Batch-updates bij policy gradient
Deep Reinforcement Learning in Python

Timothée Carayol
Principal Machine Learning Engineer, Komment
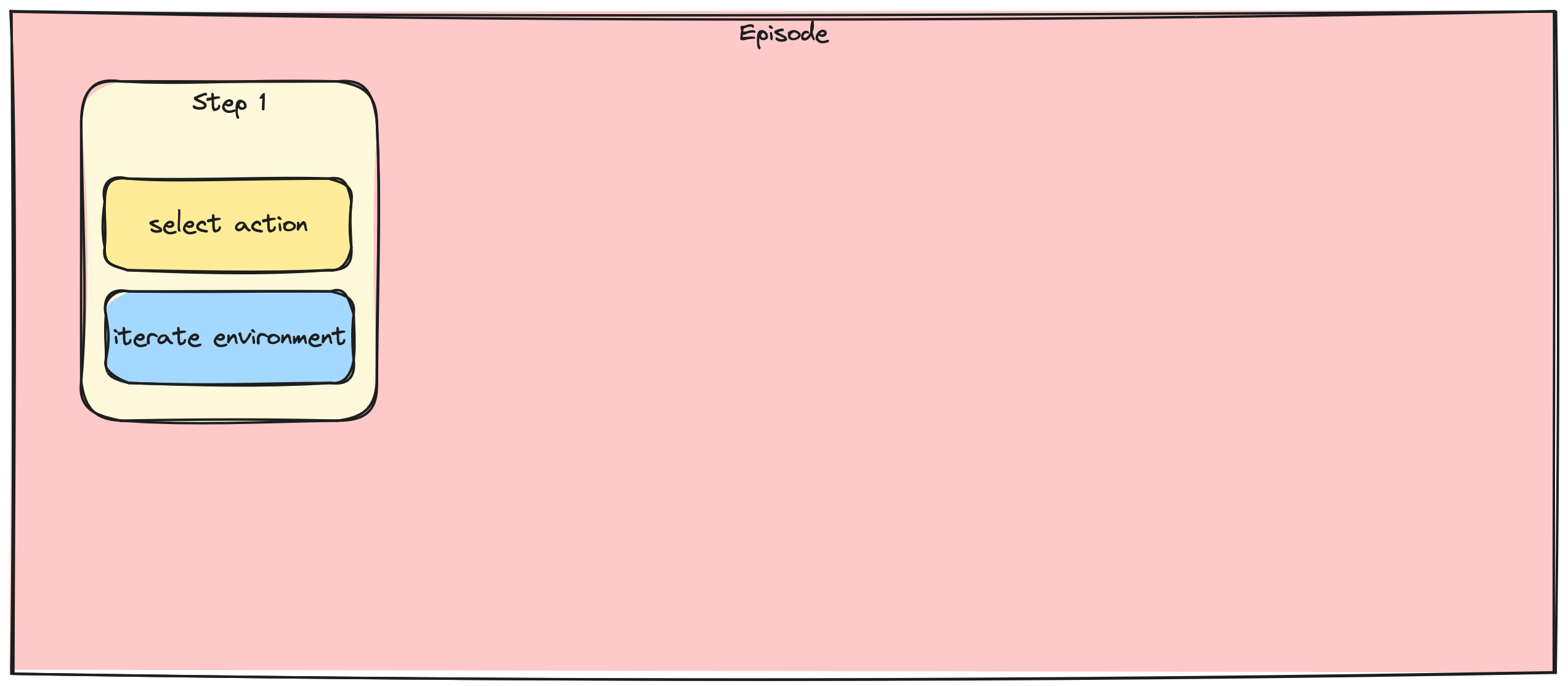
Stapsgewijze vs. batch-gradientupdates

Stapsgewijze vs. batch-gradientupdates

Stapsgewijze vs. batch-gradientupdates
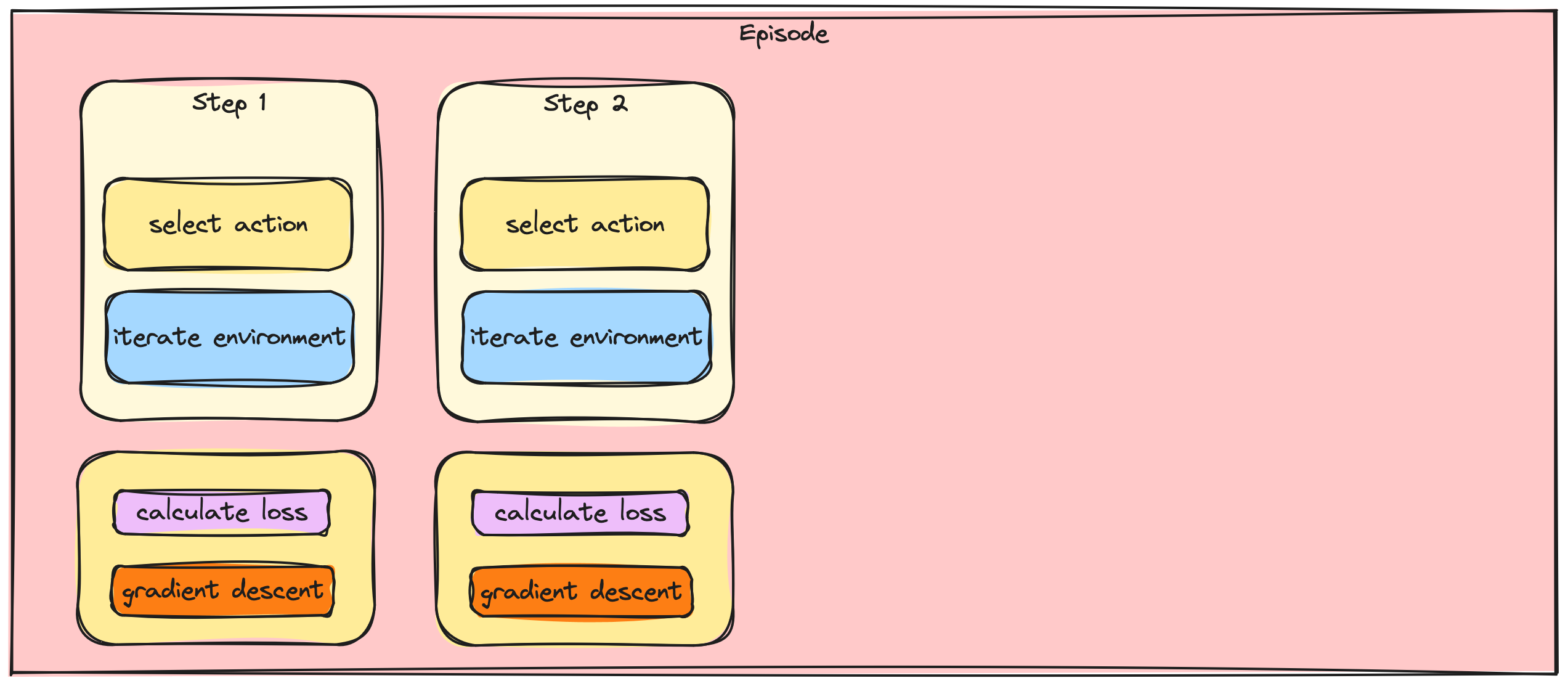
Stapsgewijze vs. batch-gradientupdates

Stapsgewijze vs. batch-gradientupdates
Stapsgewijze vs. batch-gradientupdates
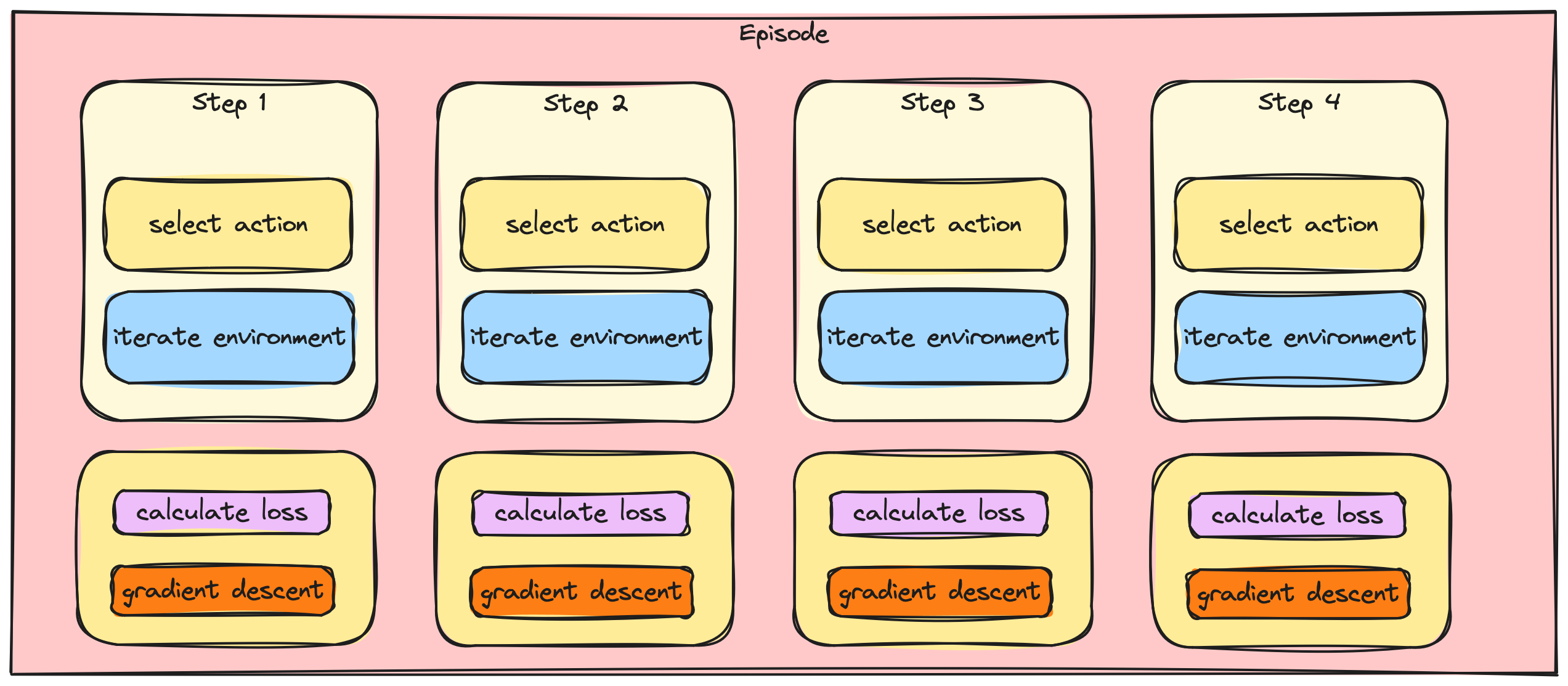
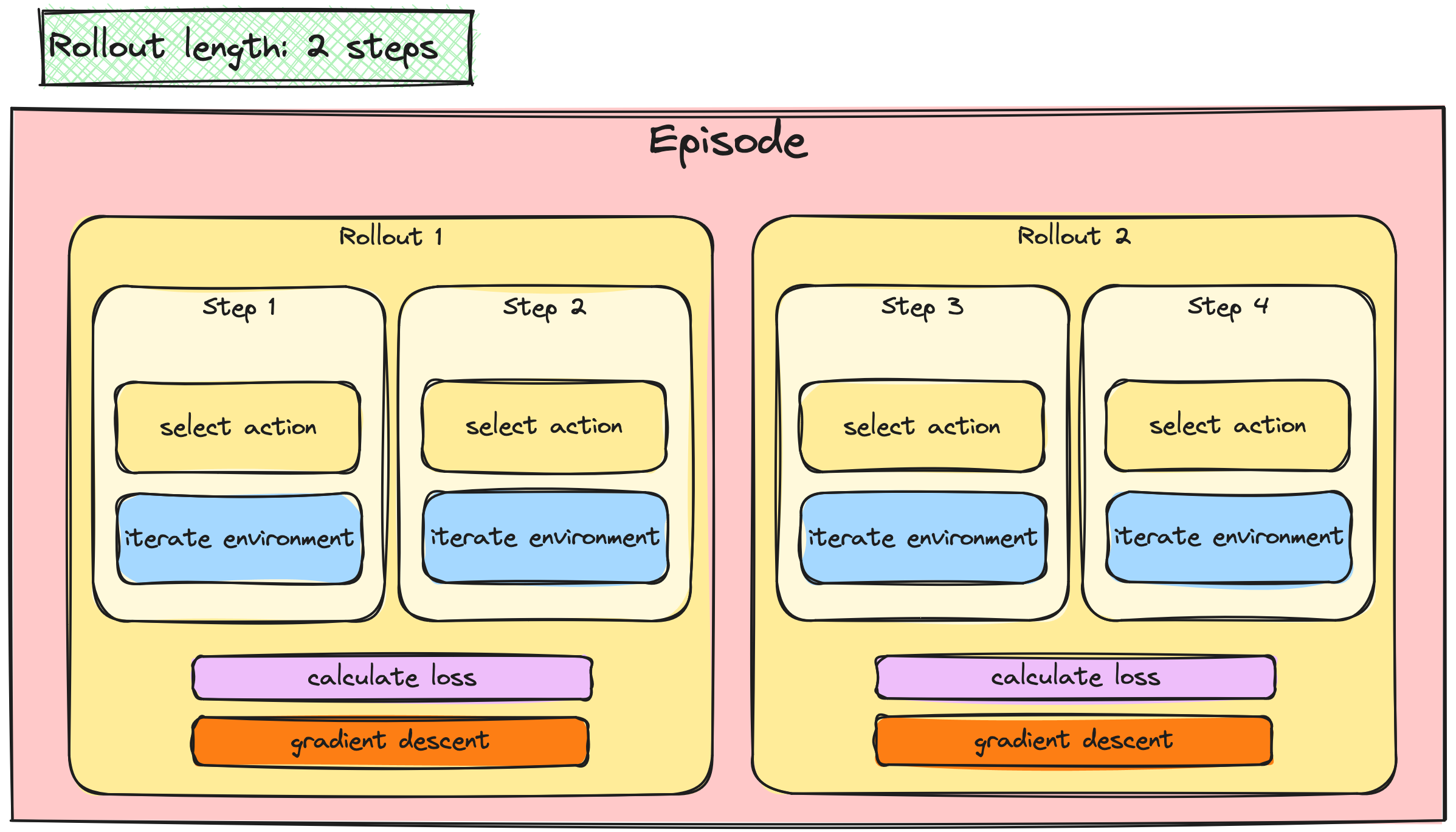
Batchen van A2C-/PPO-updates
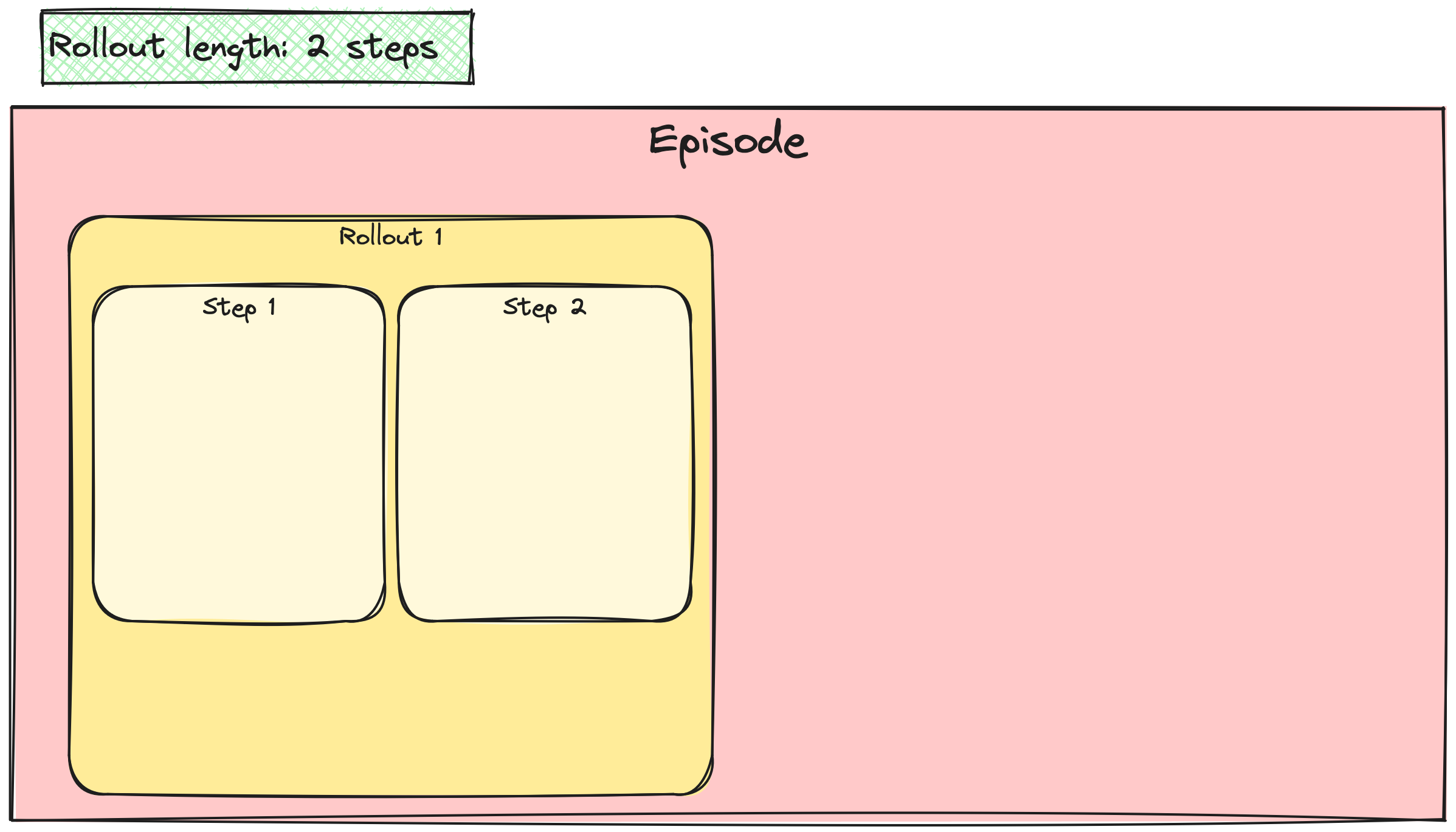
Batchen van A2C-/PPO-updates
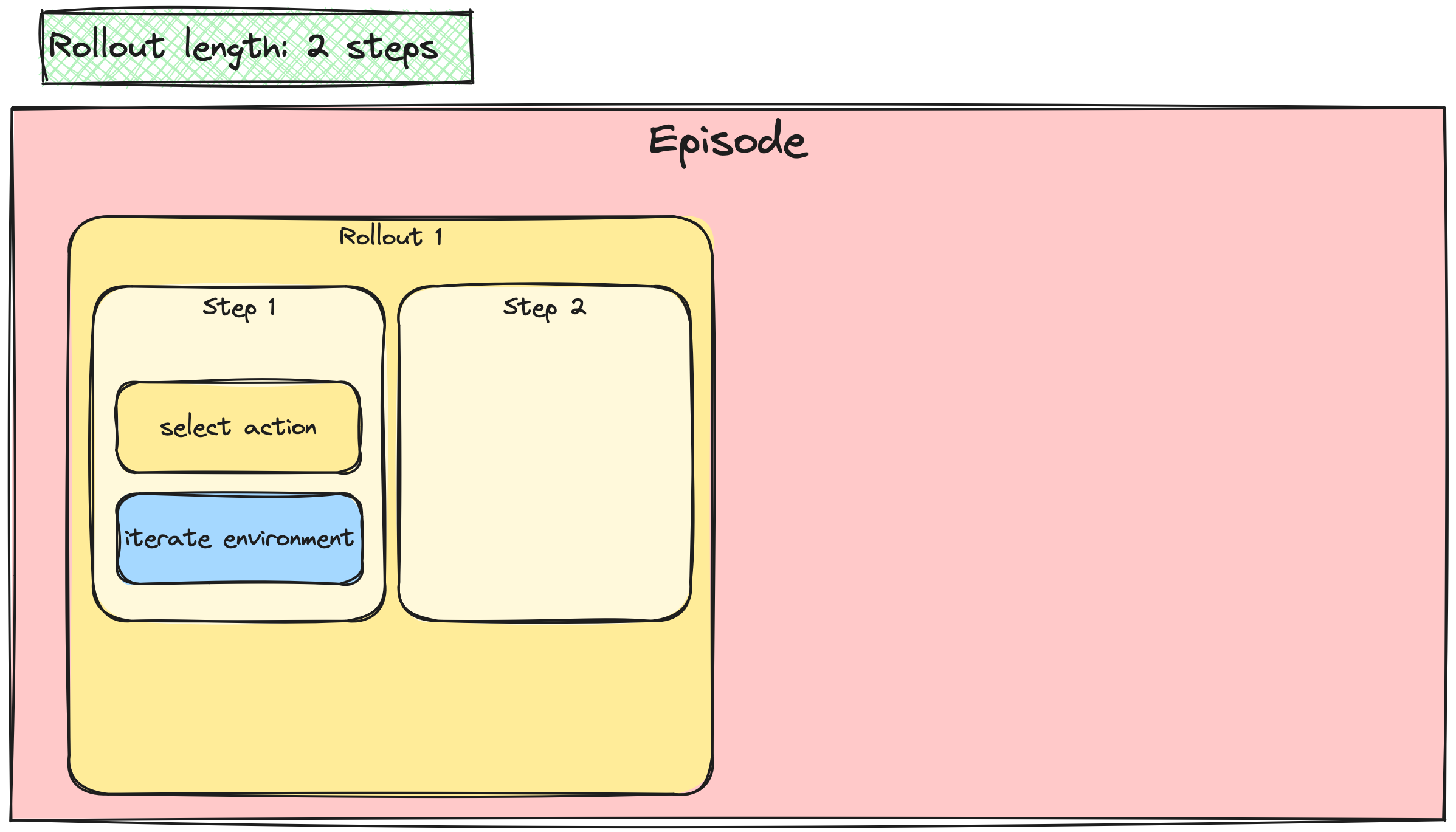
Batchen van A2C-/PPO-updates
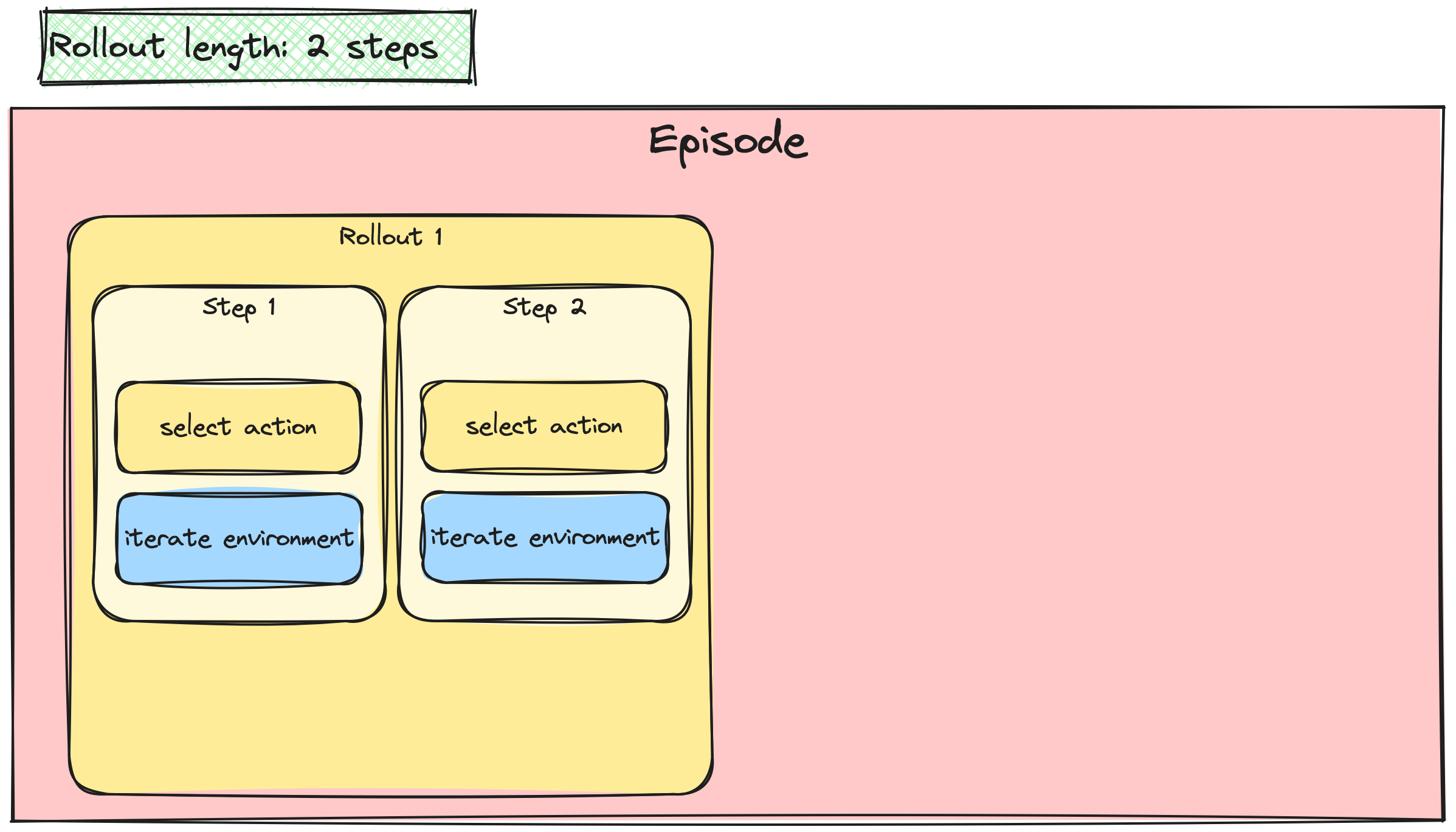
Batchen van A2C-/PPO-updates
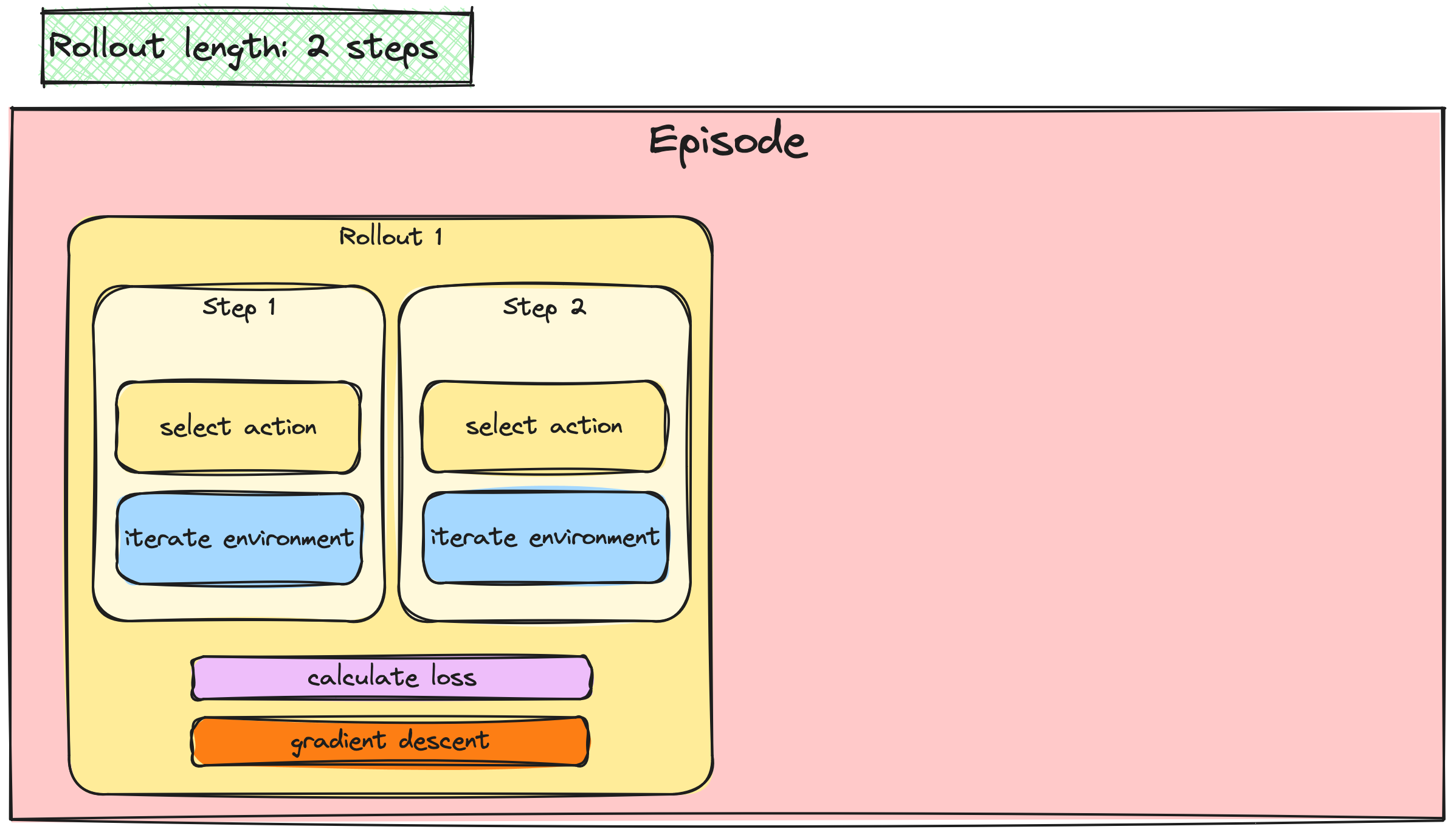
Batchen van A2C-/PPO-updates
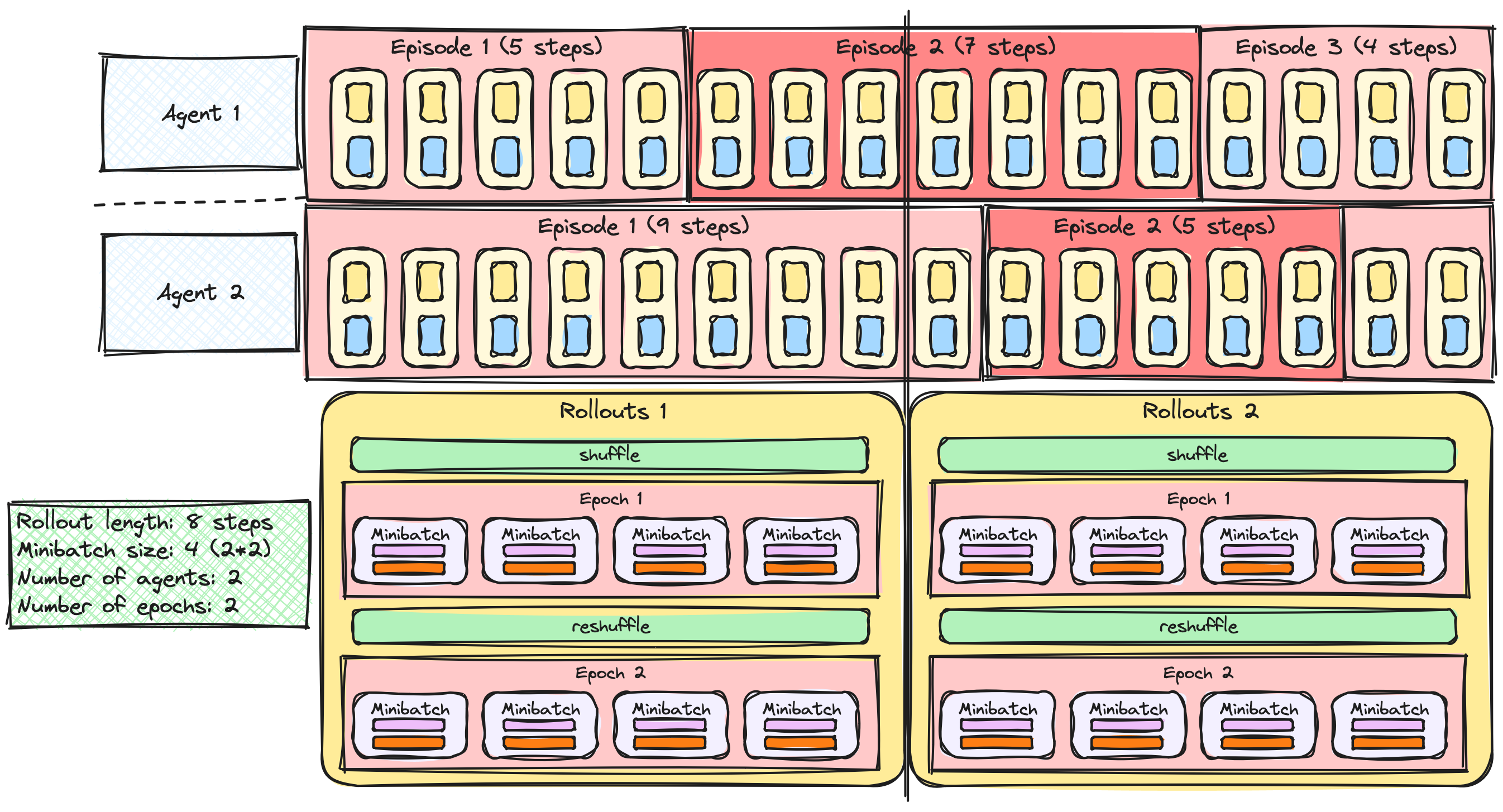
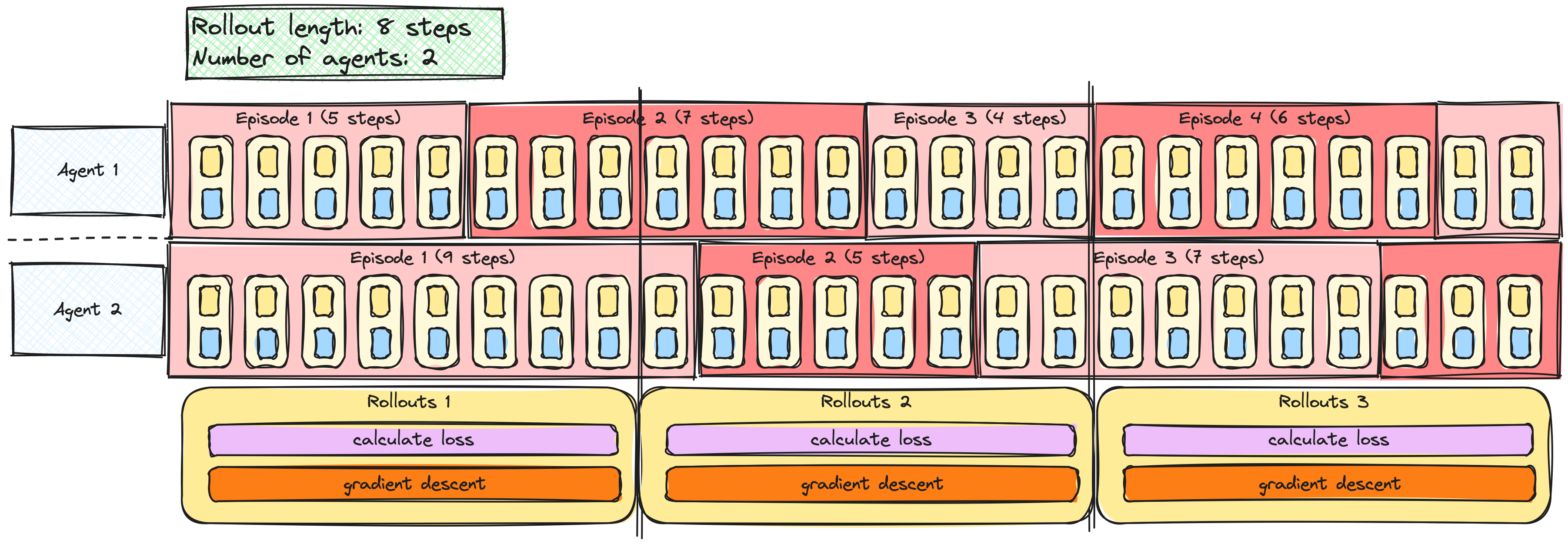
A2C/PPO met meerdere agents
Rollouts en minibatches
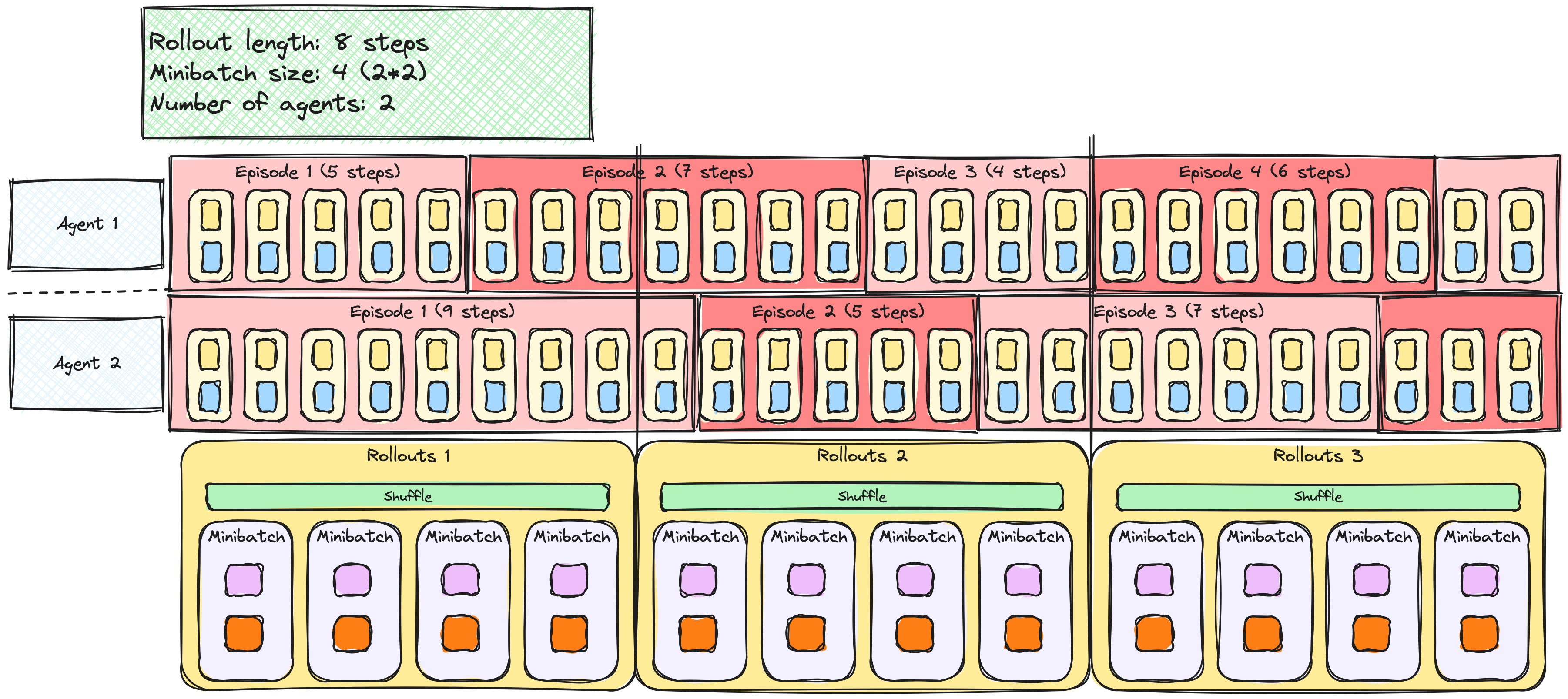
PPO met meerdere epochs