Eén-steekproef proportietesten
Hypothesis Testing in R

Richie Cotton
Data Evangelist at DataCamp
De p-waarde berekenen
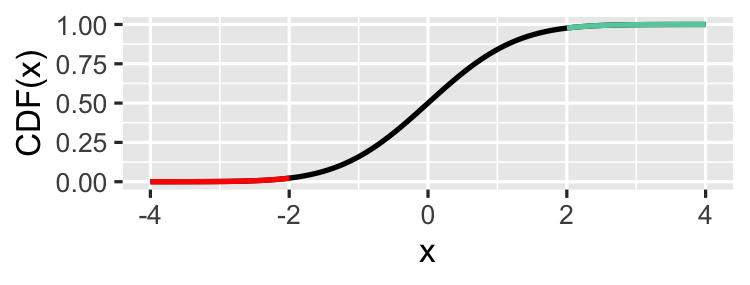 Linkerstaart ("kleiner dan")
Linkerstaart ("kleiner dan")
p_value <- pnorm(z_score)
Rechterstaart ("groter dan")
p_value <- pnorm(z_score, lower.tail = FALSE)

