Uitleg van unsupervised modellen
Explainable AI in Python

Fouad Trad
Machine Learning Engineer
Clustering
Groepeer vergelijkbare datapunten zonder vooraf gedefinieerde labels
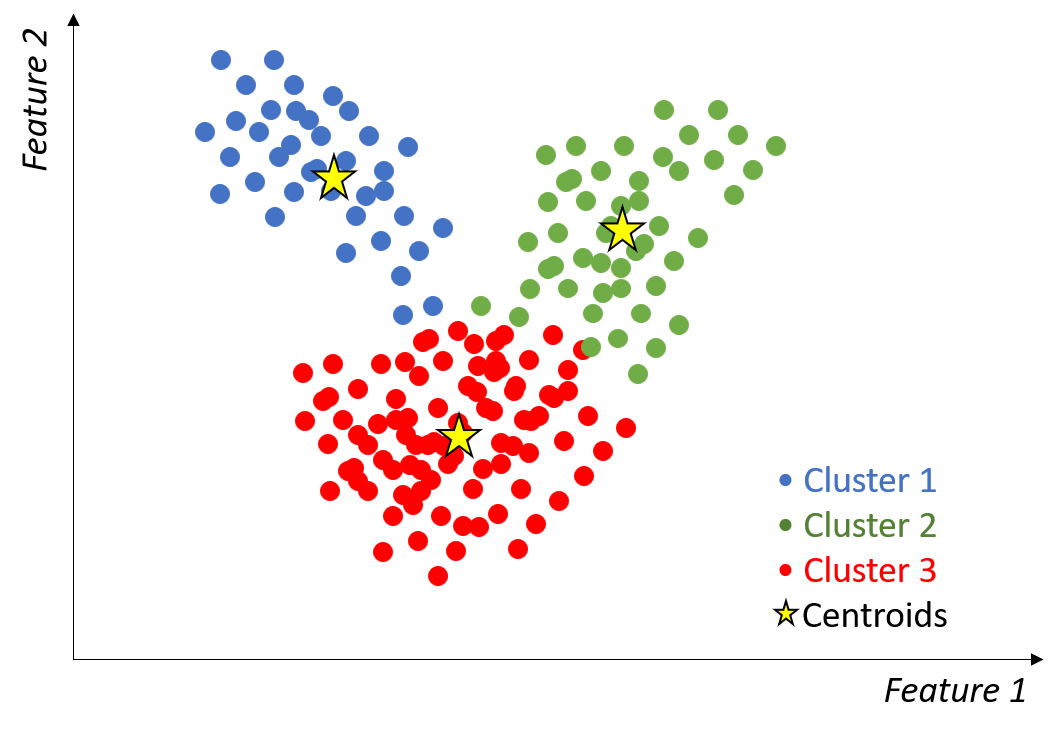
Silhouette-score

Silhouette-score

Invloed van features op clusterkwaliteit

Invloed van features op clusterkwaliteit

Invloed van features op clusterkwaliteit

- $\text{Impact(}f) > 0$ → positieve bijdrage van $f$
- $\text{Impact(}f) < 0$ → $f$ voegt ruis toe
Adjusted Rand Index (ARI)
- Meet hoe goed clusterindelingen overeenkomen

- Maximale ARI = 1 → perfecte clusterovereenkomst
Adjusted Rand Index (ARI)
- Meet hoe goed clusterindelingen overeenkomen
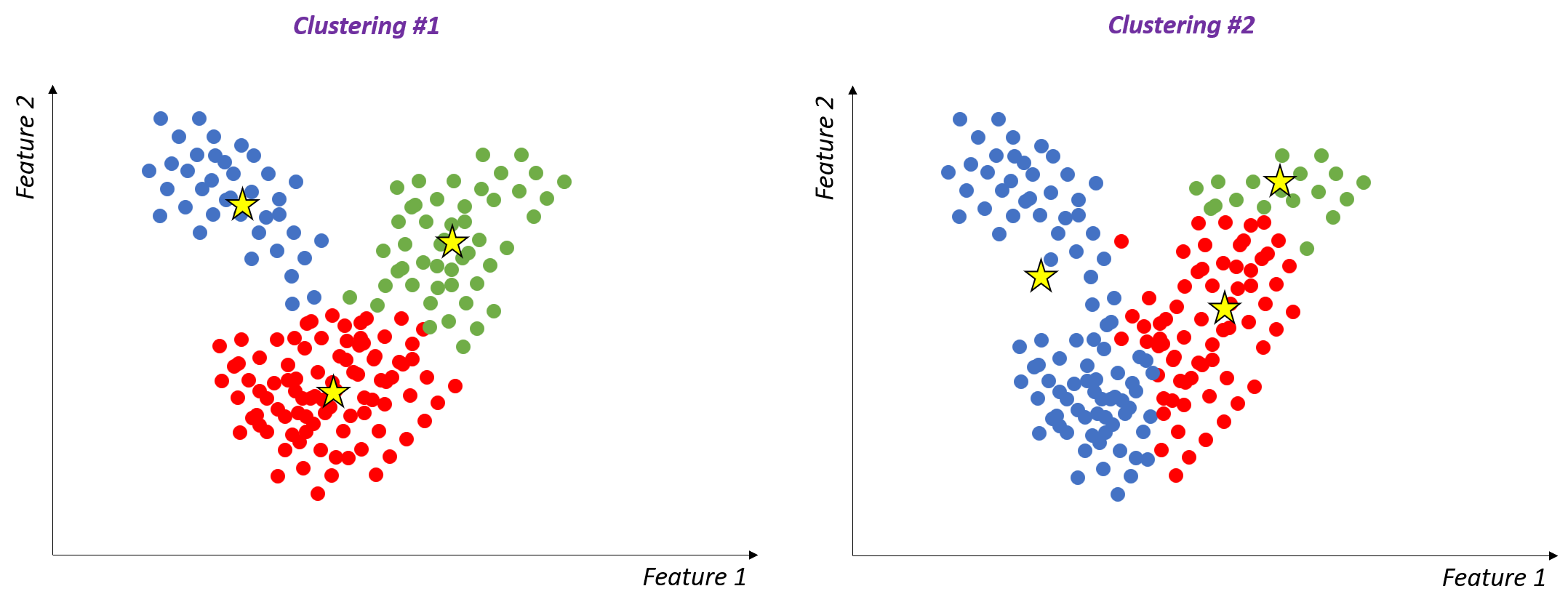
- Maximale ARI = 1 → perfecte clusterovereenkomst
- Lagere ARI → grotere verschillen tussen clusterings

