Tekstdata encoderen
Deep Learning voor tekst met PyTorch

Shubham Jain
Data Scientist
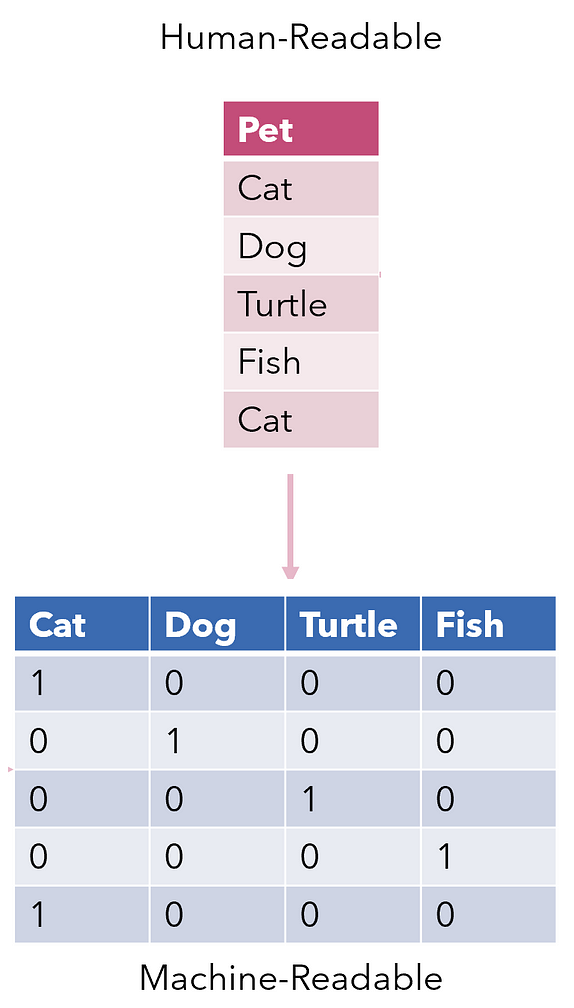
Tekstcodering

- Zet tekst om in machineleesbare getallen
- Maakt analyse en modellering mogelijk
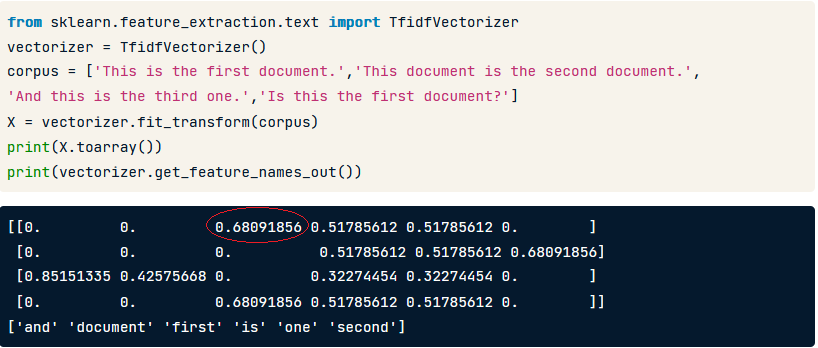
TfidfVectorizer
Deep Learning voor tekst met PyTorch
Shubham Jain
Data Scientist

