De infer-pijplijn vervolgen
Hypothesis Testing in R

Richie Cotton
Data Evangelist at DataCamp
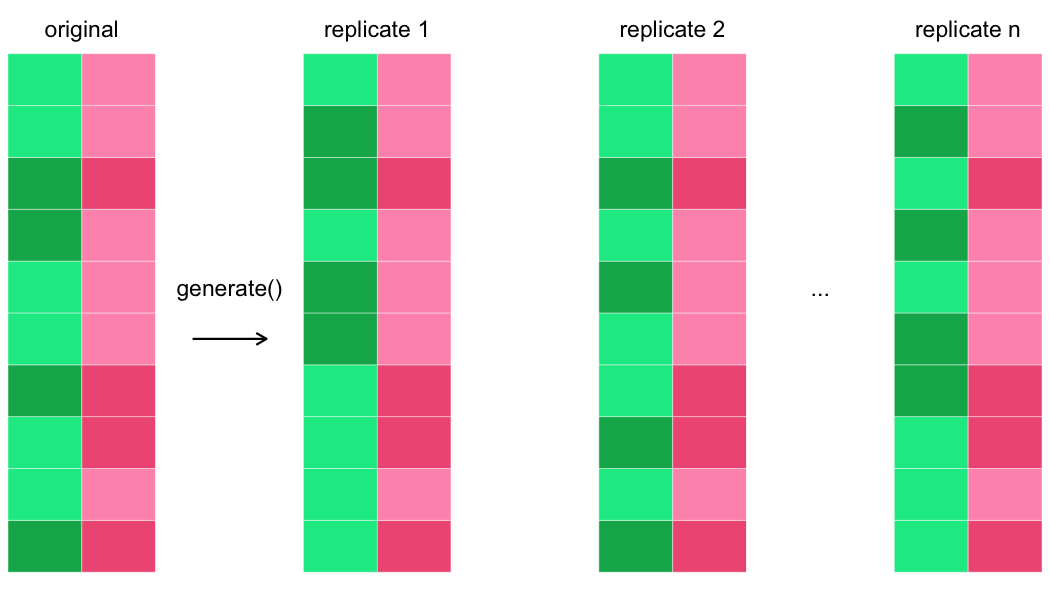
Veel replicaties genereren
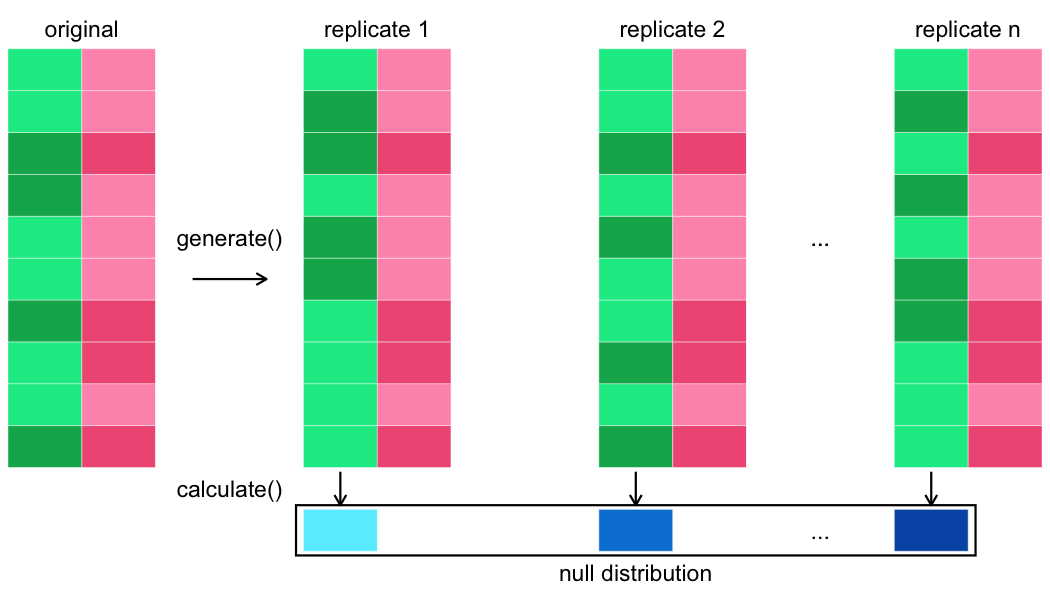
De toetsingsstatistiek berekenen
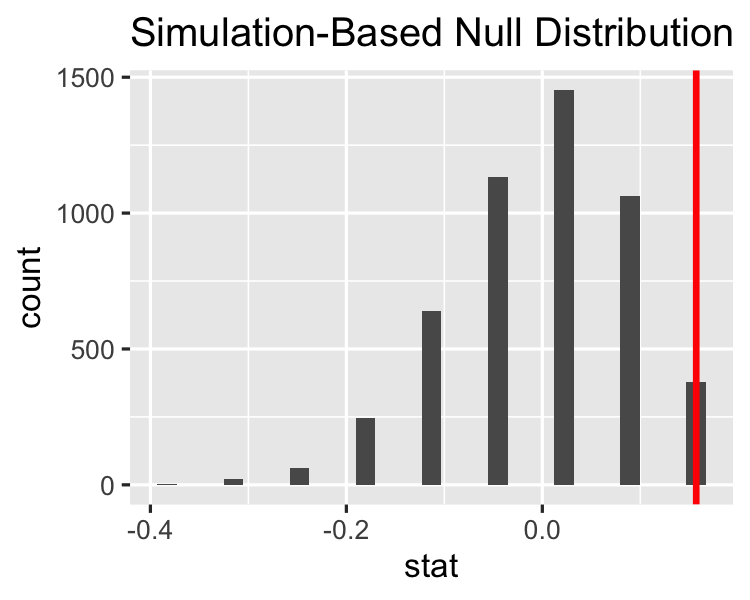
De nulverdeling visualiseren
visualize(null_distn)
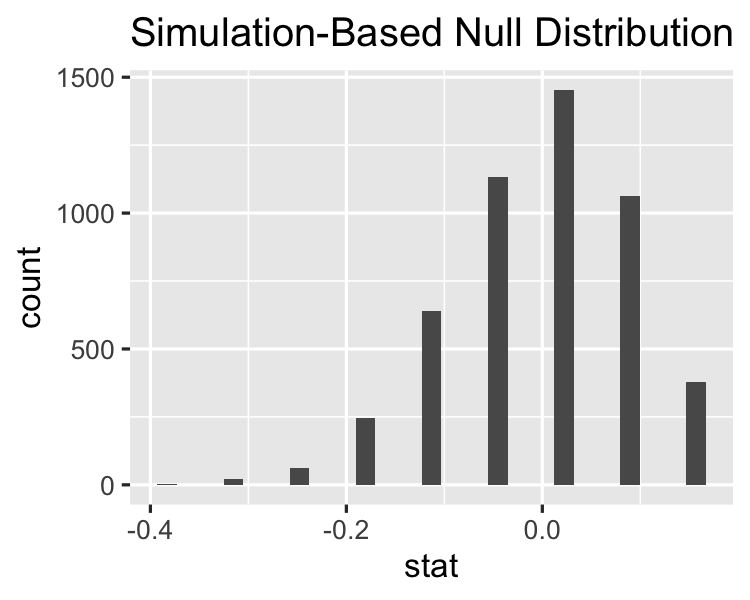
Toetsingsstatistiek op het originele dataset
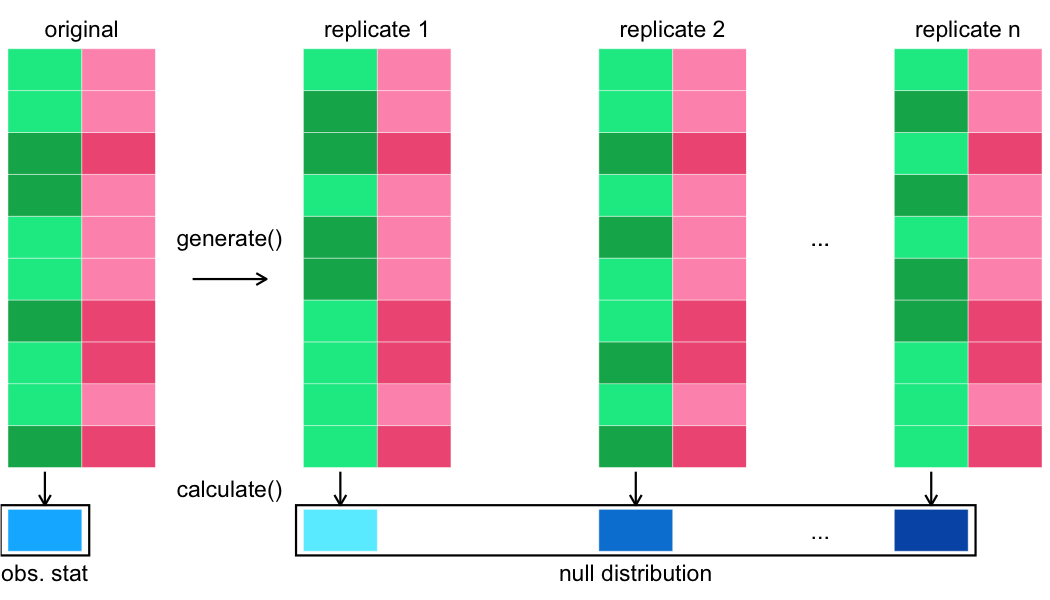
Nulverdeling vs. geobserveerde statistiek