Double DQN
Deep Reinforcement Learning in Python

Timothée Carayol
Principal Machine Learning Engineer, Komment
Double Q-learning
- Q-learning overschat Q-waarden, wat leren minder efficiënt maakt
- Oorzaak: maximisatiebias
- Double Q-learning verwijdert bias door actiekeuze en waardeschatting te scheiden
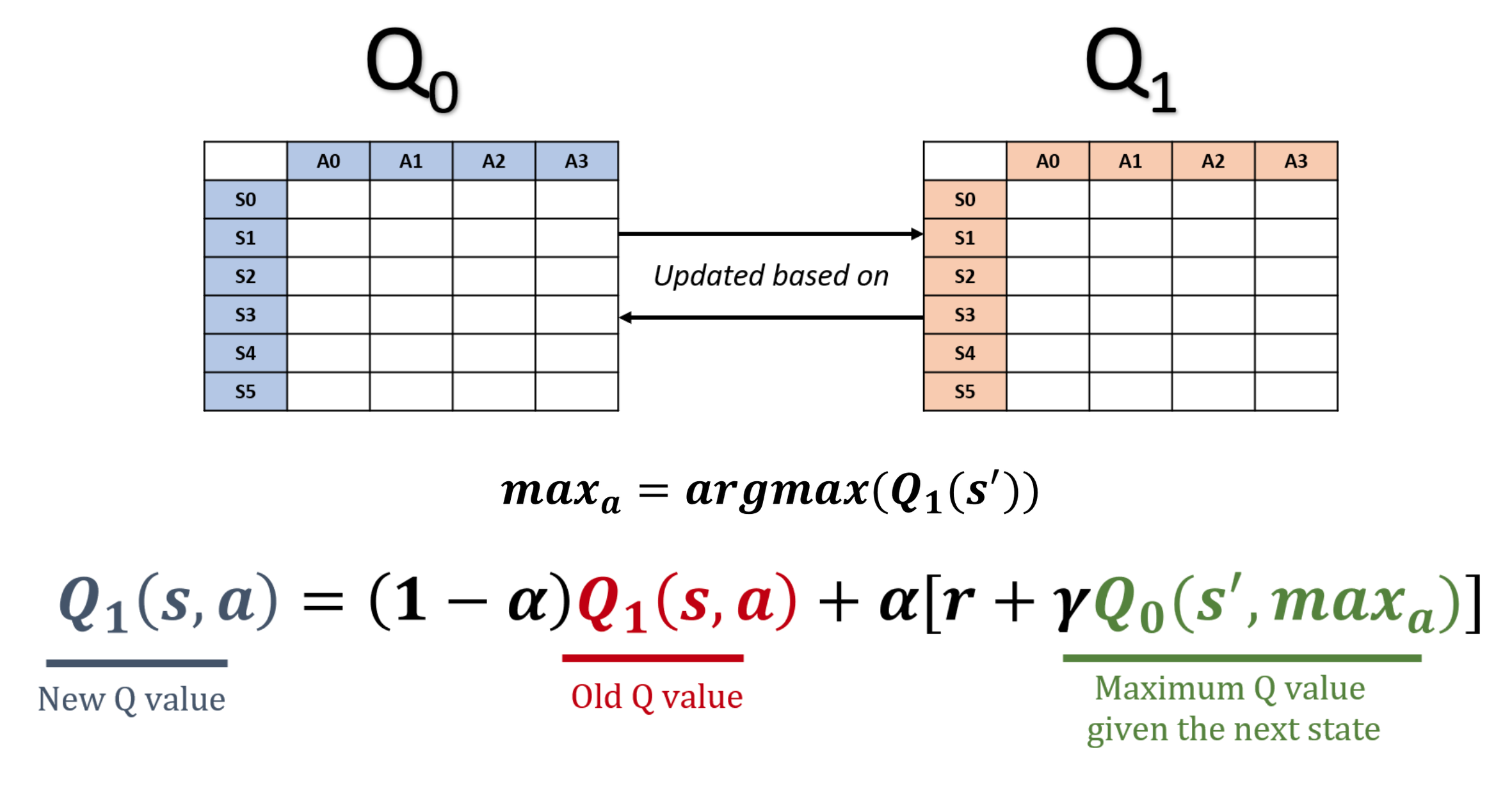
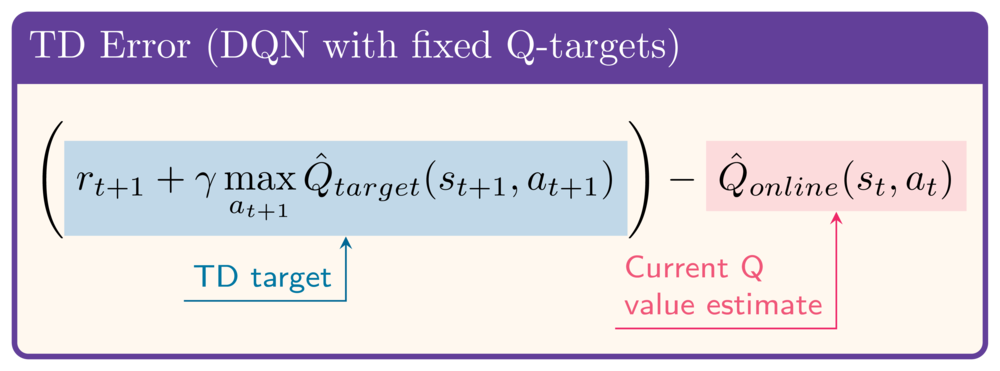
Het idee achter DDQN

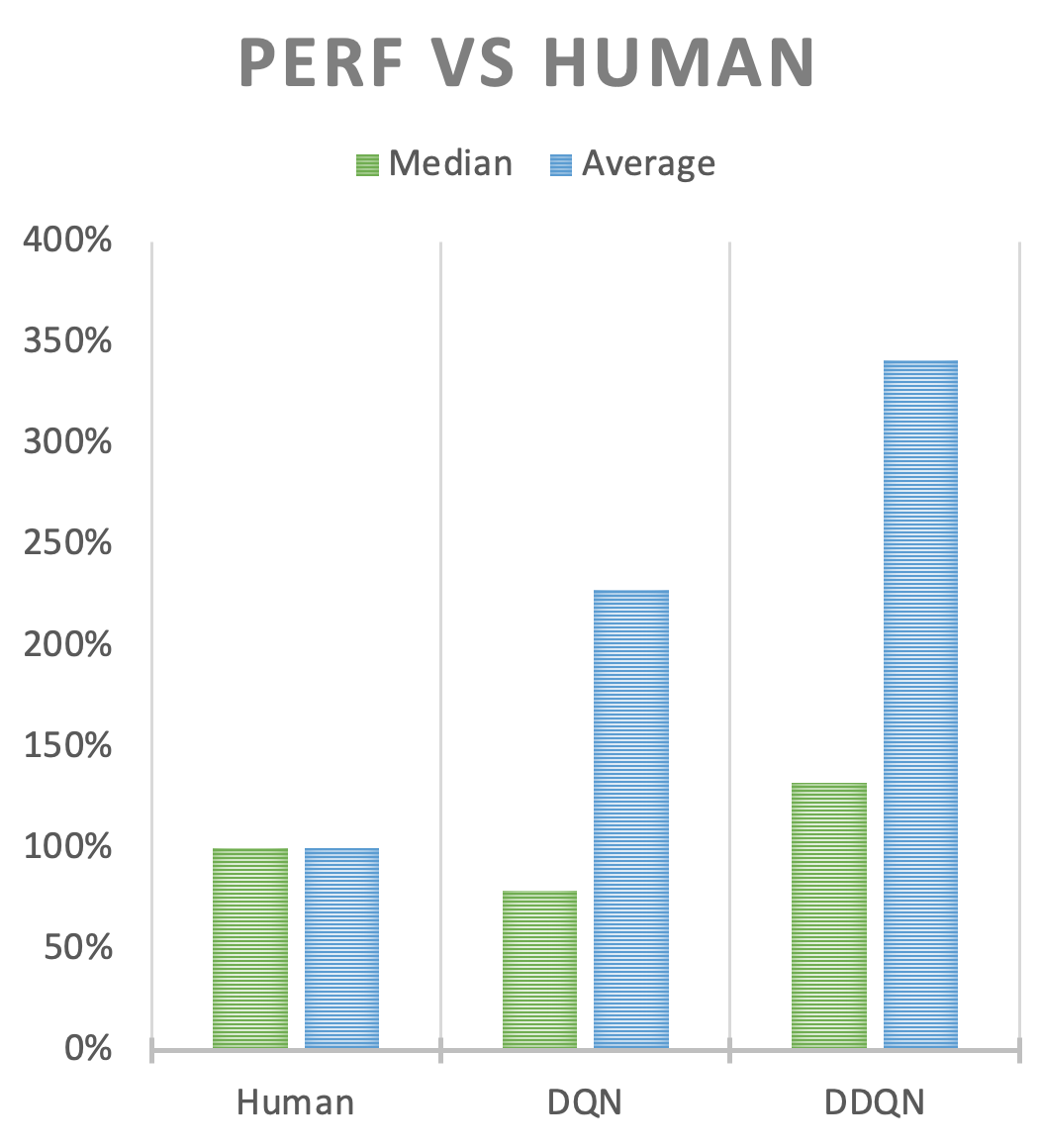
DDQN-prestaties
1 https://arxiv.org/abs/2303.11634

