Klassenonevenwicht in leningegevens
Kredietrisicomodellering in Python

Michael Crabtree
Data Scientist, Ford Motor Company
Verliesfunctie van het model
- Gradient Boosted Trees in
xgboostgebruiken log‑loss als verliesfunctie- Doel: deze waarde minimaliseren
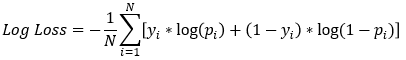
| Werkelijke status | Voorspelde kans | Log‑loss |
|---|---|---|
| 1 | 0.1 | 2.3 |
| 0 | 0.9 | 2.3 |
- Een fout voorspelde default heeft grotere financiële impact
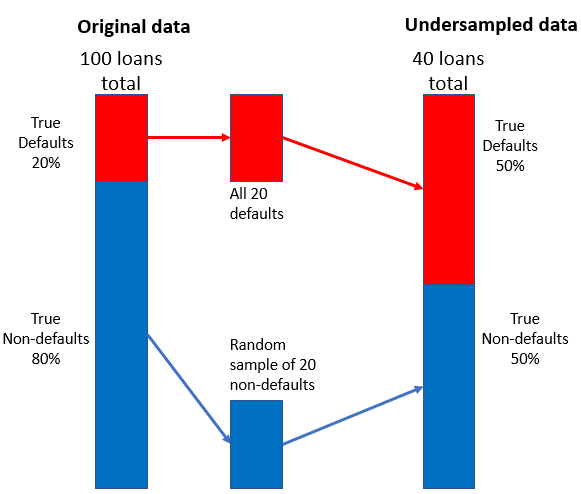
Undersampling-strategie
- Combineer een kleine willekeurige steekproef van niet‑defaults met defaults