Adversariële aanvallen op tekstclassificatiemodellen
Deep Learning voor tekst met PyTorch

Shubham Jain
Instructor
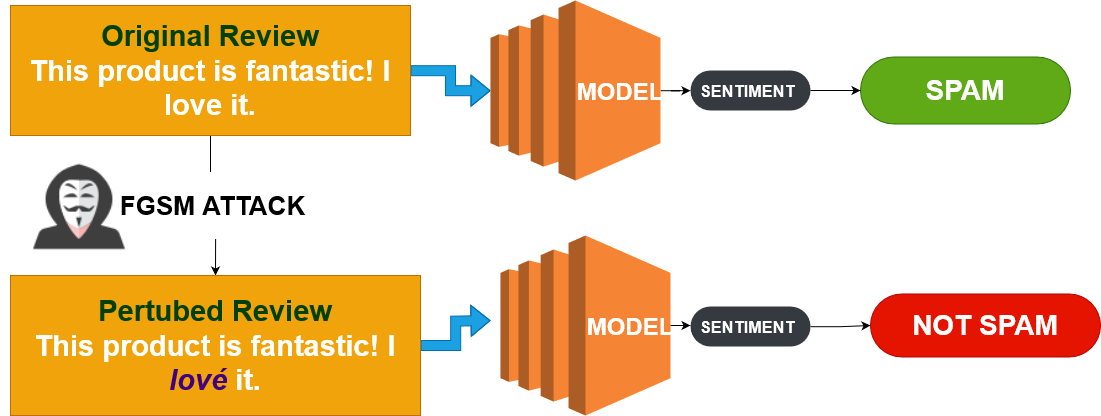
Fast Gradient Sign Method (FGSM)
- Misbruikt wat het model heeft geleerd
- Maakt minimale aanpassing om te misleiden
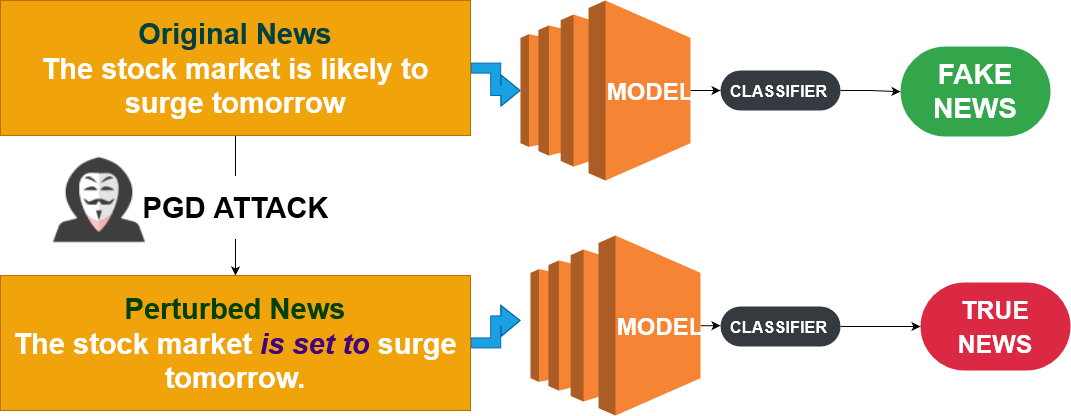
Projected Gradient Descent (PGD)
- Geavanceerder dan FGSM: iteratief
- Zoekt de meest effectieve verstoring
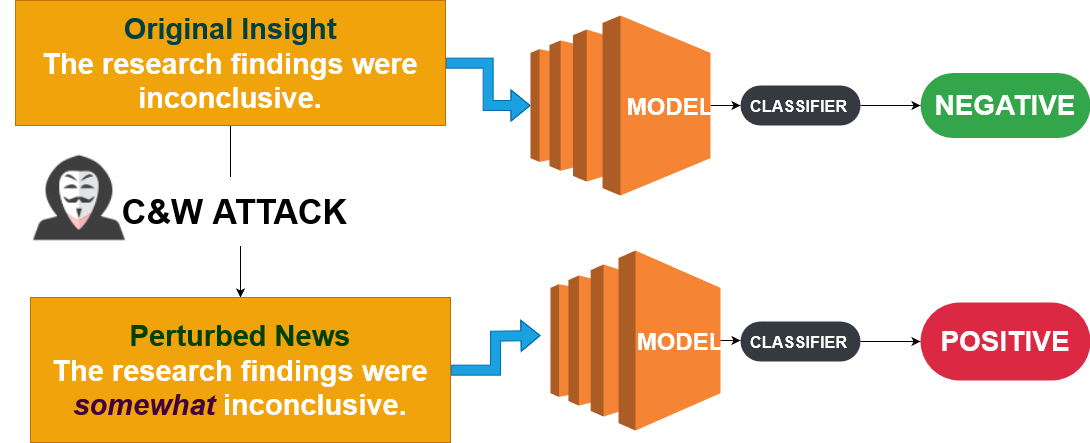
De Carlini & Wagner (C&W)-aanval
- Richt zich op het optimaliseren van de verliesfunctie
- Niet alleen misleiden, maar ook ondetecteerbaar zijn
Verdedigingen opbouwen: strategieën
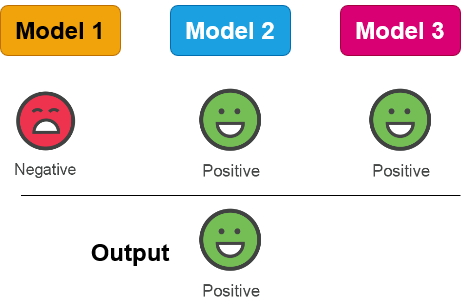
Verdedigingen opbouwen: tools en technieken


1 https://adversarial-robustness-toolbox.readthedocs.io/en/latest/, https://stock.adobe.com/ie/contributor/209161356/designer-s-circle

