Het complete DQN-algoritme
Deep Reinforcement Learning in Python

Timothée Carayol
Principal Machine Learning Engineer, Komment
Het DQN-algoritme


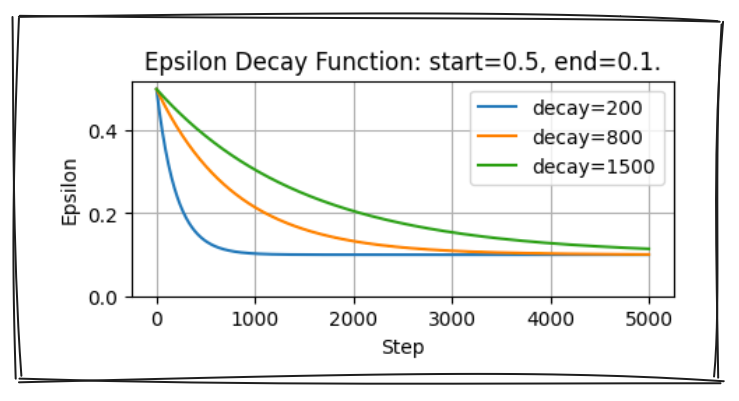
Epsilon-greediness in het DQN-algoritme
- $\varepsilon = end + (start-end) \cdot e^{-\frac{step}{decay}}$
- Neem een willekeurige actie met kans $\varepsilon$
- Neem de hoogste waarde-actie met kans $1 - \varepsilon$
Fixed Q-targets

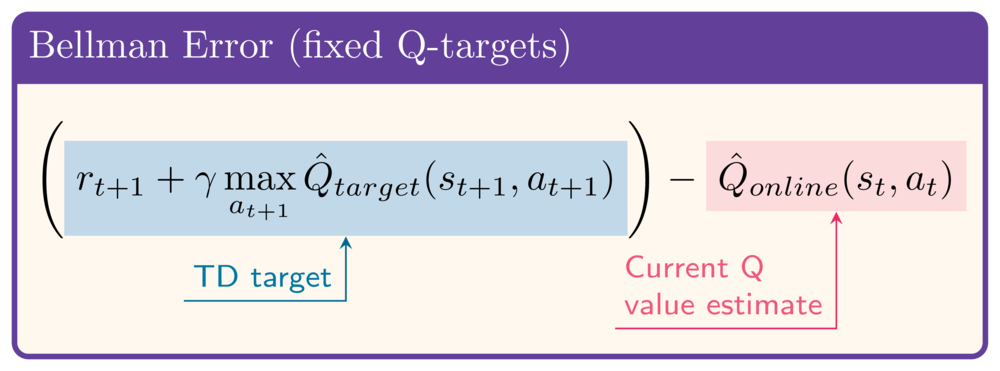
Fixed Q-targets implementeren
- Initieel: Online Network = Target Network
- De state dict van een netwerk bevat alle gewichten:

- Elke stap komen alle gewichten van Target Network iets dichter bij Online Network

