Proximal policy optimization
Deep Reinforcement Learning in Python

Timothée Carayol
Principal Machine Learning Engineer, Komment
A2C
- A2C policy-updates:
- Gebaseerd op volatiele schattingen
- Kunnen groot en instabiel zijn
- Kan prestaties schaden

PPO
- PPO begrenst de grootte van elke policy-update
- Verbetert stabiliteit

De kansratio
- Belangrijkste vernieuwing in PPO: nieuwe doelfunctie
- Kernidee:

- Hoeveel waarschijnlijker is actie $a_t$ met $\theta$ dan met $\theta_{old}$?
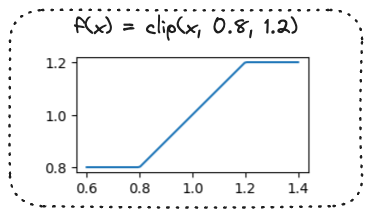
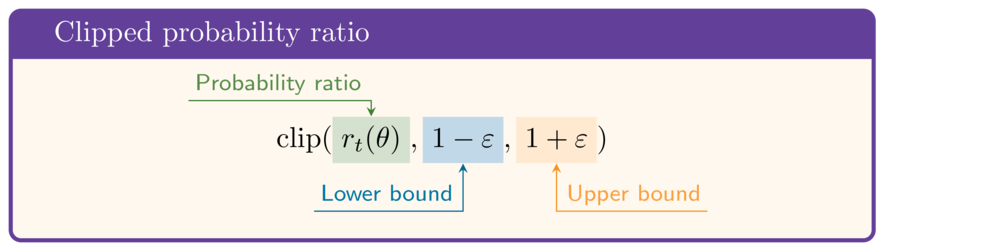
De kansratio clippen
- Clip-functie:
De PPO-doelfunctie

surr1 = ratio * td_error.detach()surr2 = clipped_ratio * td_error.detach()objective = torch.min(surr1, surr2)
- Surrogaat met afgeklemde ratio:
$$\mathrm{clip}(r_t(\theta),1-\varepsilon,1+\varepsilon)\hat{A}$$
- PPO-doelfunctie met clipping:

- Stabieler dan A2C

