Steekproeven en puntschattingen
Steekproeven in R

Richie Cotton
Data Evangelist at DataCamp
De bevolking van Frankrijk schatten
Er wonen veel mensen in Frankrijk
Huishoudens steekproeven
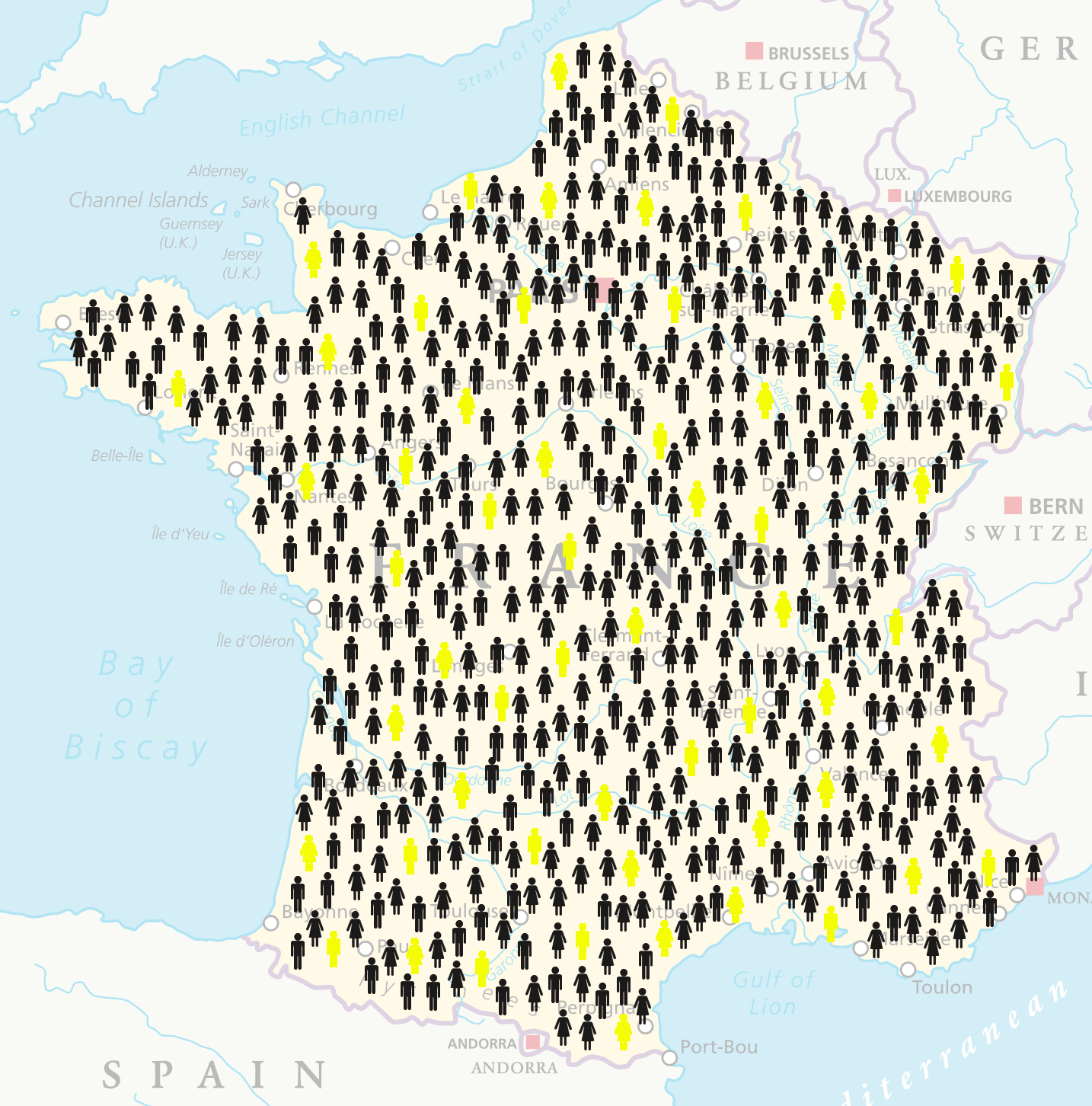
Steekproeven in R
Richie Cotton
Data Evangelist at DataCamp

