Datapijplijnen op Kubernetes
Introductie tot Kubernetes

Frank Heilmann
Platform Architect and Freelance Instructor
Wat zijn datapijplijnen?
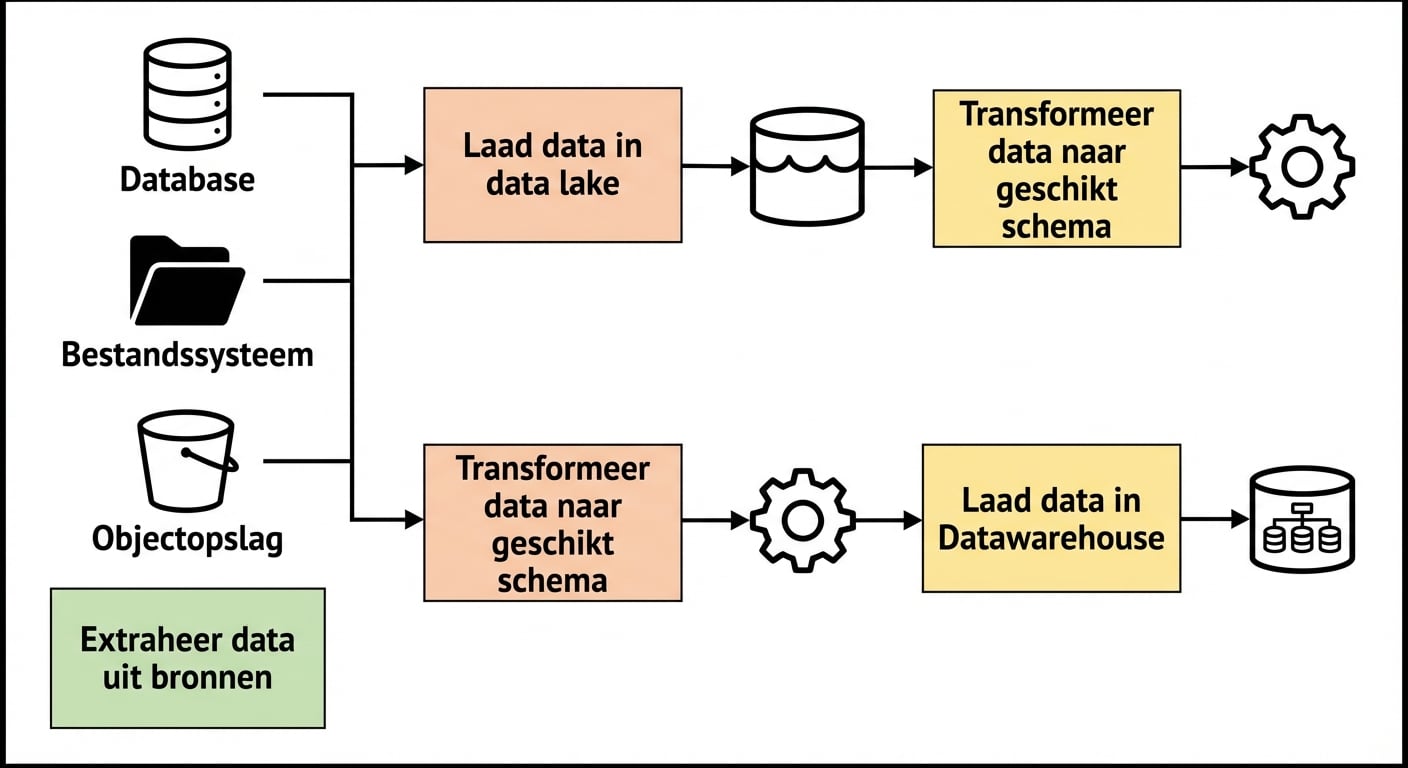
Datapijplijnen op Kubernetes
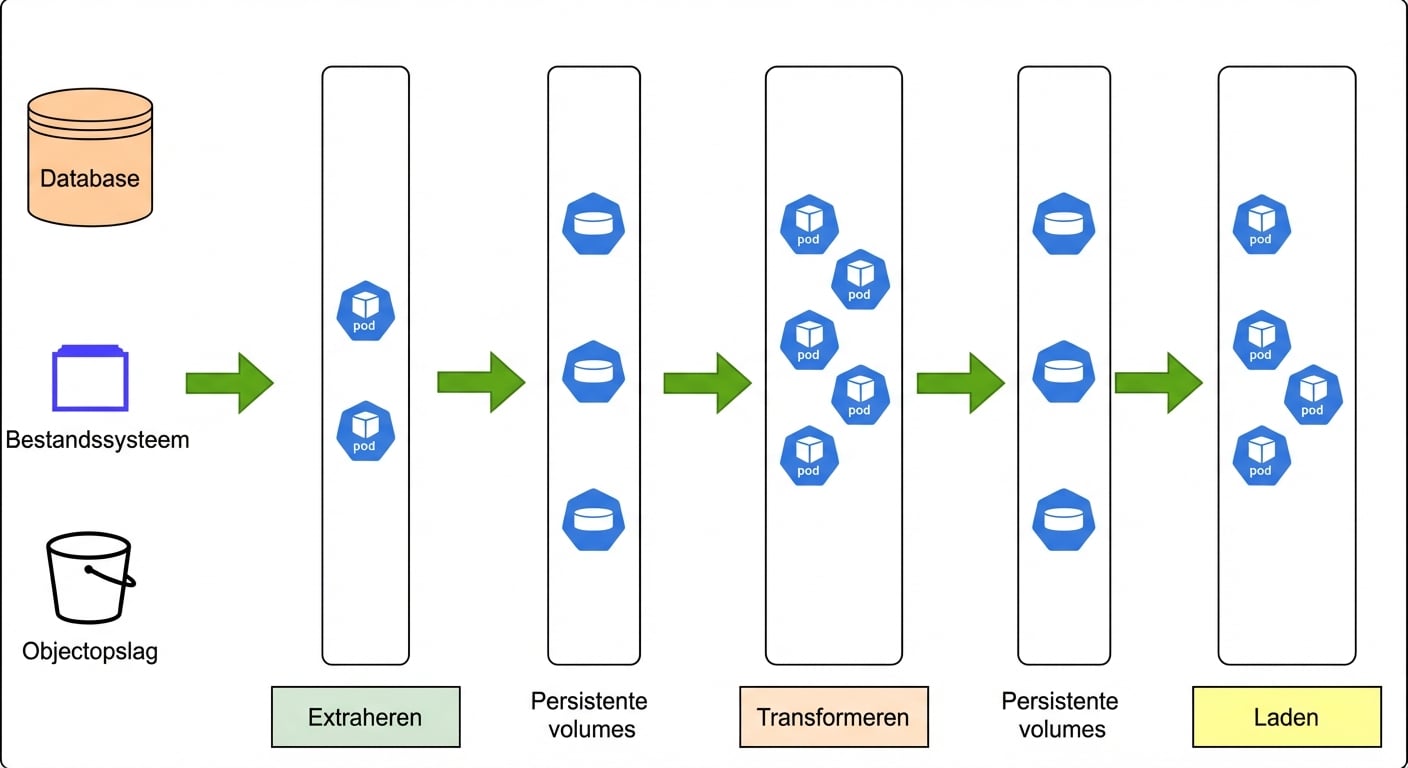
Introductie tot Kubernetes
Frank Heilmann
Platform Architect and Freelance Instructor

