Introductie tot policy gradient
Deep Reinforcement Learning in Python

Timothée Carayol
Principal Machine Learning Engineer, Komment
Introductie tot Policymethoden in DRL
Q-learning:
- Leer de actie-waardefunctie Q
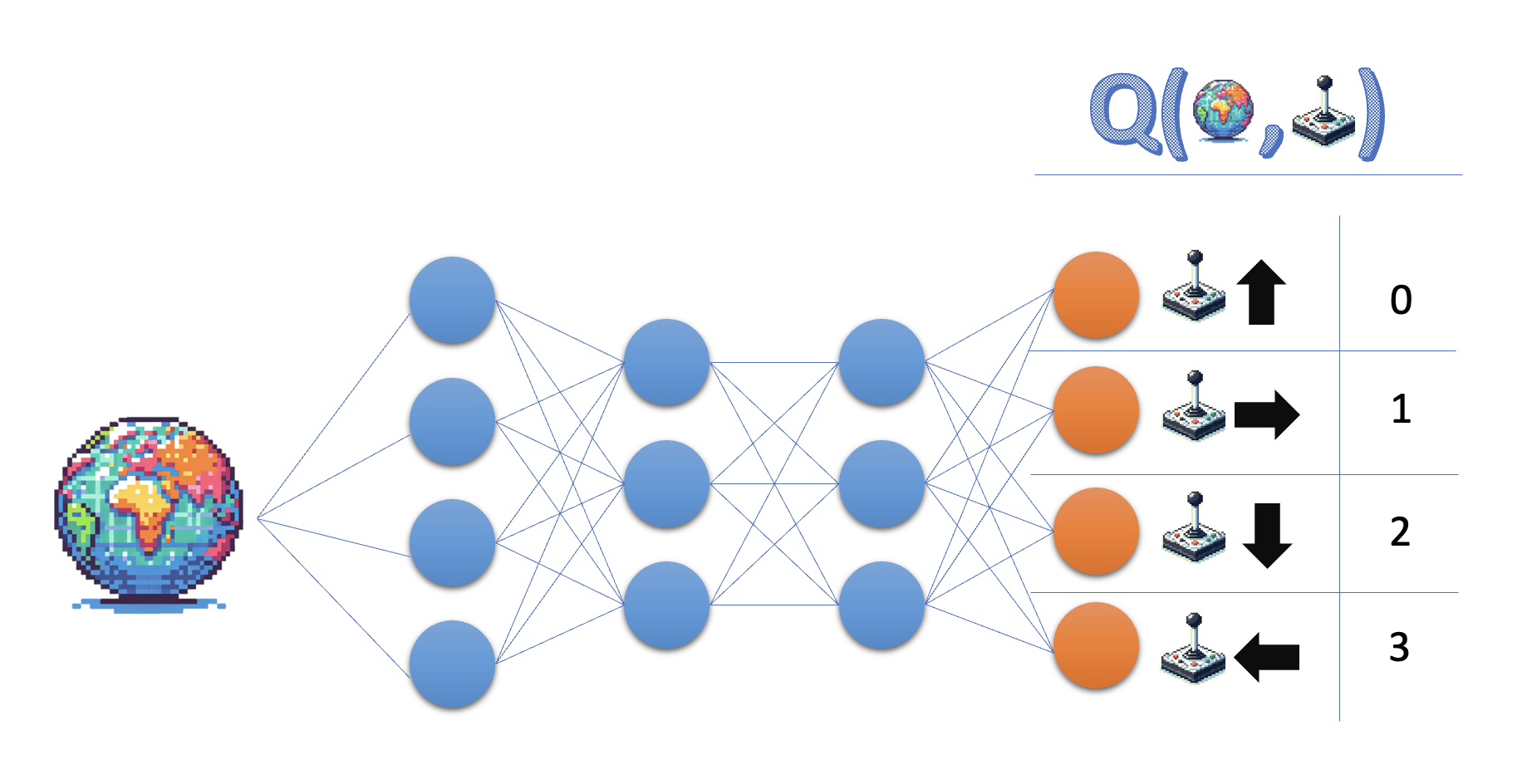
- Policy: kies de actie met hoogste waarde
Policy learning:
- Leer de policy direct
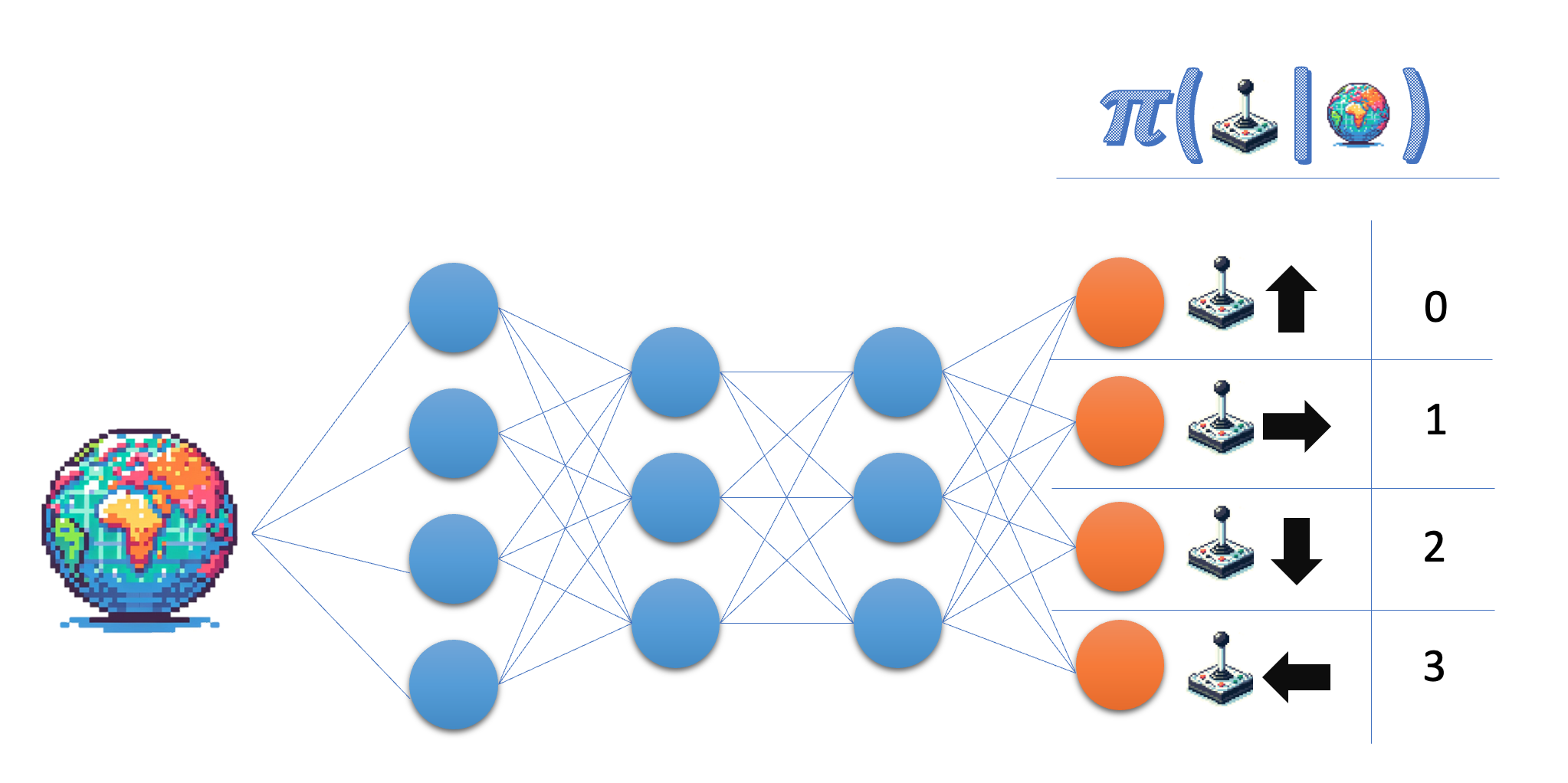
Het policy-netwerk (discrete acties)
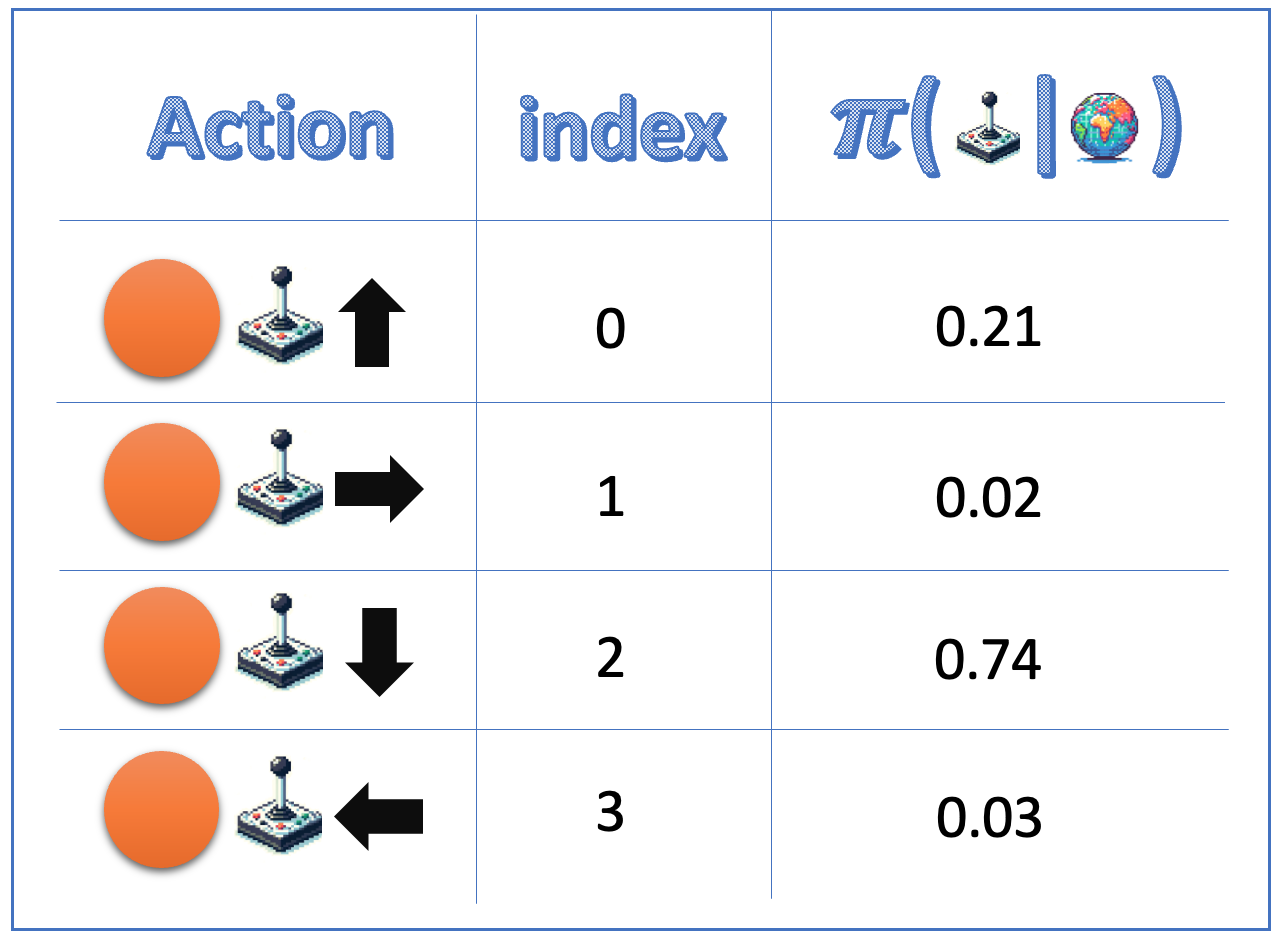
action_dist = ( torch.distributions.Categorical(action_probs))action = action_dist.sample()
De doelfunctie
Policy moet de verwachte opbrengst maximaliseren
- Aannemende dat de agent $\pi_\theta$ volgt
- Door de policy-parameter $\theta$ te optimaliseren
Doelfunctie:

- Om $J$ te maximaliseren: gradiënt nodig t.o.v. $\theta$:
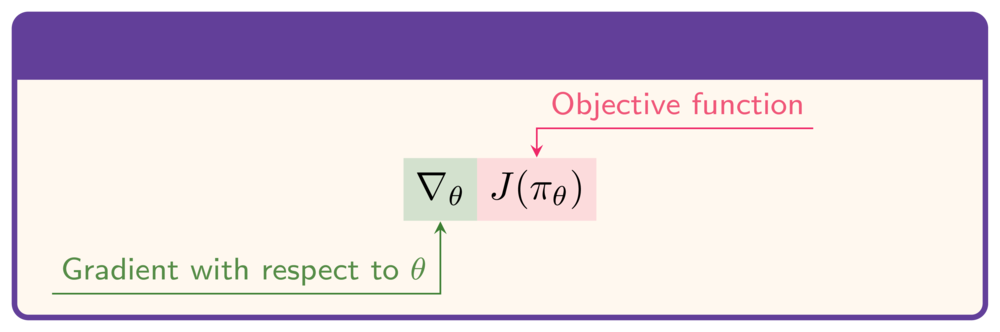
De doelfunctie
Policy moet de verwachte opbrengst maximaliseren
- Aannemende dat de agent $\pi_\theta$ volgt
- Door de policy-parameter $\theta$ te optimaliseren
Doelfunctie:
- Om $J$ te maximaliseren: gradiënt nodig t.o.v. $\theta$:
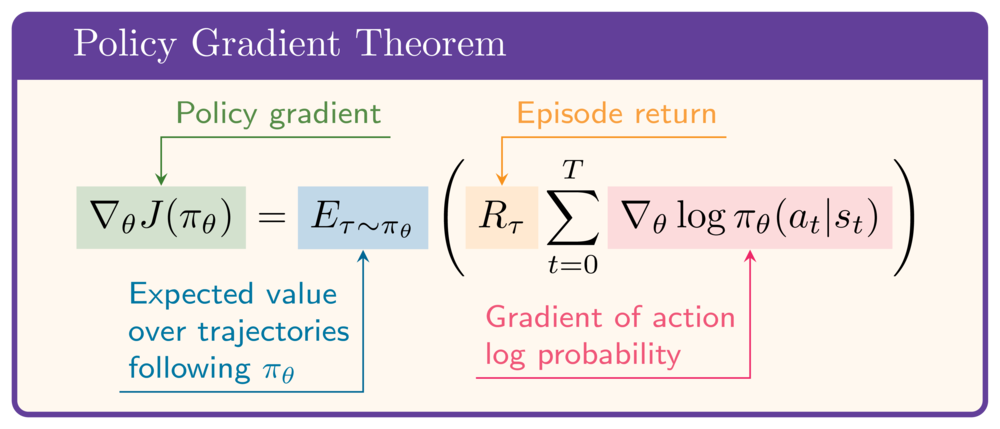
De policy gradient-stelling
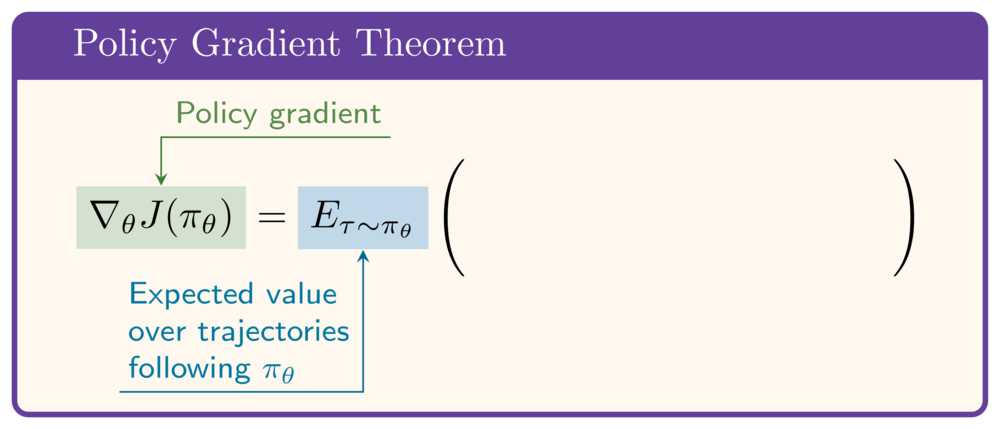
De policy gradient-stelling
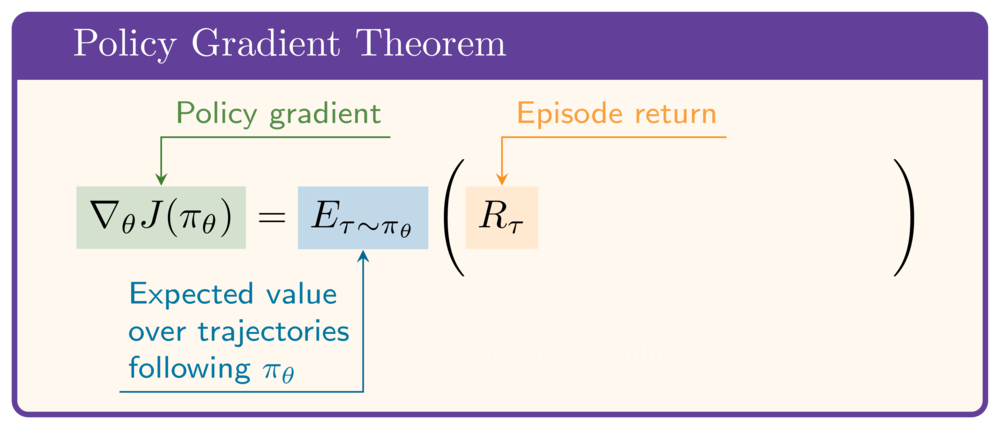
De policy gradient-stelling