Hyperparameteroptimalisatie met Optuna
Deep Reinforcement Learning in Python

Timothée Carayol
Principal Machine Learning Engineer, Komment
Hoe kies je hyperparametervaarden


Optuna-werkwijze:
- Definieer een doelfunctie
- Maak een Optuna
studyaan - Laat Optuna over trials itereren
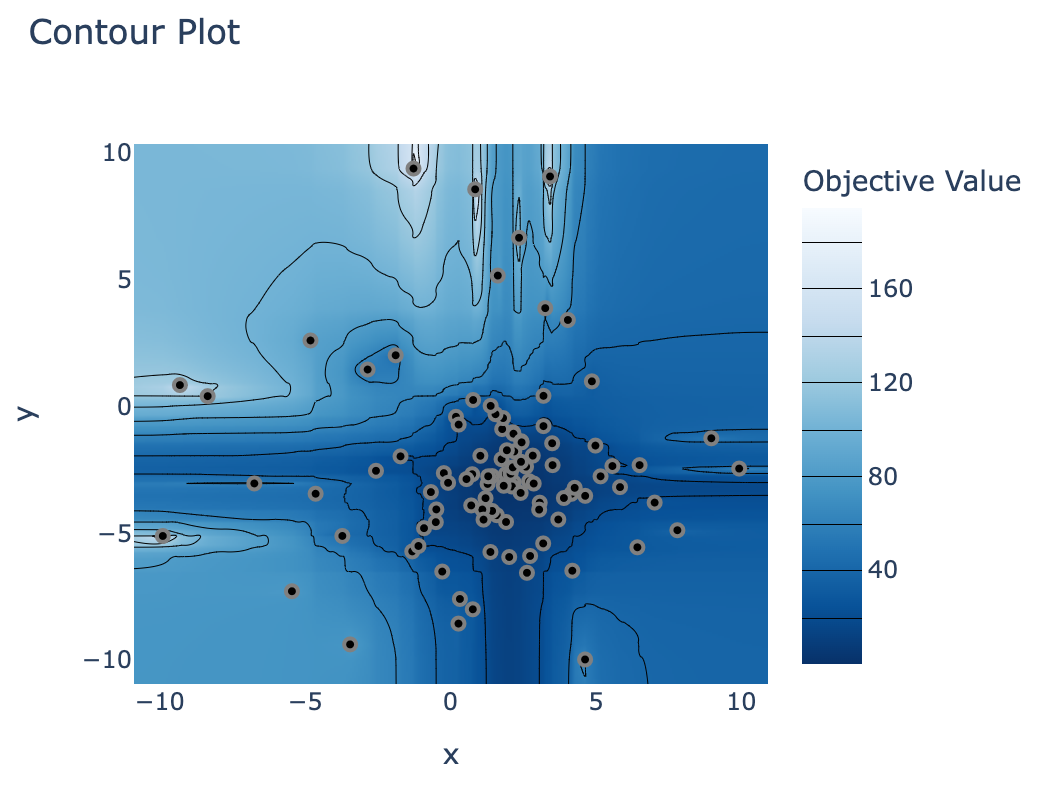
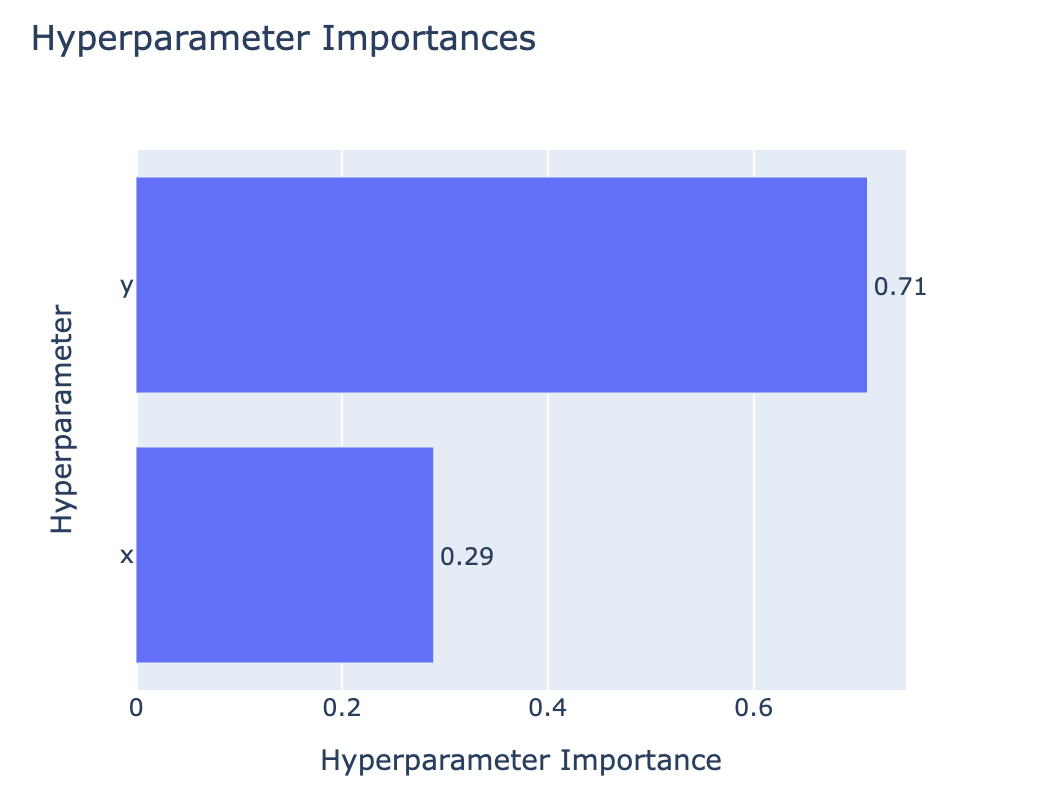
De studieresultaten verkennen
optuna.visualization.plot_param_importances(study)
optuna.visualization.plot_contour(study)