Introductie tot deep Q-learning
Deep Reinforcement Learning in Python

Timothée Carayol
Principal Machine Learning Engineer, Komment
Wat is Deep Q-learning?
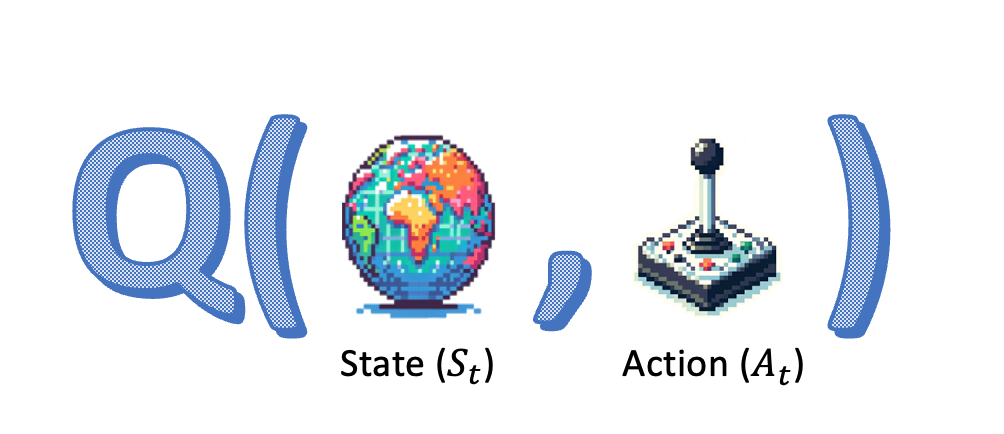
Q-learning opfrissen

Q-learning opfrissen


- Bellman-vergelijking: recursieve formule voor $Q$
- Rechterkant van de Bellman-vergelijking: "TD-target"
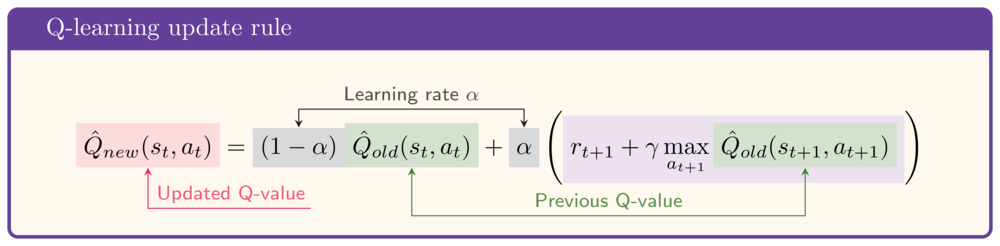
- Gebruik TD-target uit de Bellman-vergelijking om $\hat{Q}$ na elke stap bij te werken
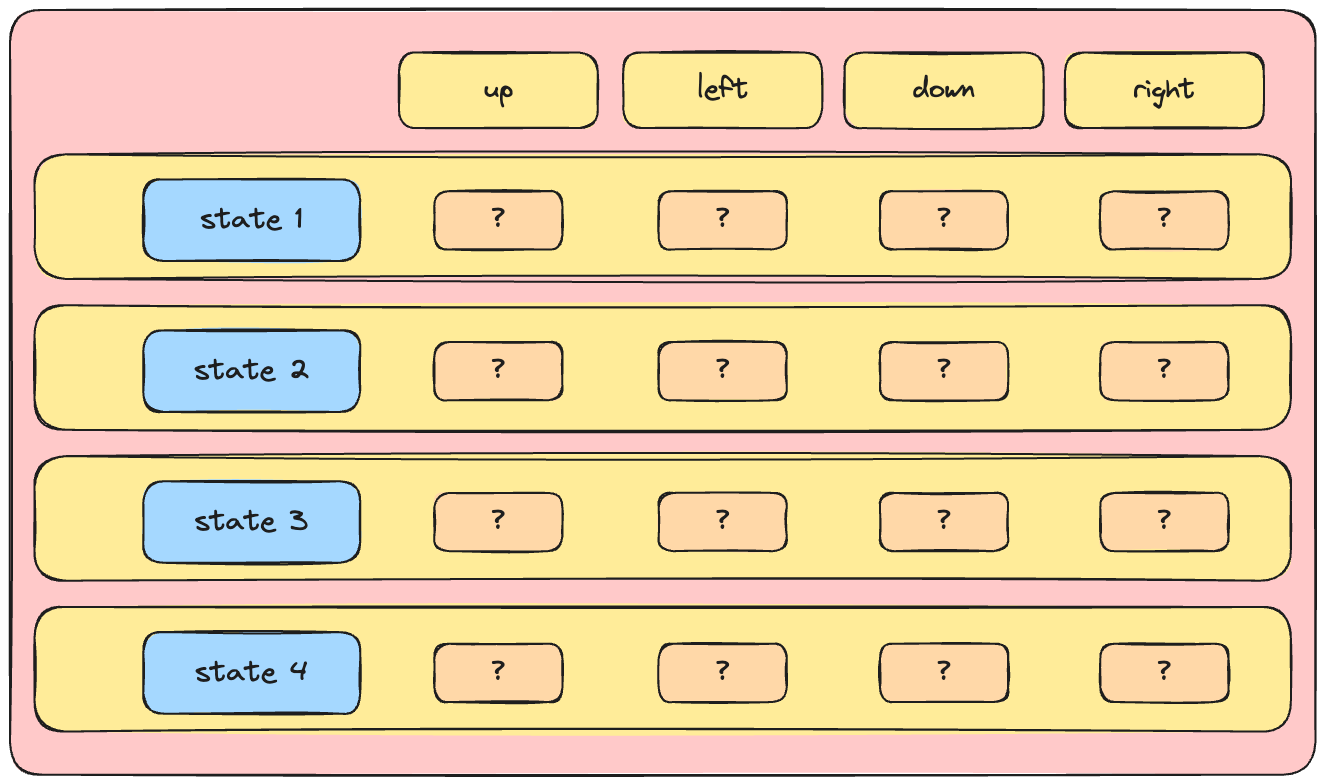
Het Q-netwerk
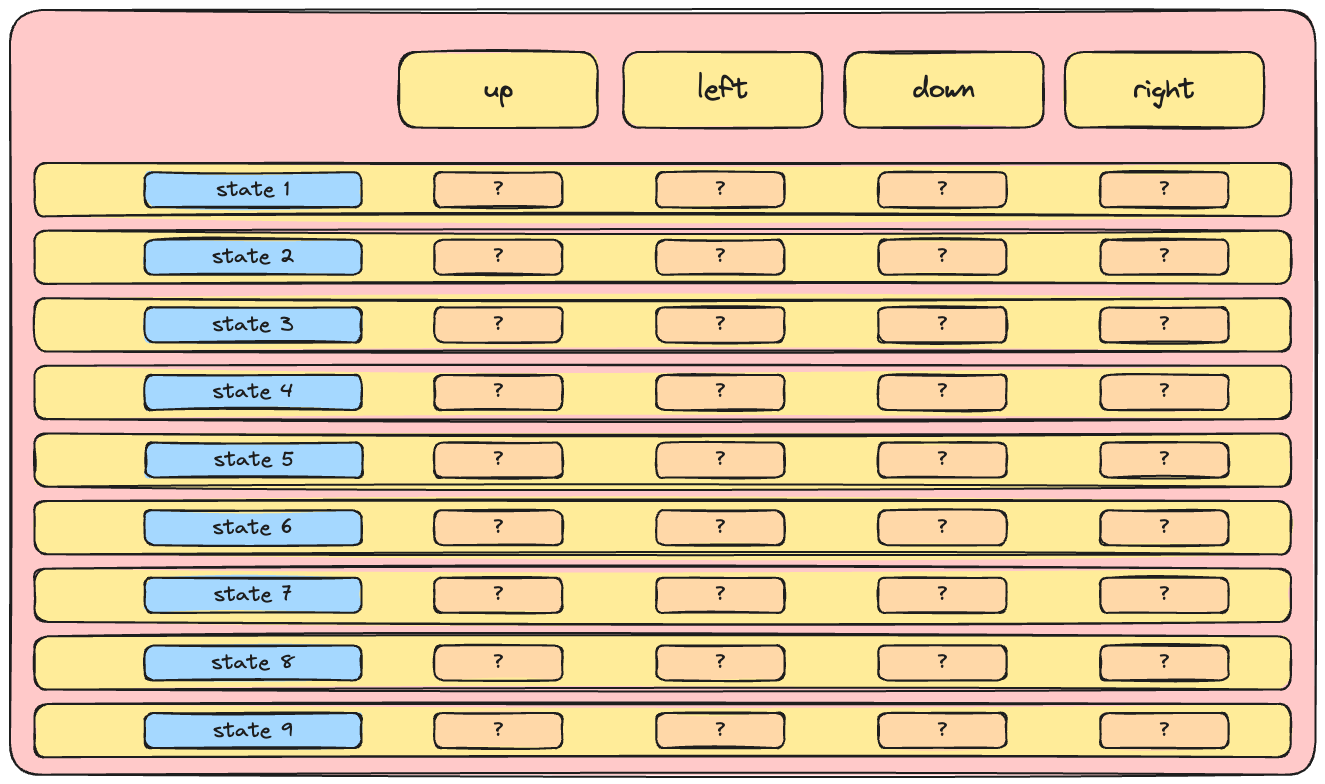
Het Q-netwerk
Het Q-netwerk
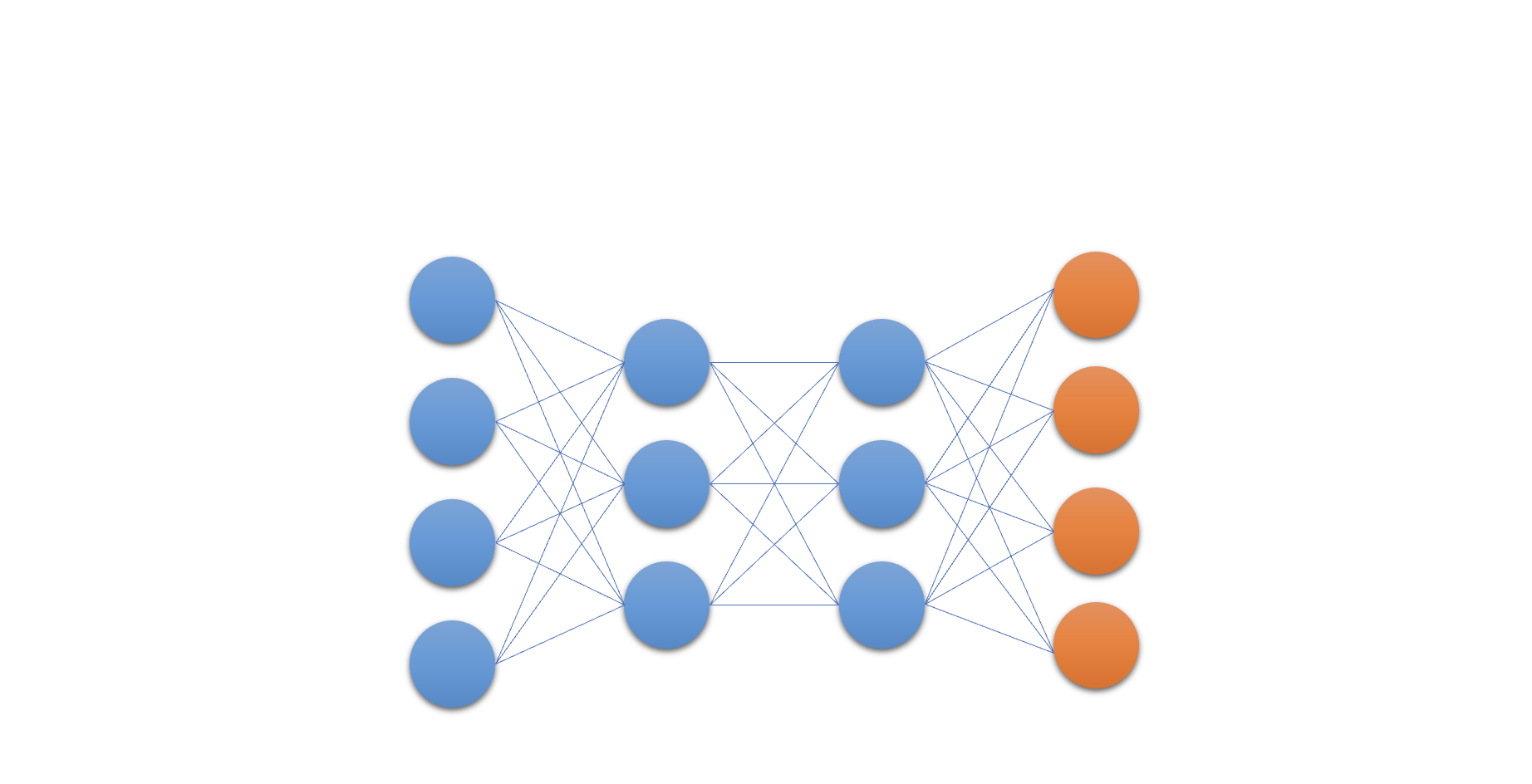
Het Q-netwerk
- De kern van Deep Q-learning: een neuraal netwerk
Het Q-netwerk
- De kern van Deep Q-learning: een neuraal netwerk
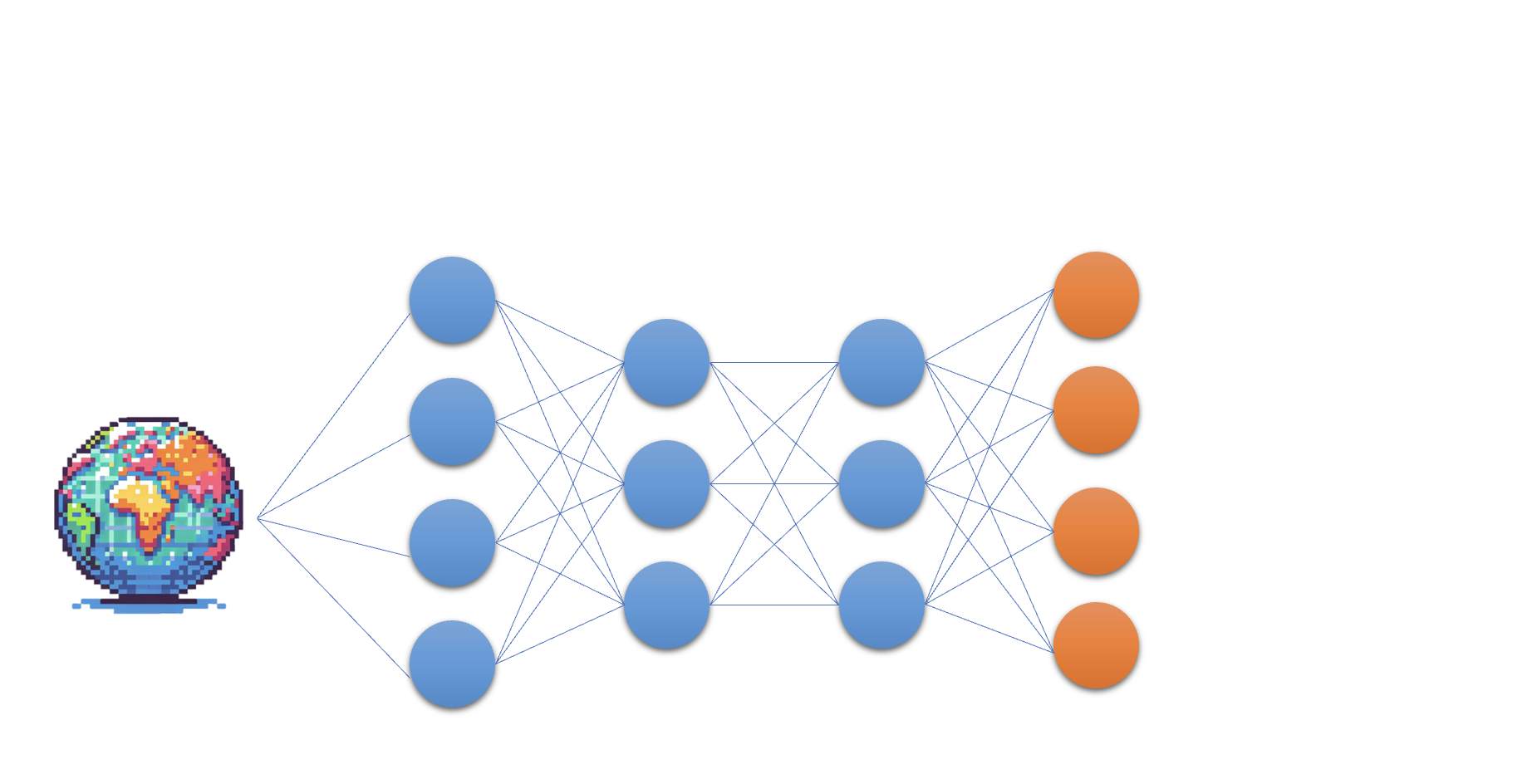
Het Q-netwerk
- De kern van Deep Q-learning: een neuraal netwerk dat toestand naar Q-waarden mappt
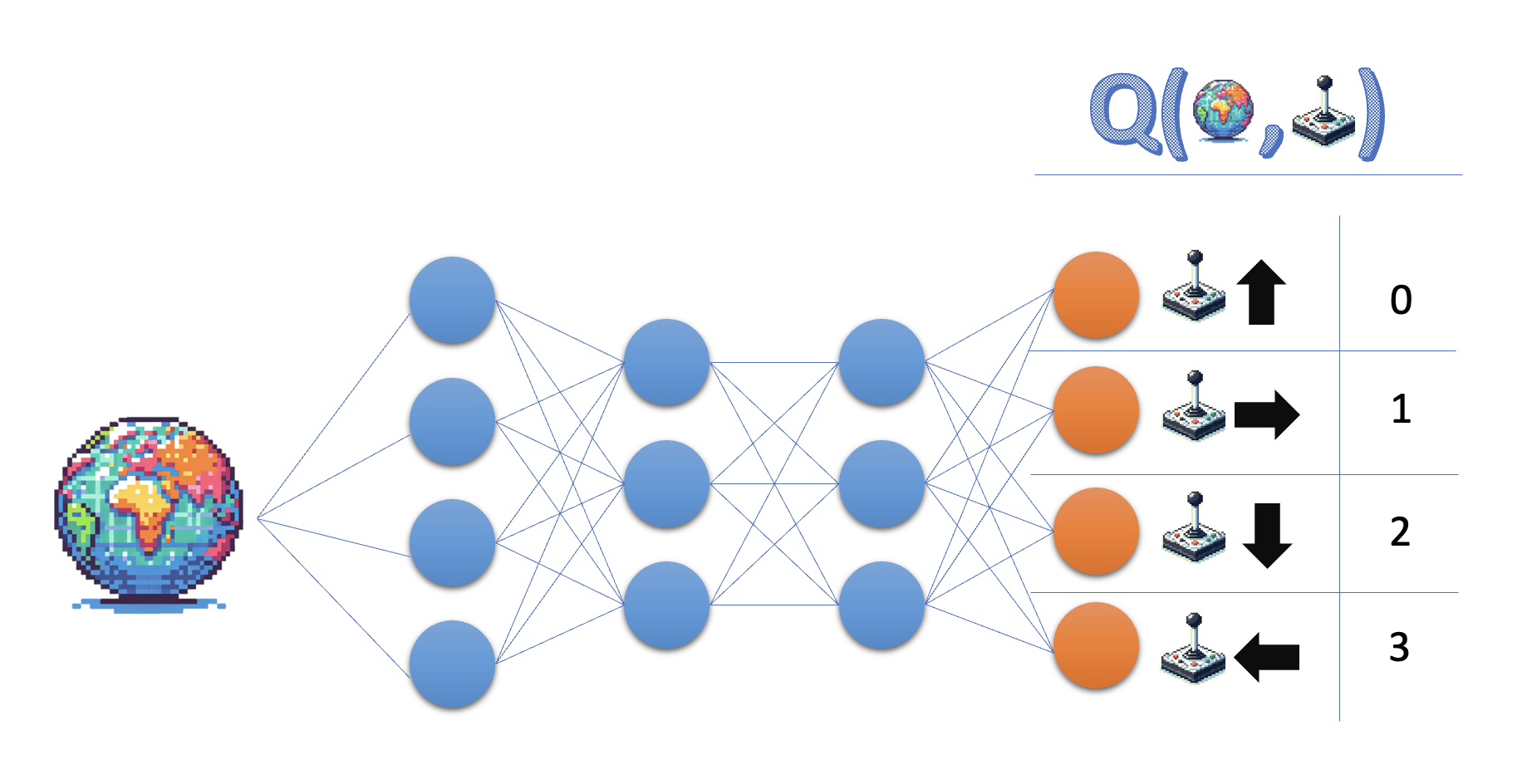
- Een netwerk dat de actie-waardefunctie benadert heet een 'Q-netwerk'
- Q-netwerken worden vaak gebruikt in Deep Q-learning-algoritmen, zoals DQN.

