Embeddings en positionele codering
Transformermodels met PyTorch

James Chapman
Curriculum Manager, DataCamp
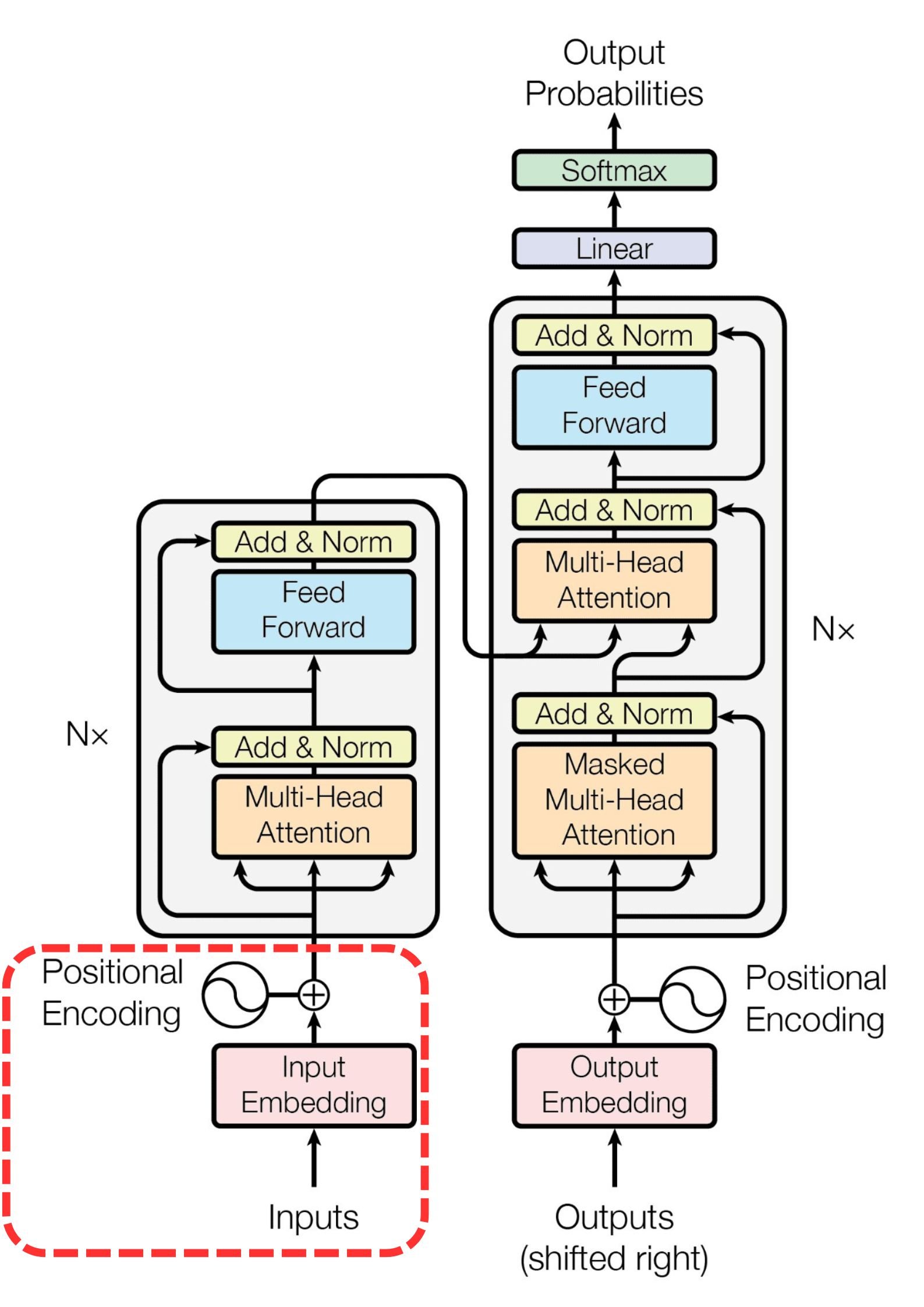
Embeddings en positionele codering in transformers
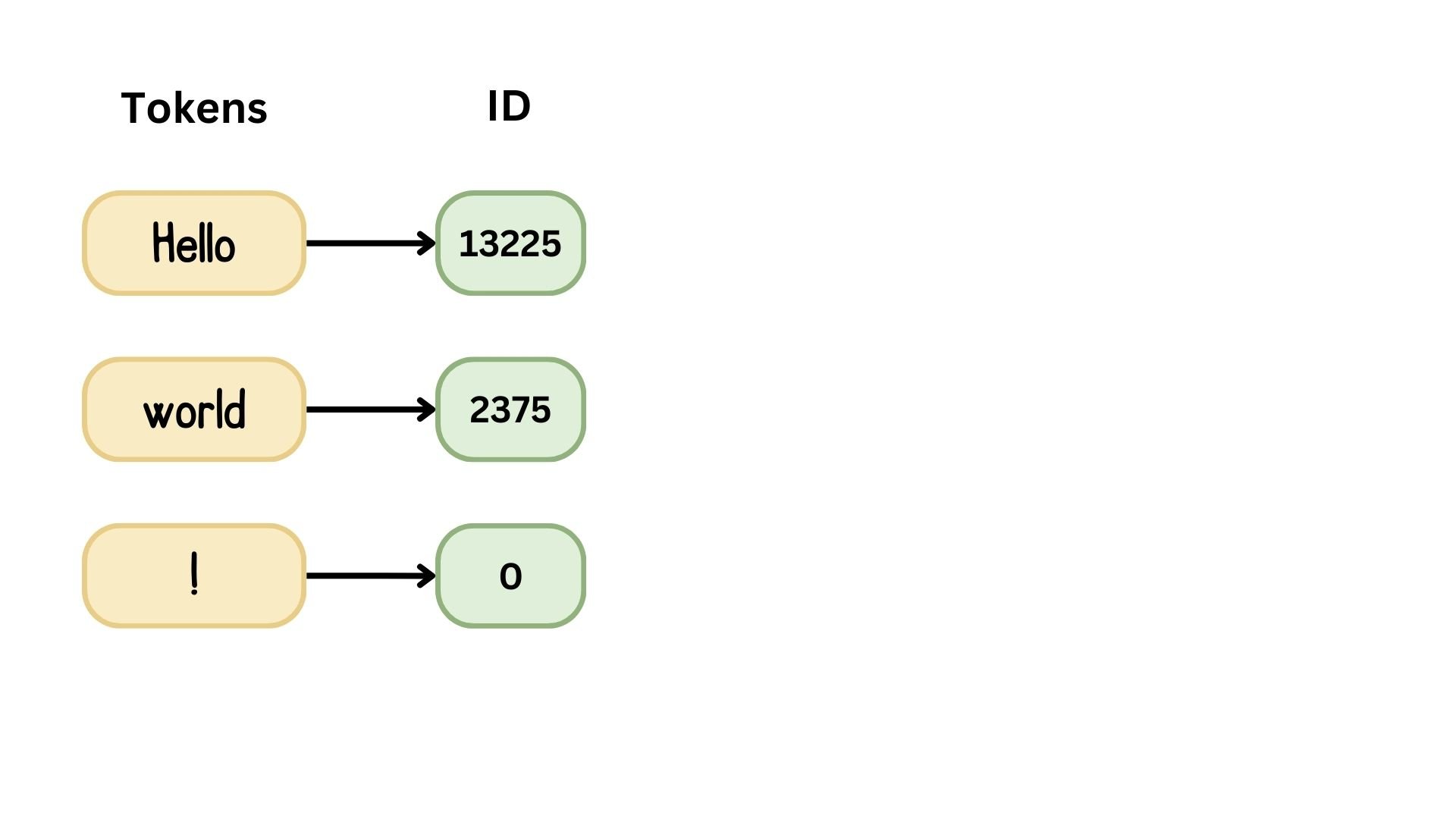
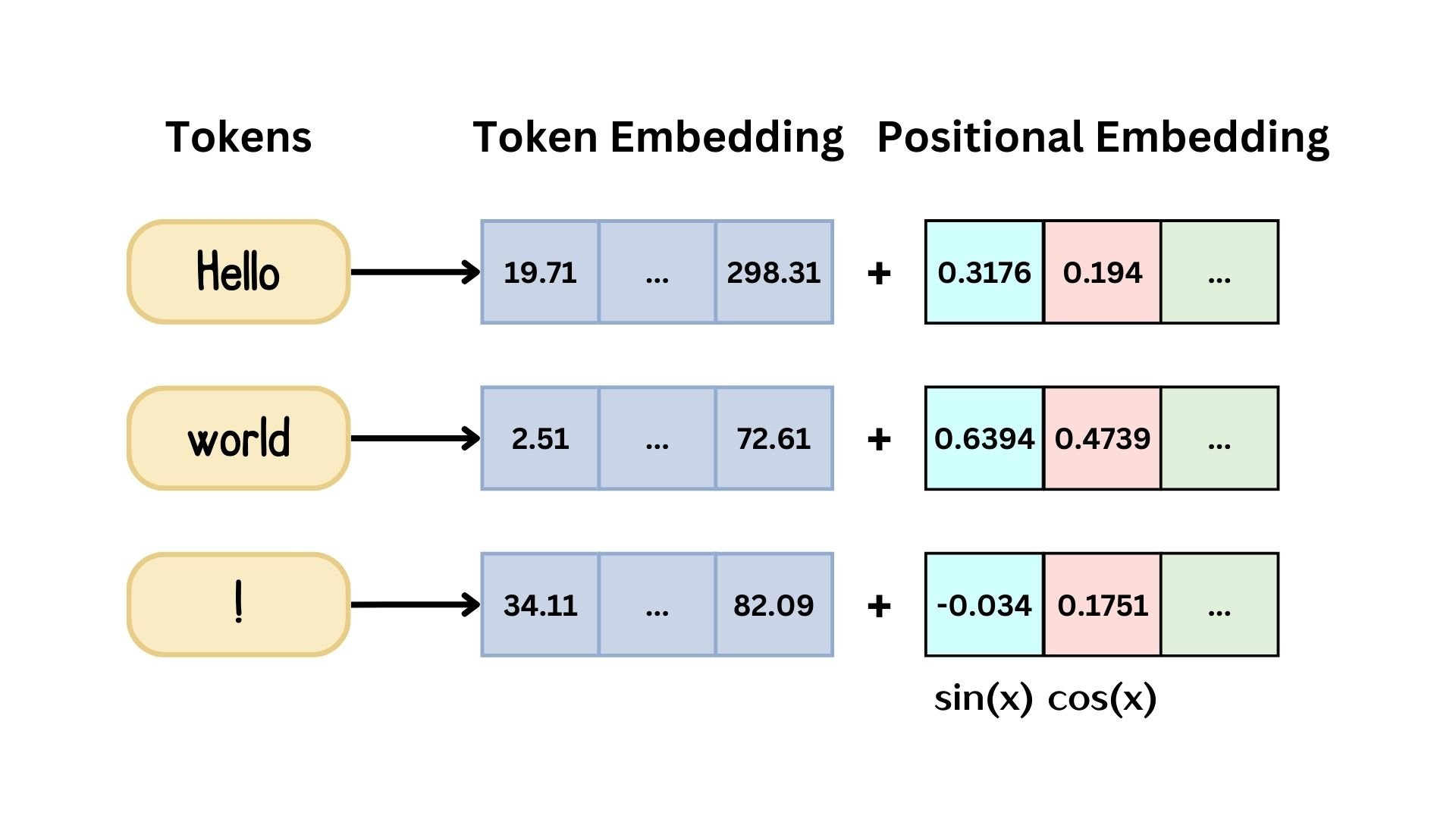
Reeksen embedden

Reeksen embedden
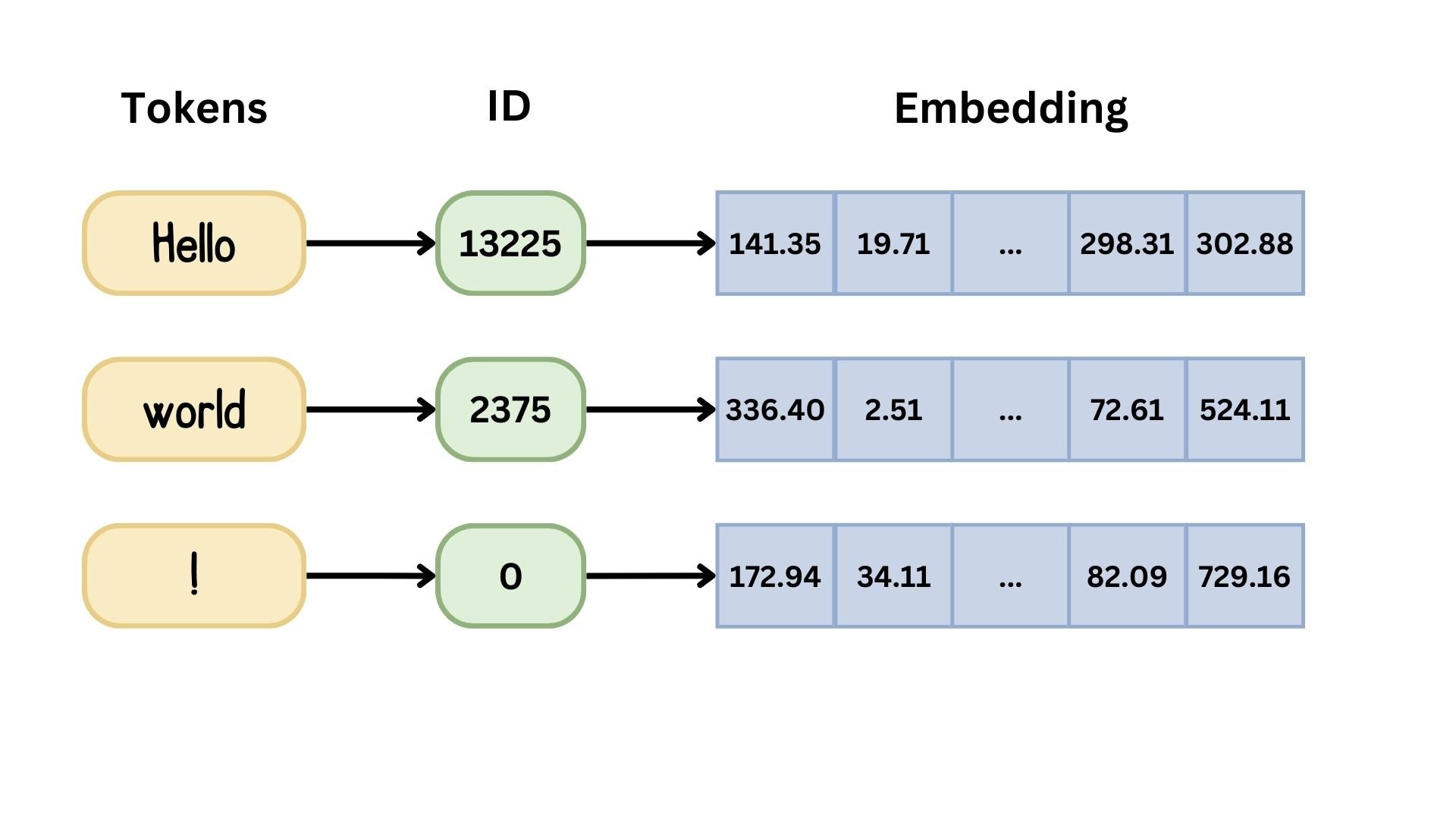
Reeksen embedden
Positionele codering
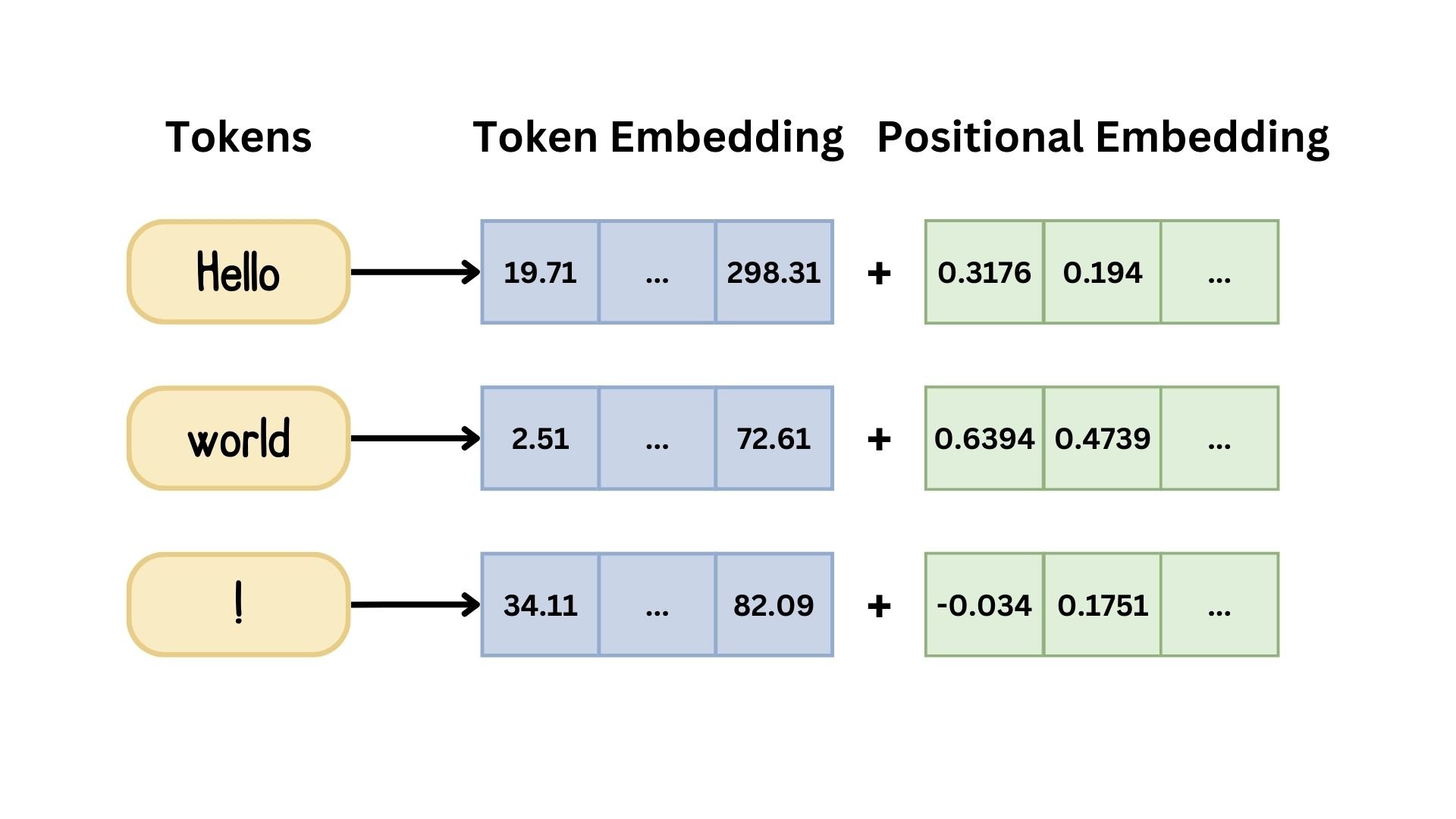
Positionele codering
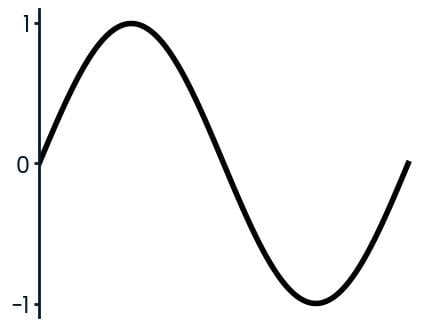
sin(x)
$$ PE_{(pos, 2i)}=\sin(\frac{pos}{10000^{2i/d_{model}}}) $$
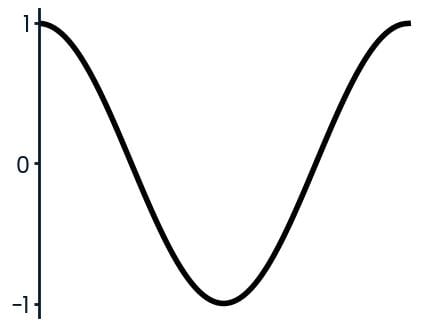
cos(x)
$$ PE_{(pos, 2i+1)}=\cos(\frac{pos}{10000^{2i/d_{model}}}) $$

