Advantage Actor Critic
Deep Reinforcement Learning in Python

Timothée Carayol
Principal Machine Learning Engineer, Komment
Waarom actor-critic?
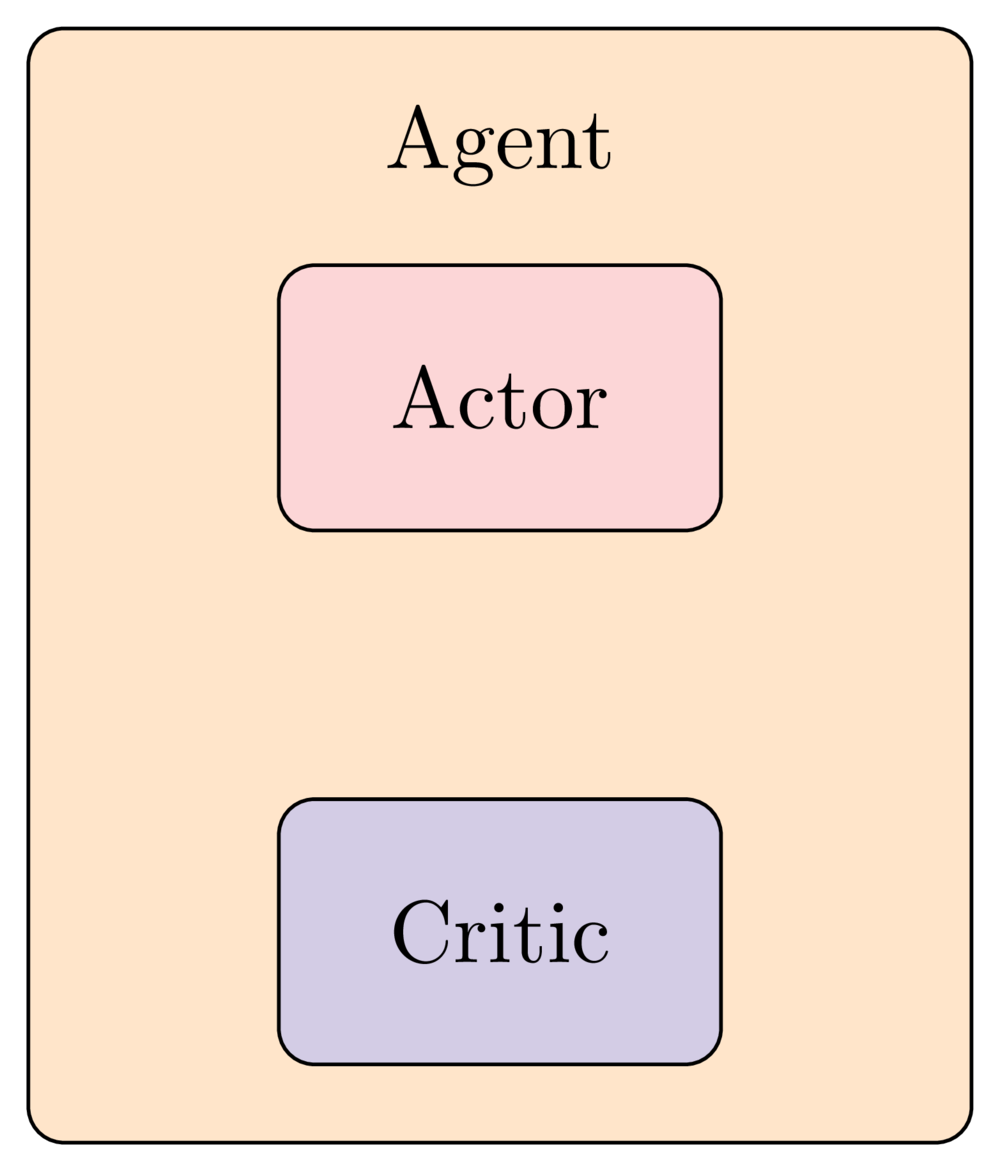
De intuïtie achter Actor-Critic-methoden

Het Critic-netwerk
- Critic benadert de state value-functie
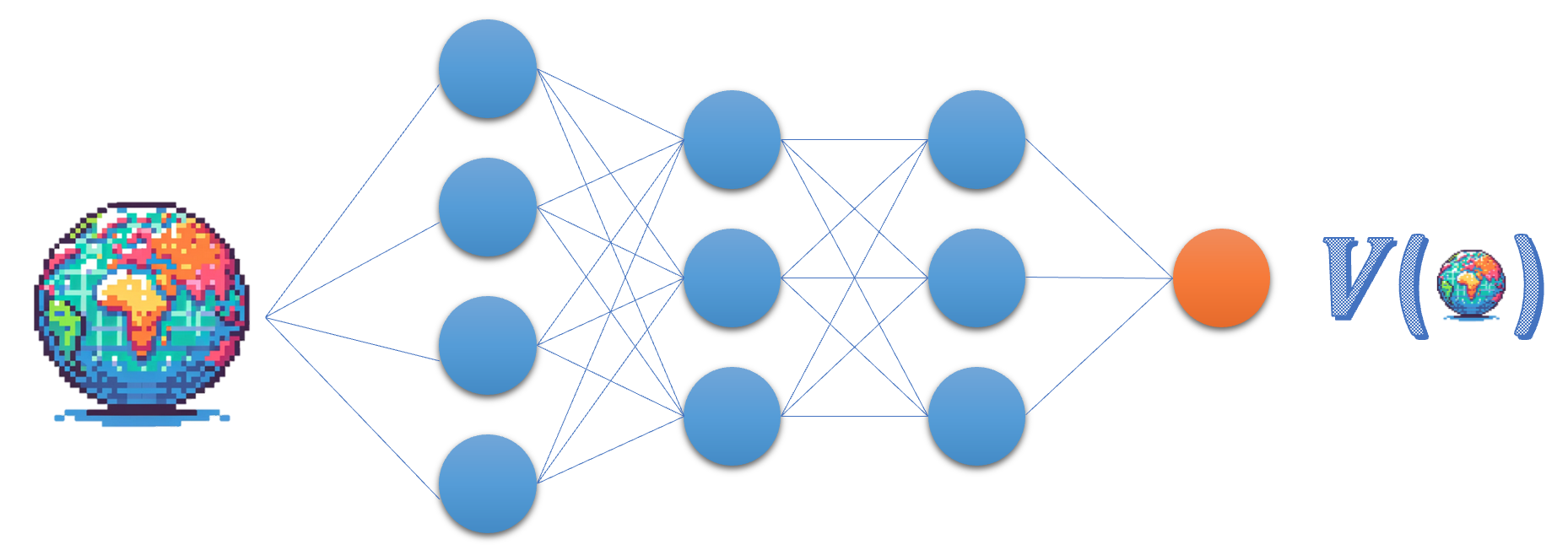
- Beoordeelt actie $a_t$ via de advantage of TD-fout
De Actor-Critic-dynamiek
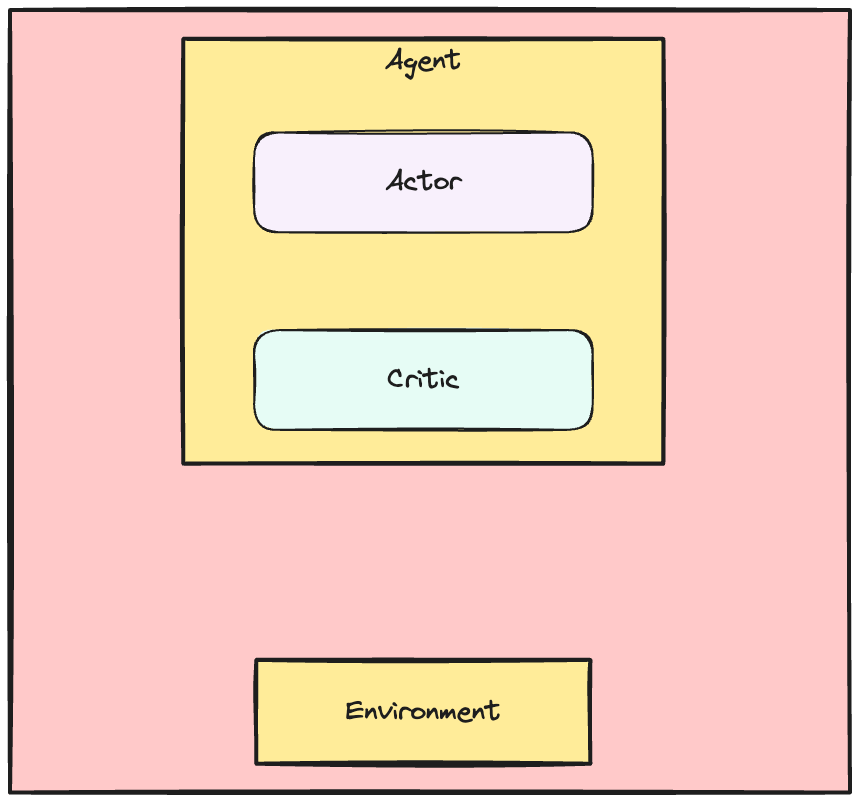
De Actor-Critic-dynamiek
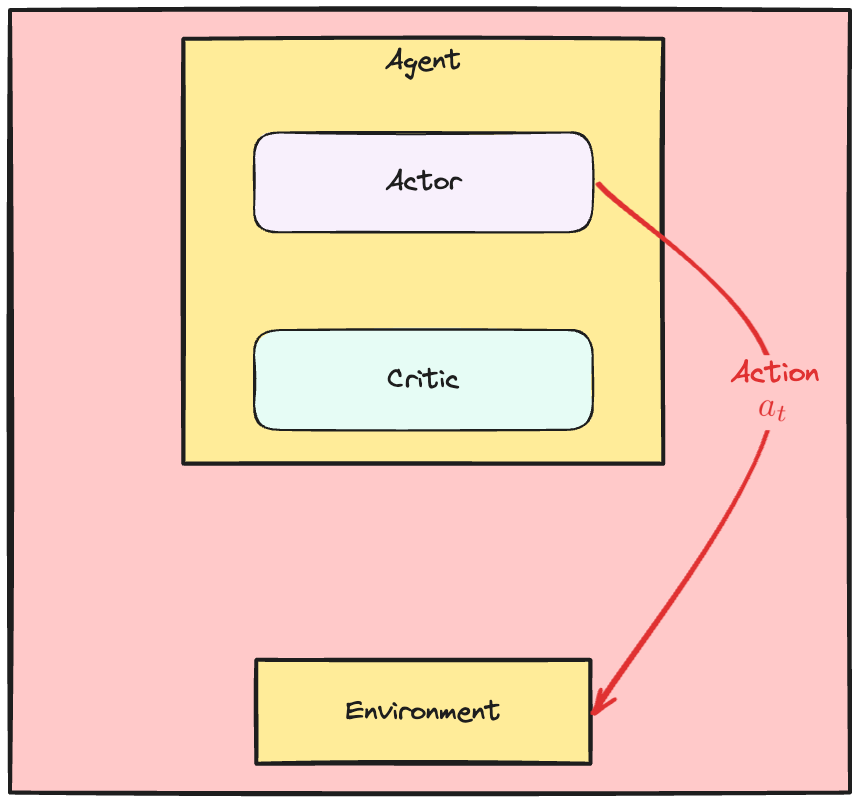
De Actor-Critic-dynamiek
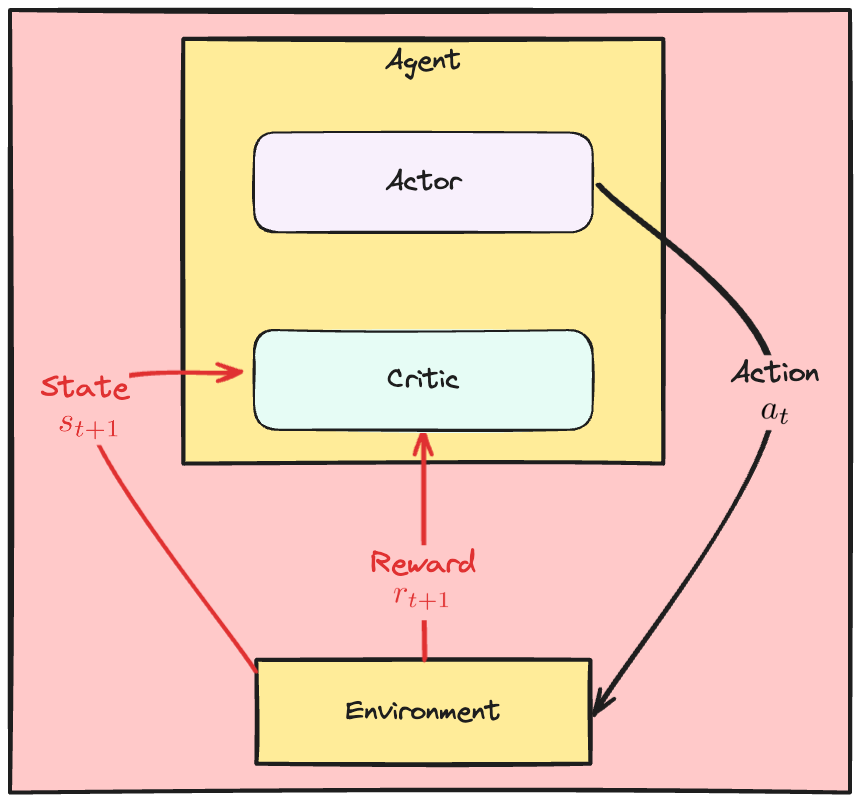
De Actor-Critic-dynamiek
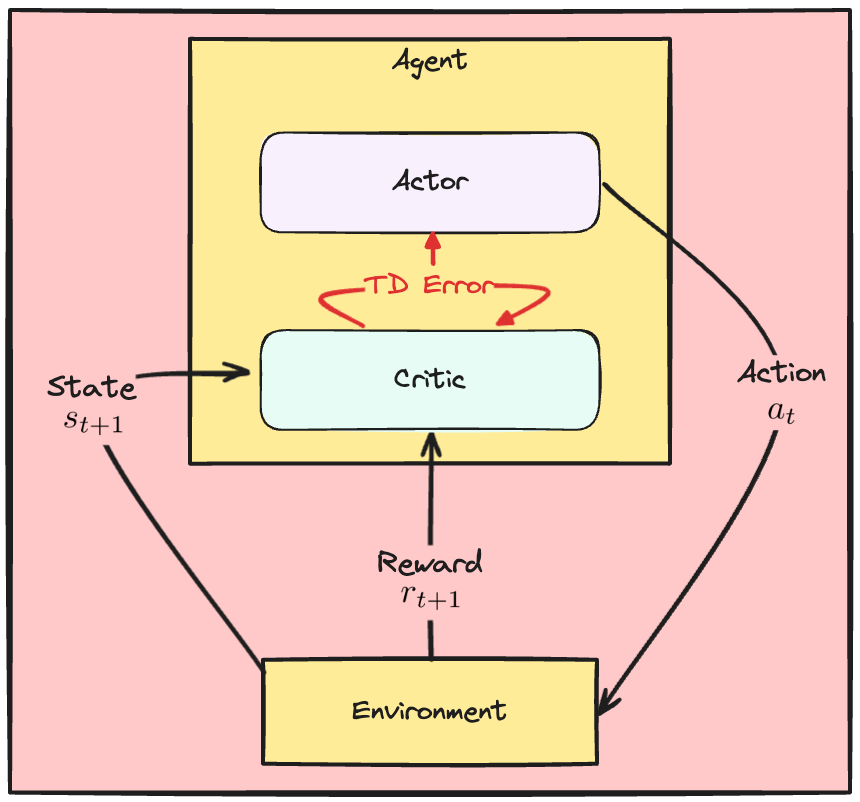
De Actor-Critic-dynamiek
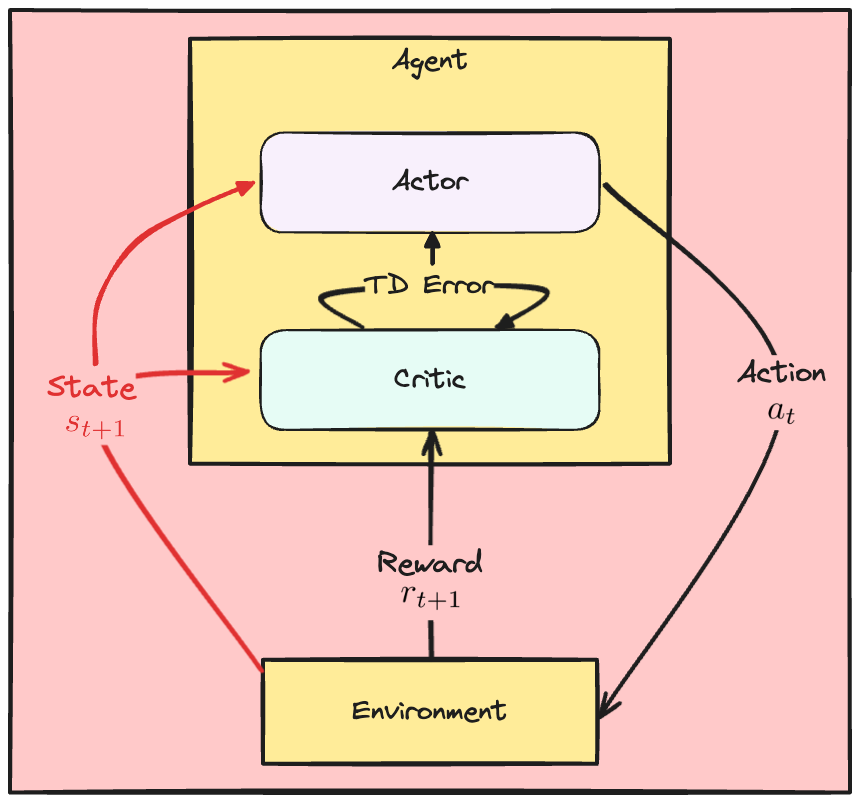
De A2C-verliesfuncties
Critic

- Verlies critic: kwadratische TD-fout
Actor

- TD-fout vat oordeel van critic samen
- Verhoog kans op acties met positieve TD-fout

