Introductie tot spreadsheets
Gestroomlijnde data-inname met pandas

Amany Mahfouz
Instructor
Spreadsheets laden
- Spreadsheets hebben in
pandaseen eigen laadfunctie:read_excel()
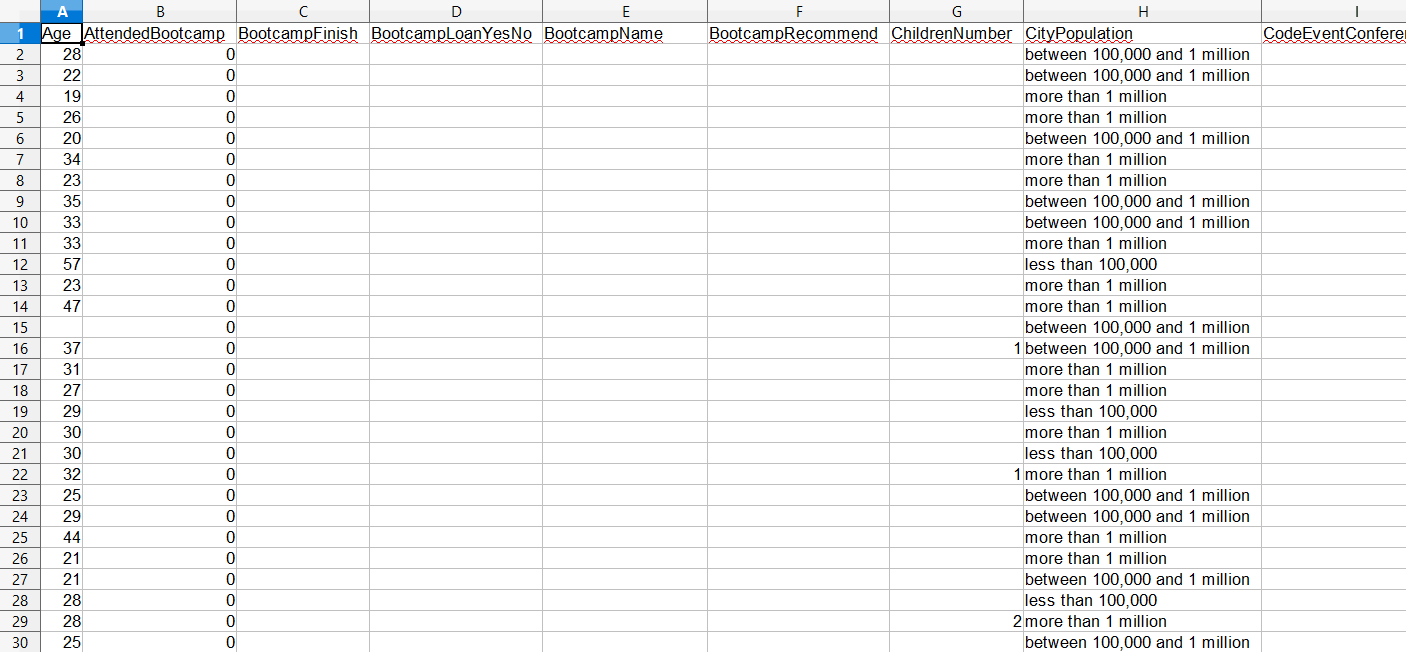
Geselecteerde kolommen en rijen laden
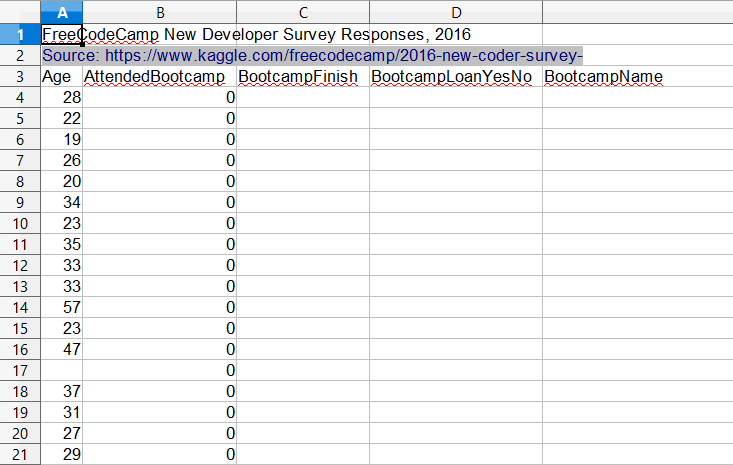
Geselecteerde kolommen en rijen laden


