Overzicht van tekstclassificatie
Deep Learning voor tekst met PyTorch

Shubham Jain
Instructor
Wat is tekstclassificatie
- Labels toekennen aan tekst
- Woorden en zinnen betekenis geven
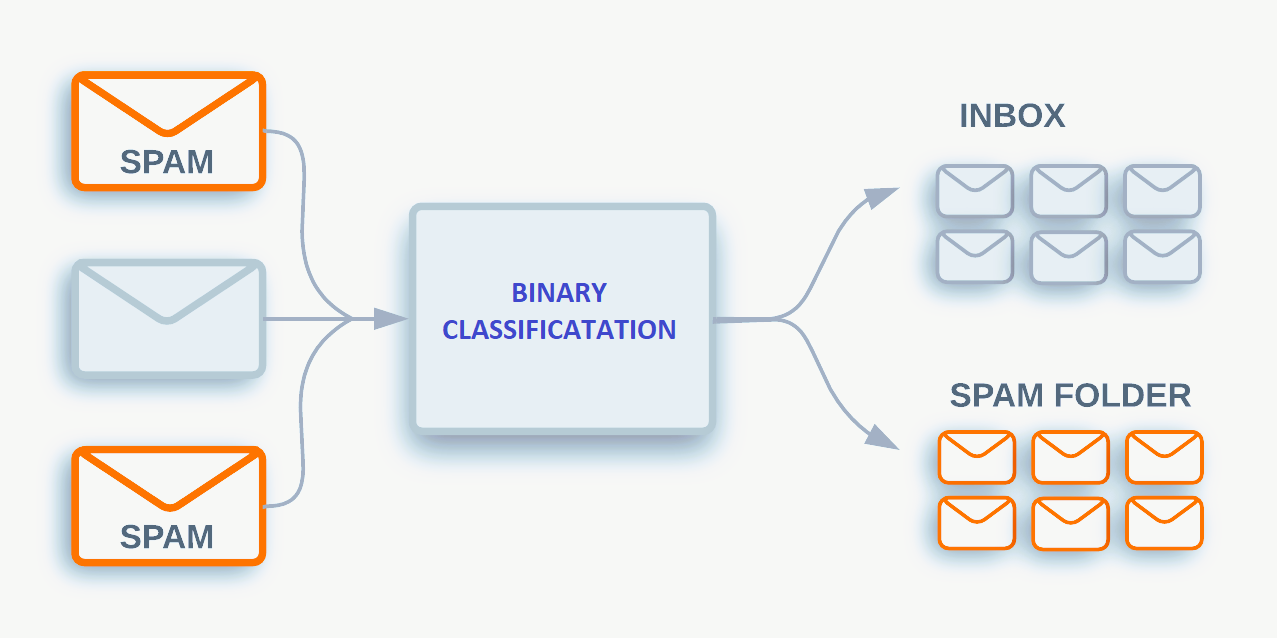
Binaire classificatie
1 https://storage.googleapis.com/gweb-cloudblog-publish/images/image4_v2LFcq0.max-1200x1200.png
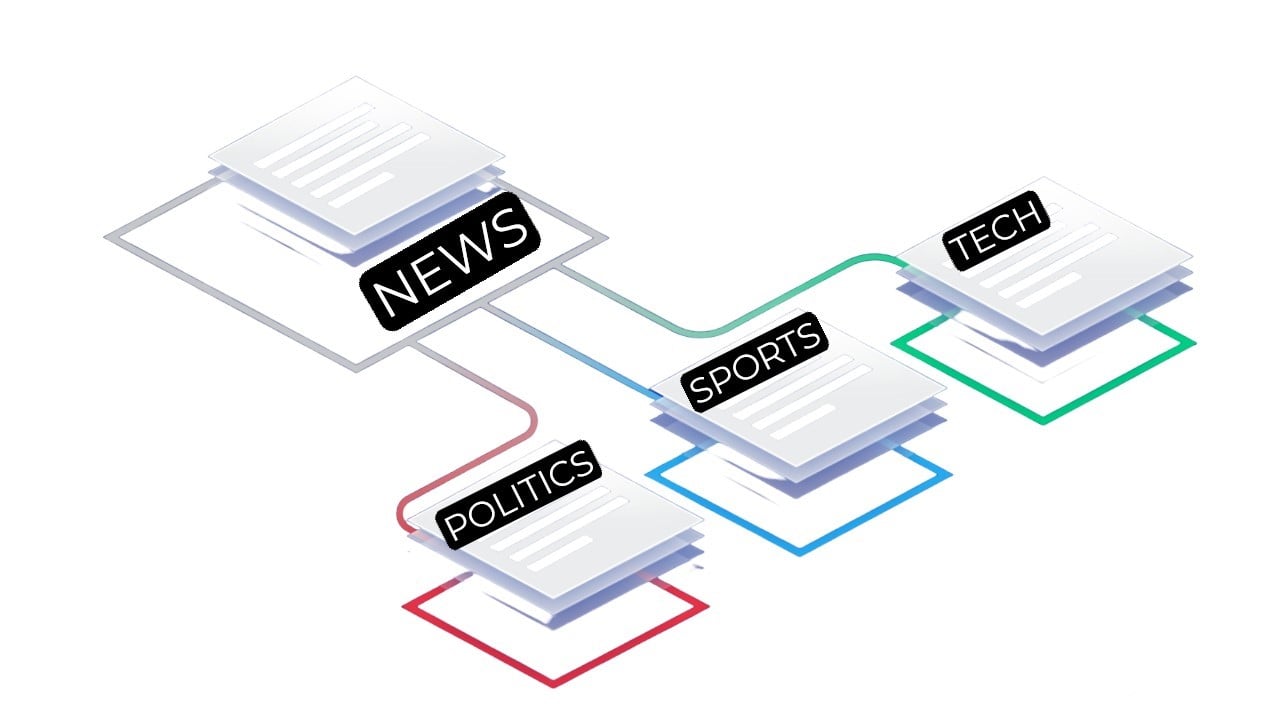
Multi-classclassificatie
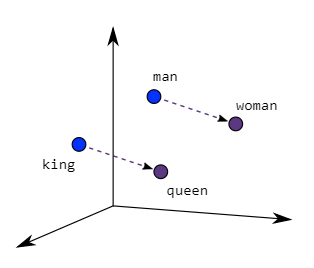
Wat zijn woordembeddings