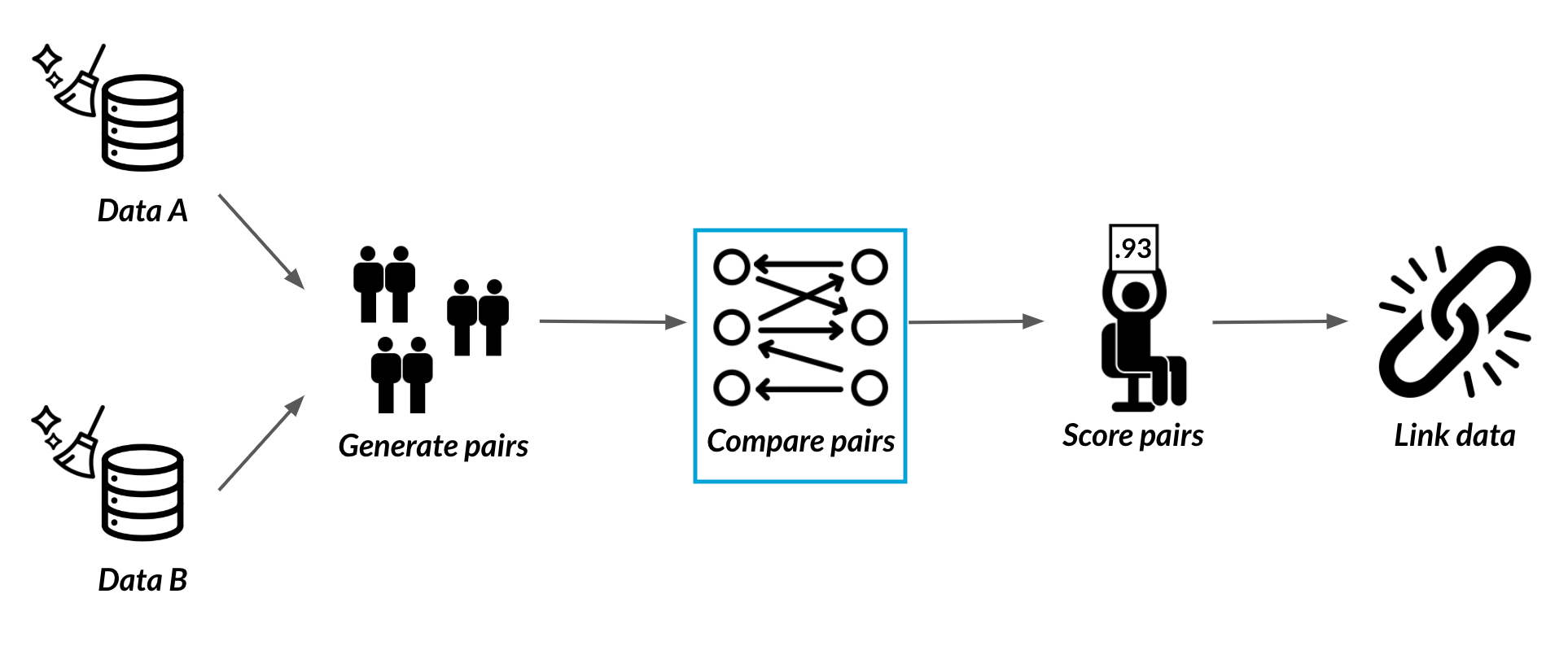
Paren genereren en vergelijken
Data opschonen in R

Maggie Matsui
Content Developer @ DataCamp
Als joins niet werken
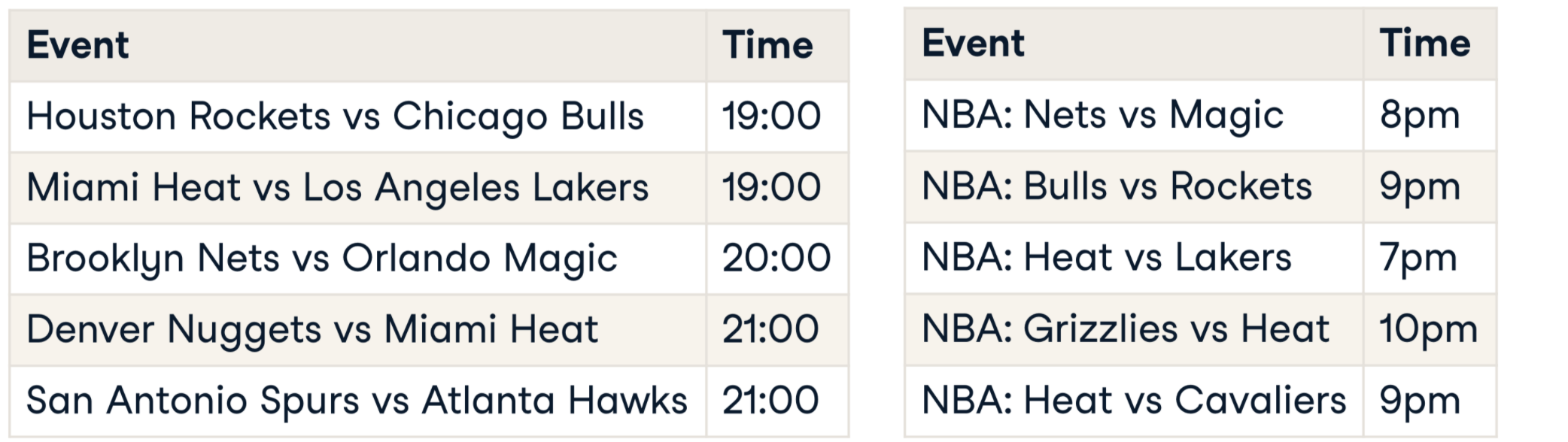
Als joins niet werken
Wat is record linkage?

Wat is record linkage?

Wat is record linkage?

Wat is record linkage?
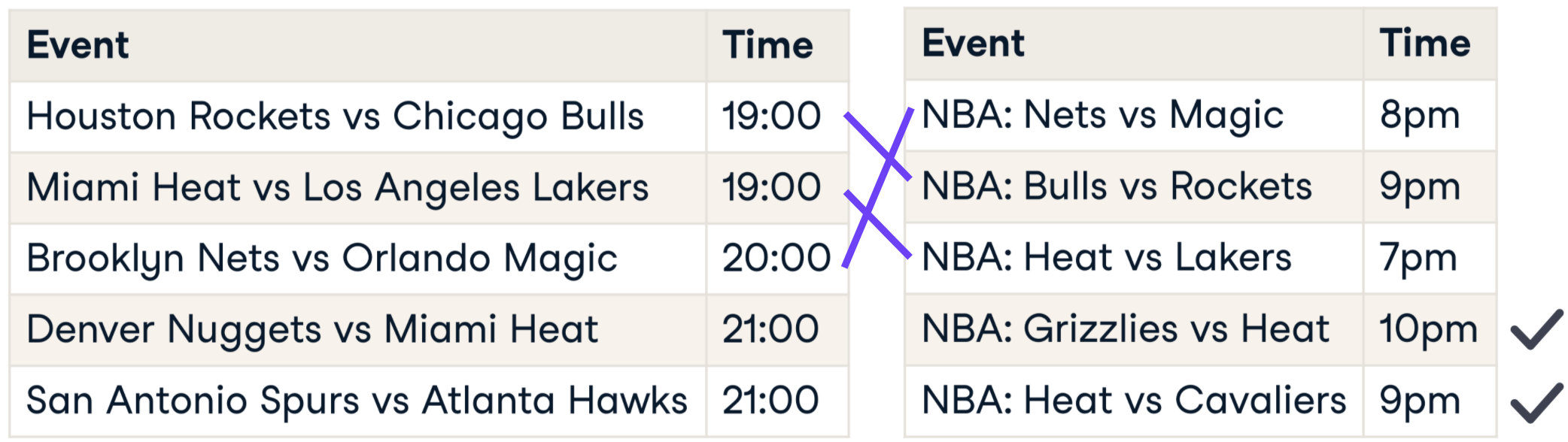
Wat is record linkage?
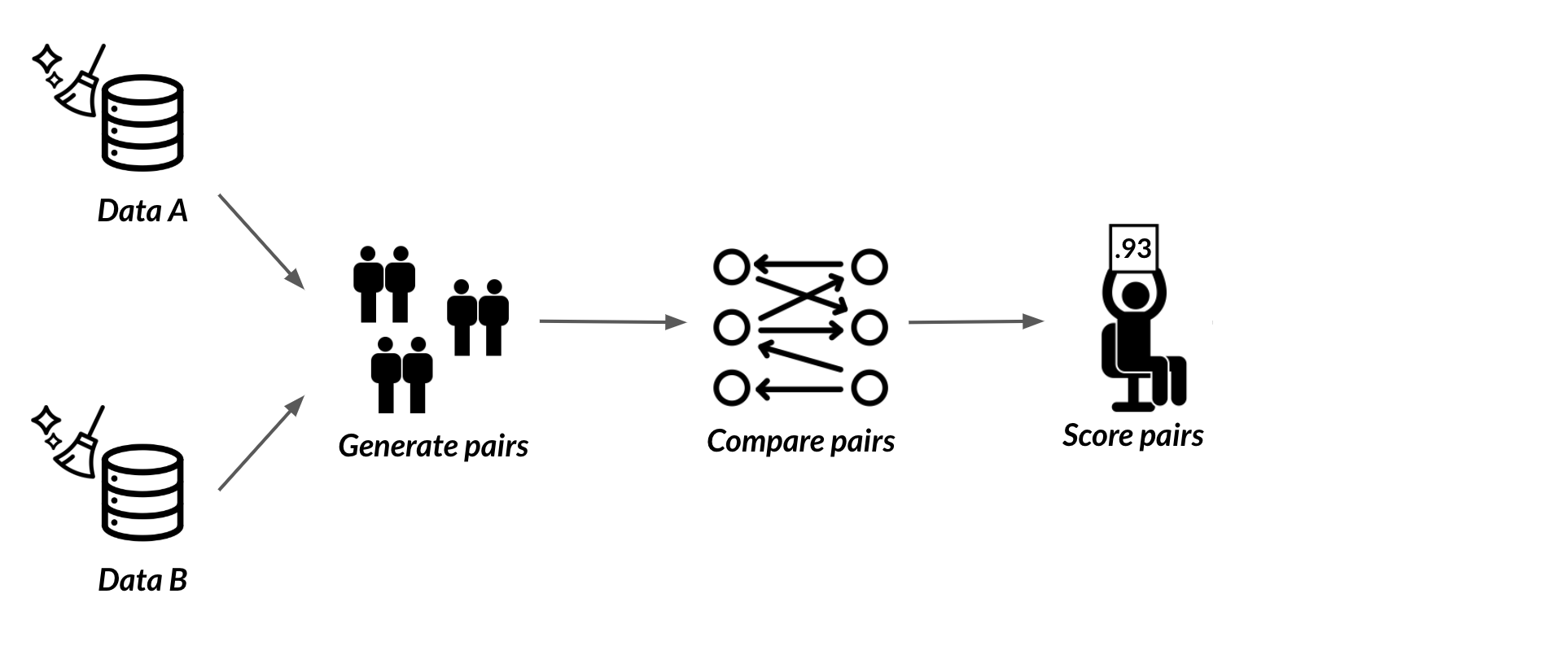
Wat is record linkage?
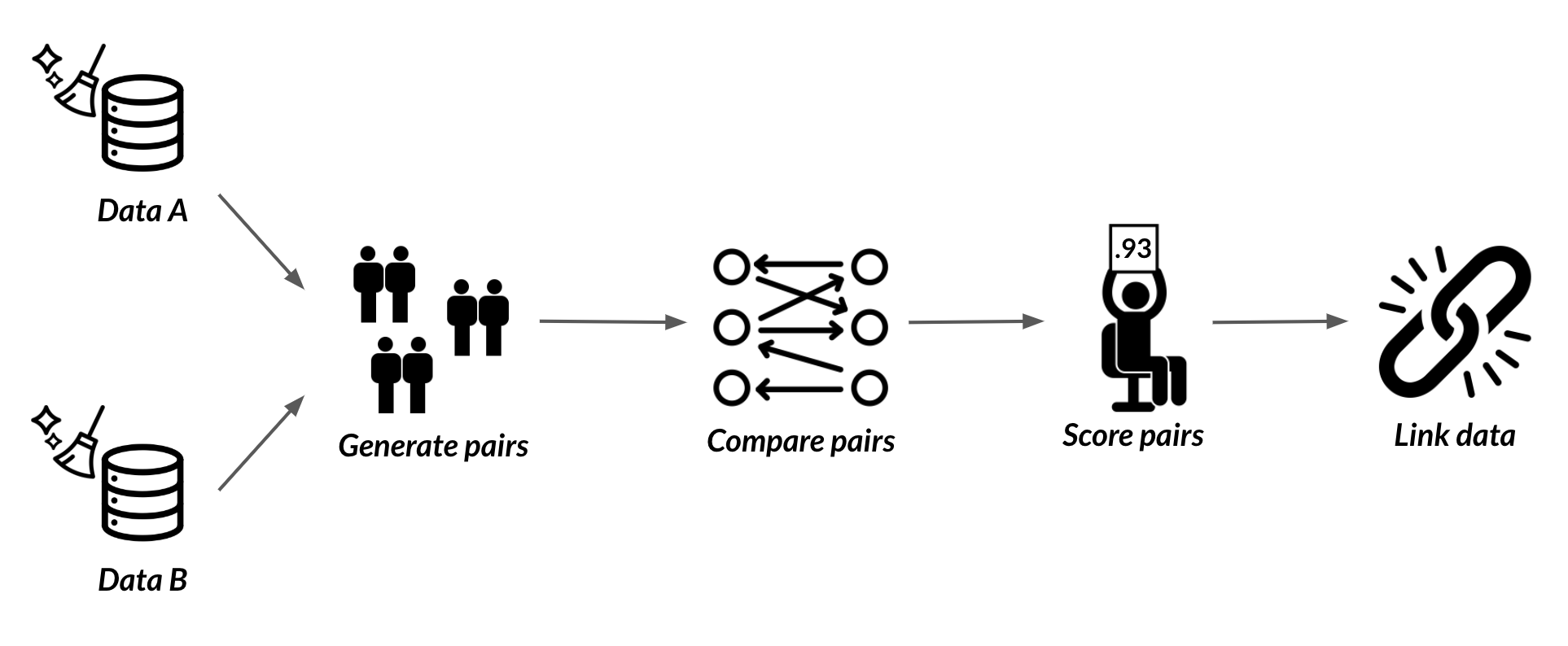
Wat is record linkage?
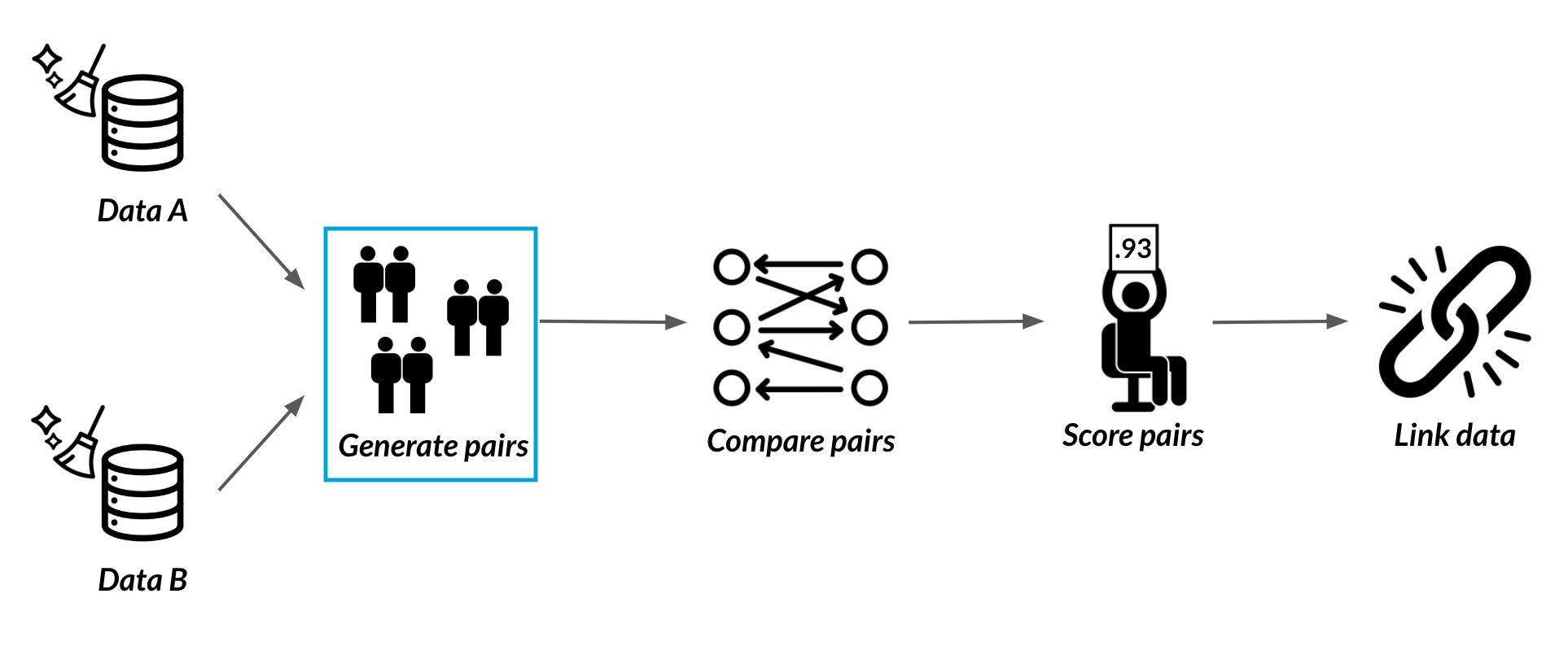
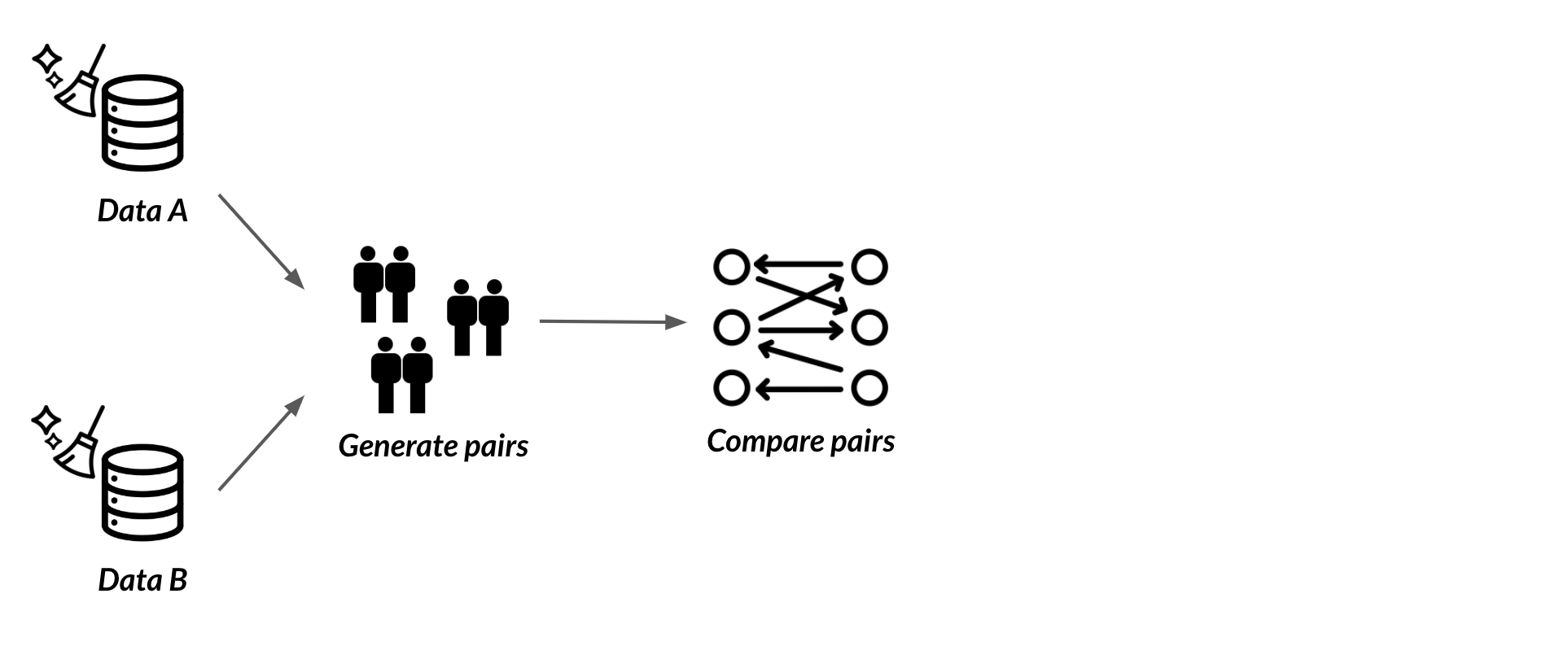
Paren van records
Paren genereren
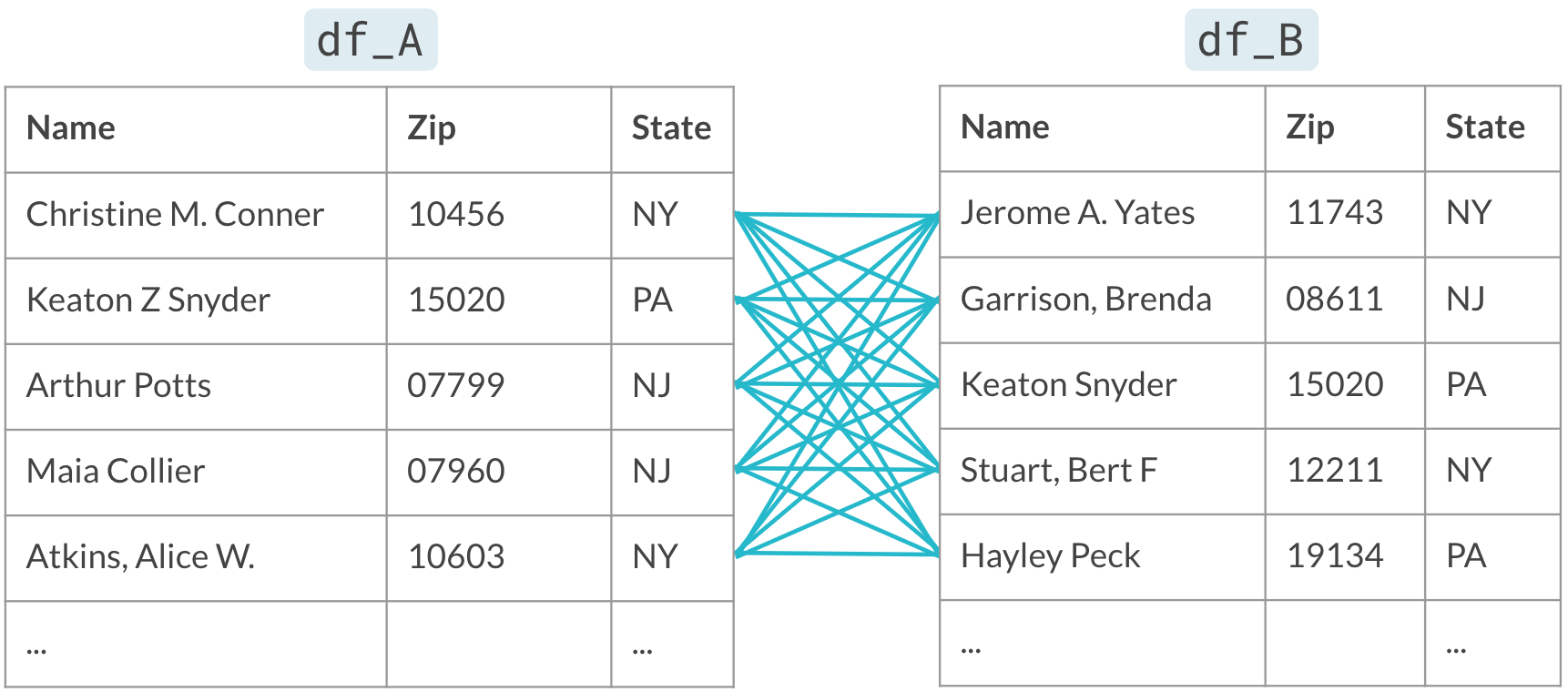
Te veel paren
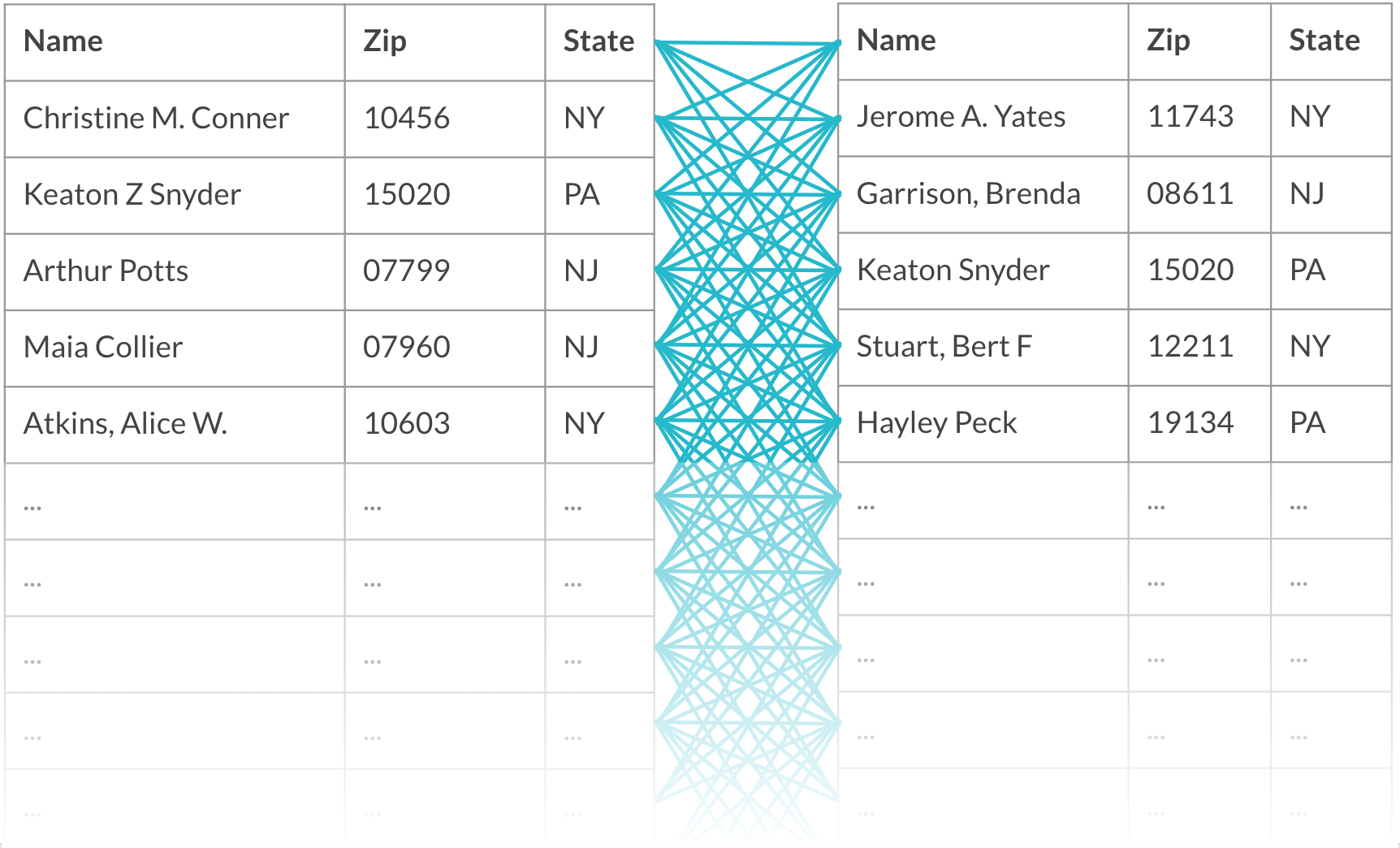
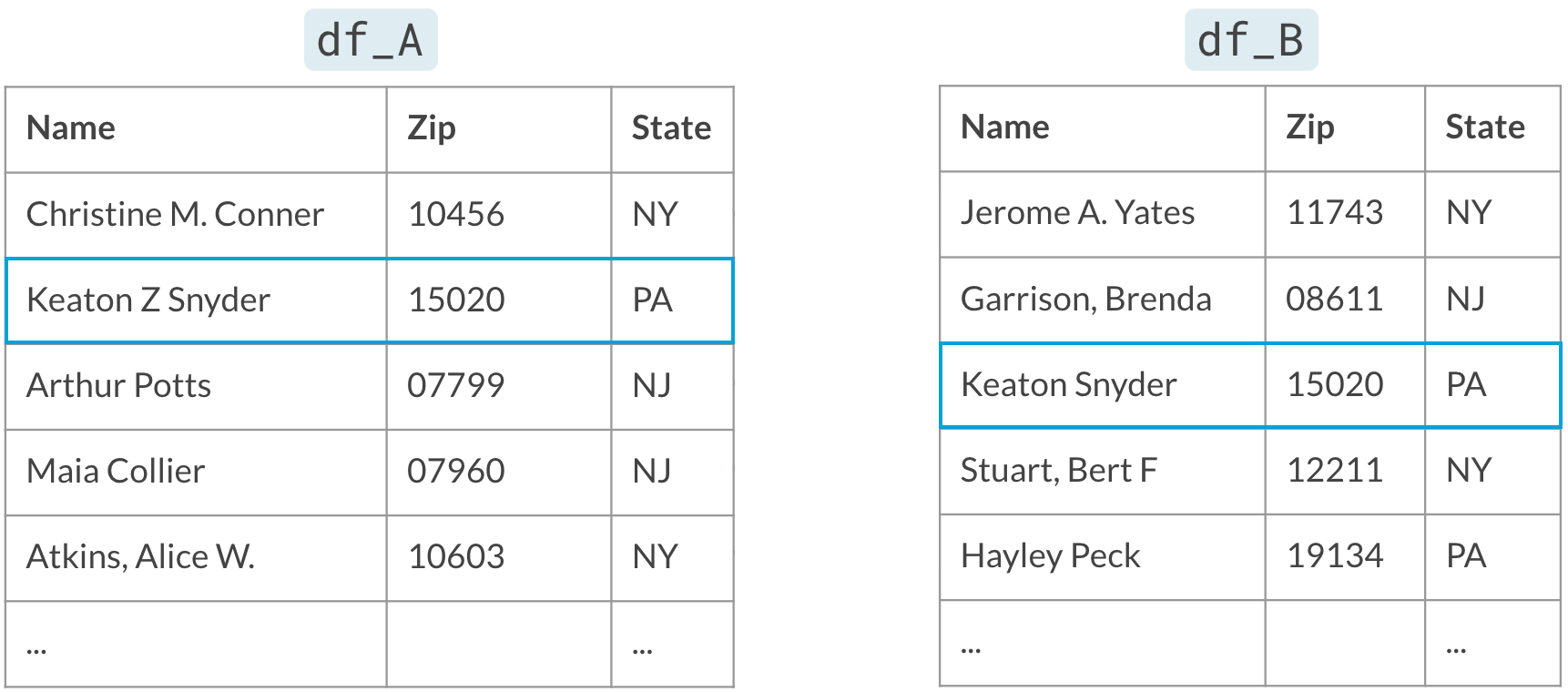
Blocking
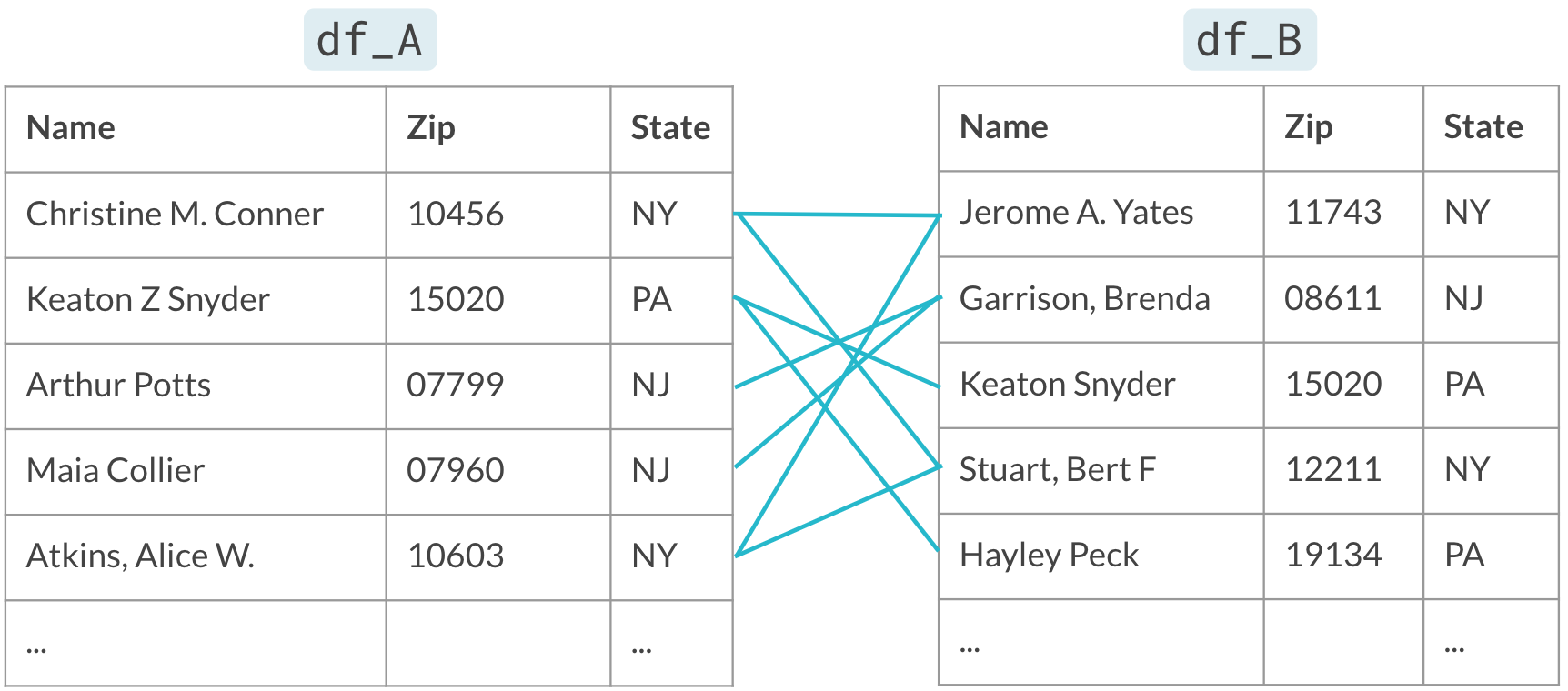
Neem alleen paren mee die overeenkomen op de blockingvariabele (State)
Paren vergelijken