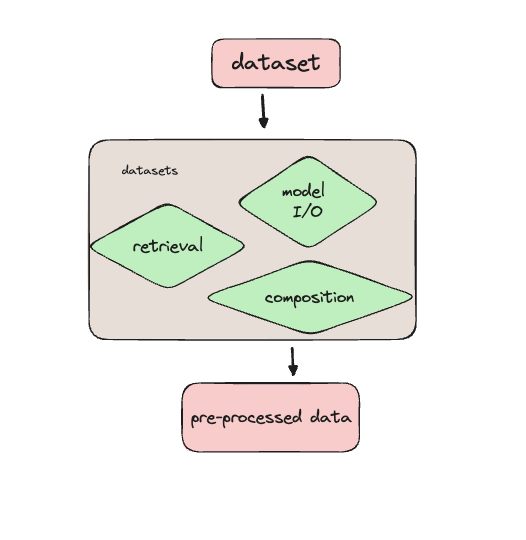
Data preprocessen voor fine-tuning
Fijn-afstemmen met Llama 3

Francesca Donadoni
Curriculum Manager, DataCamp
Datasets gebruiken voor fine-tuning
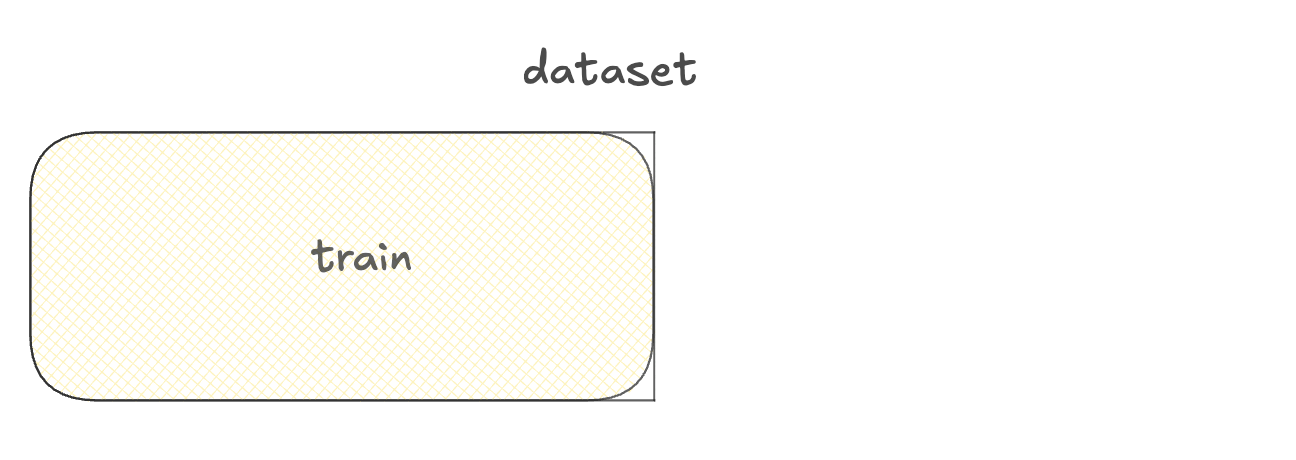
Datasets gebruiken voor fine-tuning
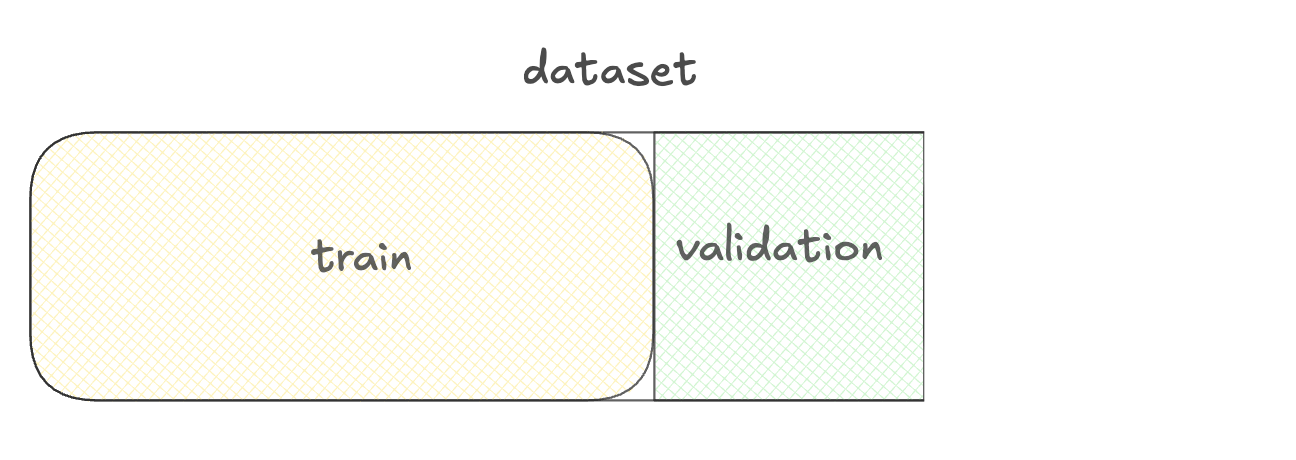
Datasets gebruiken voor fine-tuning
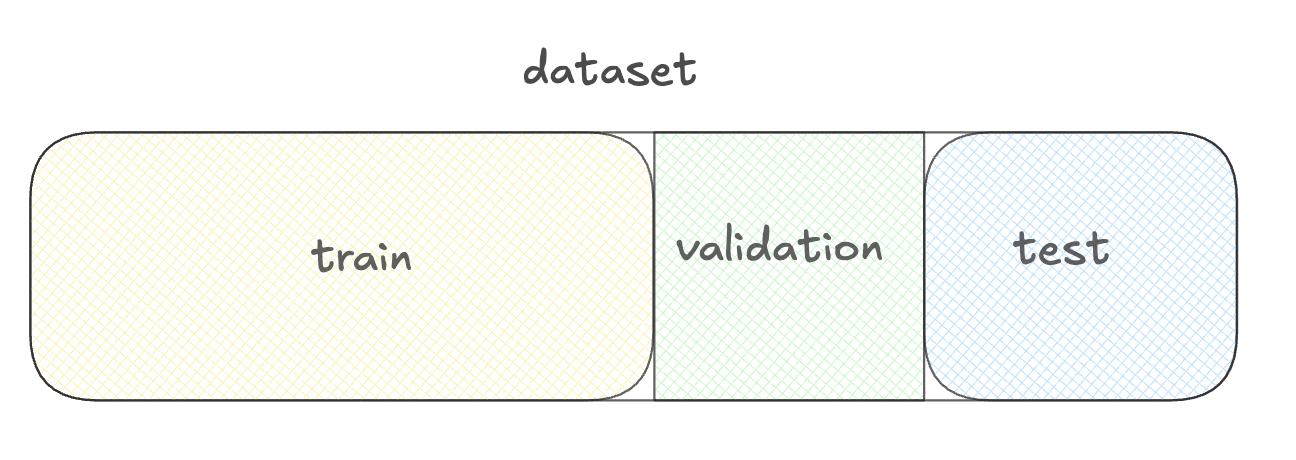
Data voorbereiden met de datasets-bibliotheek