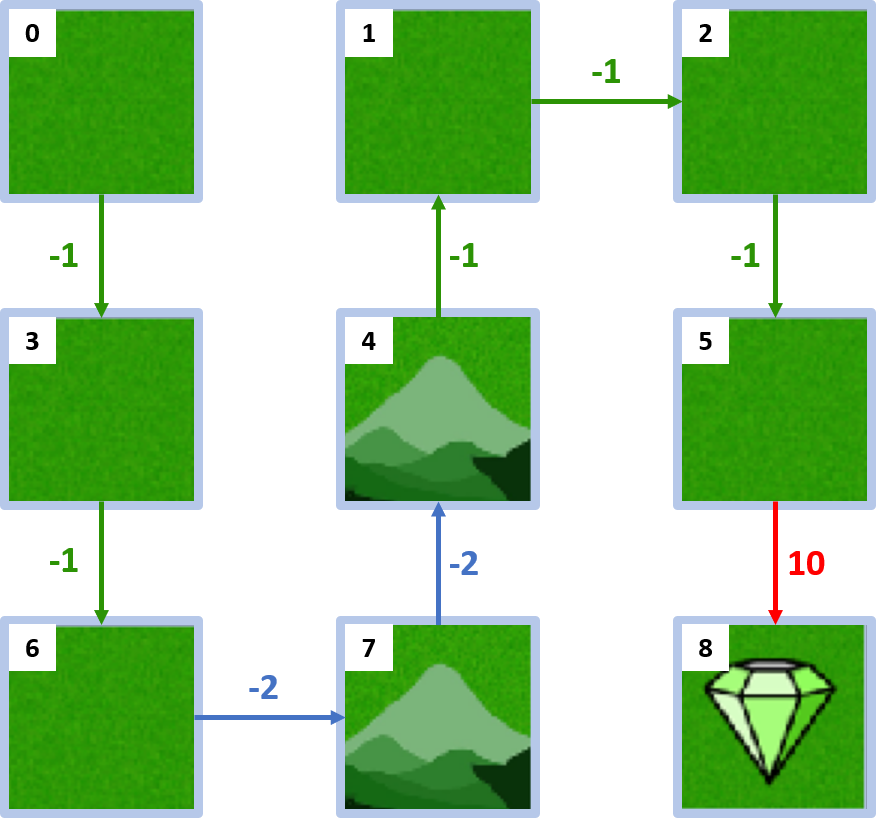
Gridworld
Optimale policy
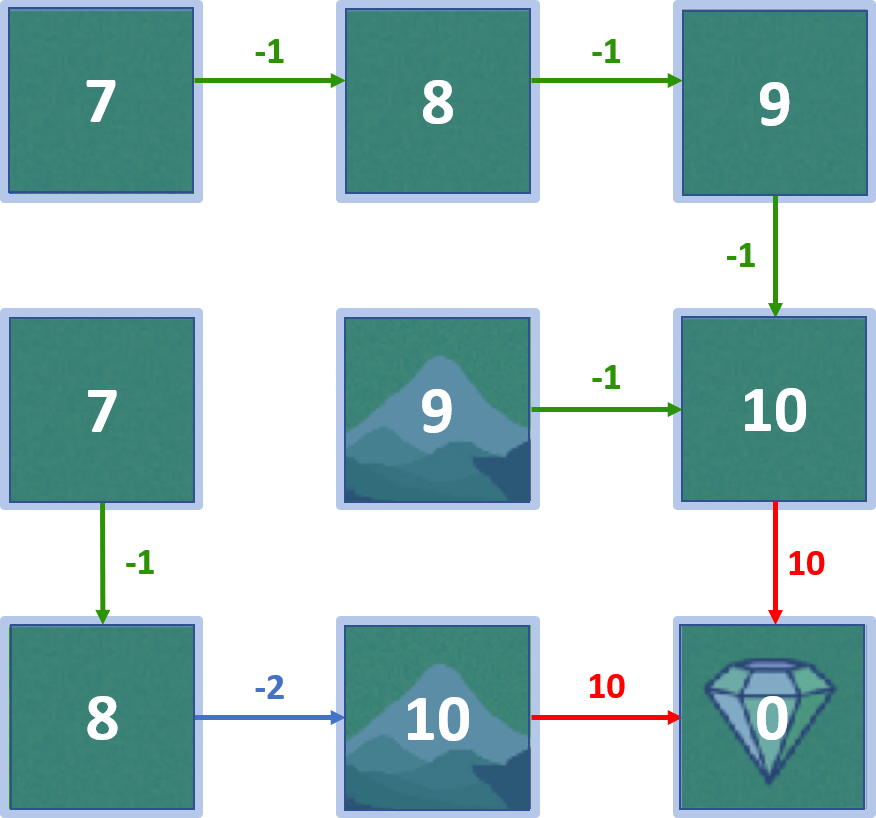
Value-iteratie
- Combineert policy-evaluatie en -verbetering in één stap
- Berekent de optimale toestand-waardefunctie
- Leidt daaruit de policy af

Value-iteratie
- Combineert policy-evaluatie en -verbetering in één stap.
- Berekent de optimale toestand-waardefunctie
- Leidt daaruit de policy af

Value-iteratie
- Combineert policy-evaluatie en -verbetering in één stap.
- Berekent de optimale toestand-waardefunctie
- Leidt daaruit de policy af
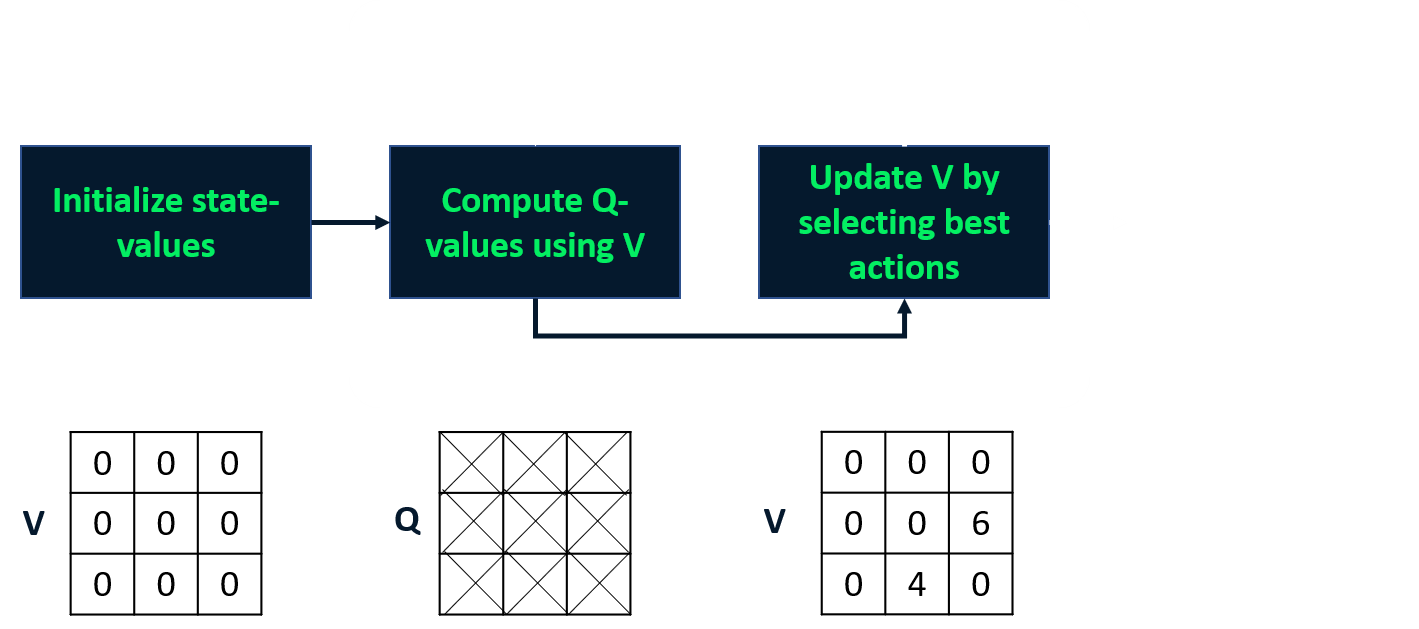
Value-iteratie
- Combineert policy-evaluatie en -verbetering in één stap.
- Berekent de optimale toestand-waardefunctie
- Leidt daaruit de policy af
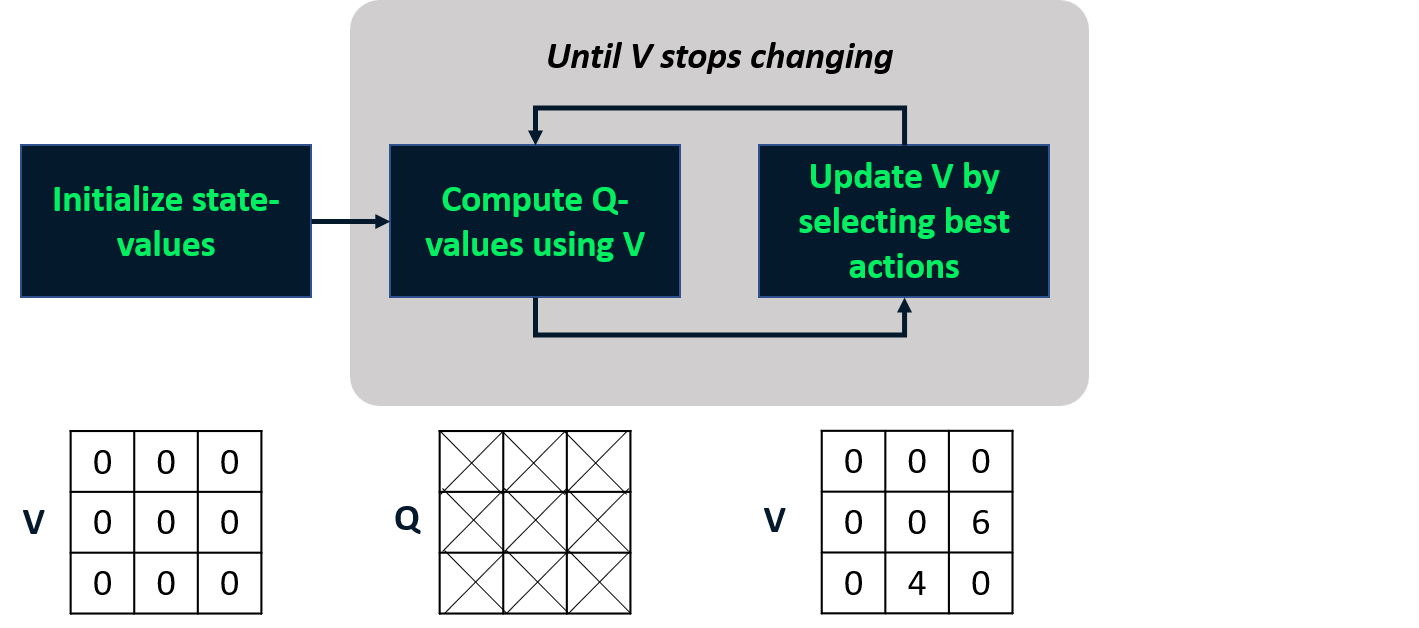
Value-iteratie
- Combineert policy-evaluatie en -verbetering in één stap.
- Berekent de optimale toestand-waardefunctie
- Leidt daaruit de policy af
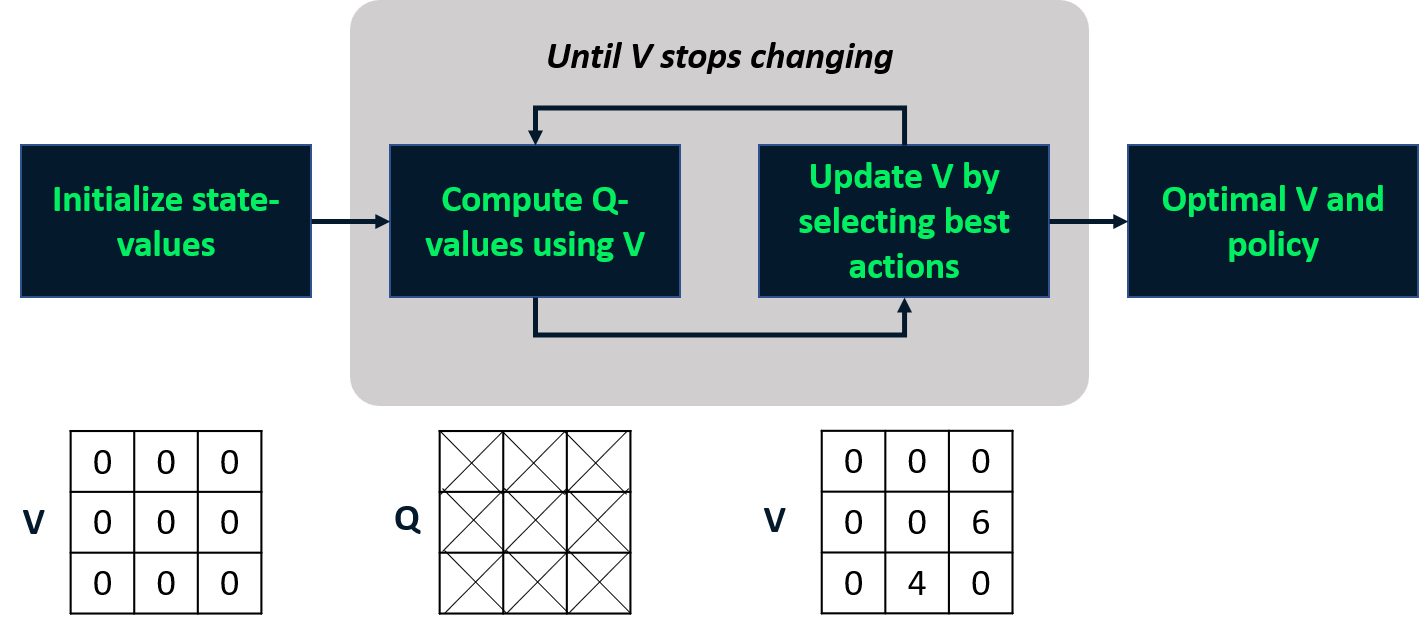
Optimale policy

