Databricks-concepten
Kevin Barlow
Data Practitioner
Clusters ontwerpen voor data science- of data engineering-workloads...
import pyspark.sql.functions as F spark_df = (spark .read .table('user_table')) spark_df = (spark_df .withColumn('score', F.flatten(...)) )
is wezenlijk anders dan compute ontwerpen voor SQL-workloads
SELECT * FROM user_table u LEFT JOIN product_use p ON u.userId = p.userId WHERE country = 'USA' AND utilization >= 0.6
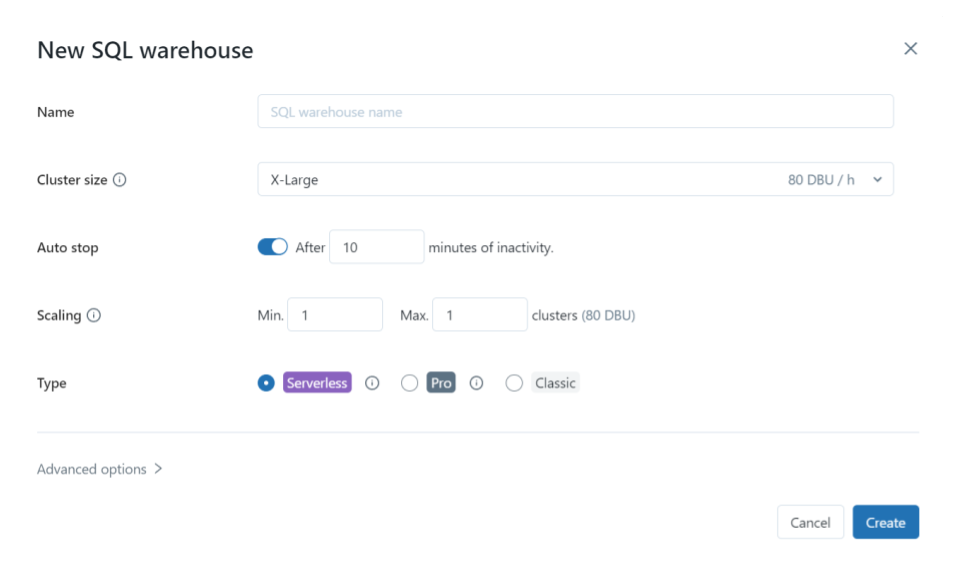
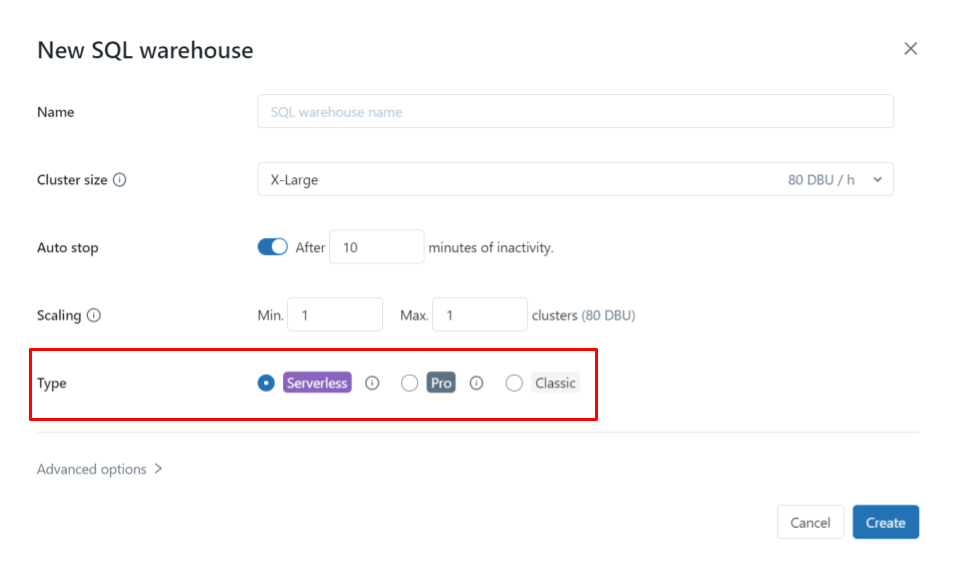
SQL Warehouse-instellingen
Verschillende types, verschillende voordelen
Classic
Pro
Serverless
COPY INTO
COPY INTO my_table FROM '/path/to/files' FILEFORMAT = <format> FORMAT_OPTIONS ('mergeSchema' = 'true') COPY_OPTIONS ('mergeSchema' = 'true');
CREATE <entity> AS
CREATE TABLE events USING DELTA AS ( SELECT * FROM raw_events WHERE ... )