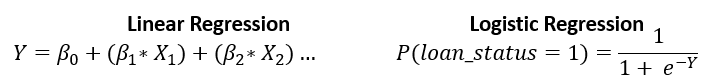Logistische regressie voor defaultkans
Kredietrisicomodellering in Python

Michael Crabtree
Data Scientist, Ford Motor Company
Kansen voorspellen
- Defaultkansen als output van machine learning
- Leren van kolommen (features)
- Classificatiemodellen (default, geen default)
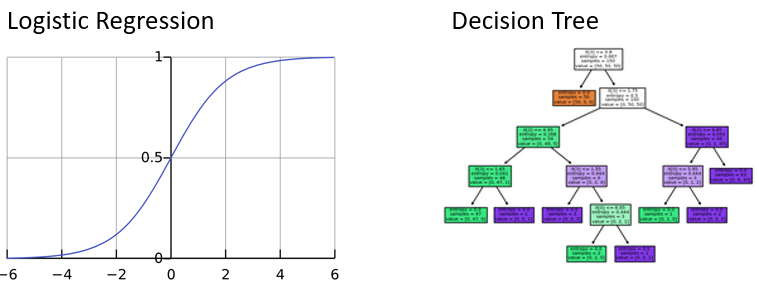
- Twee meest gebruikte modellen:
- Logistische regressie
- Beslissingsboom
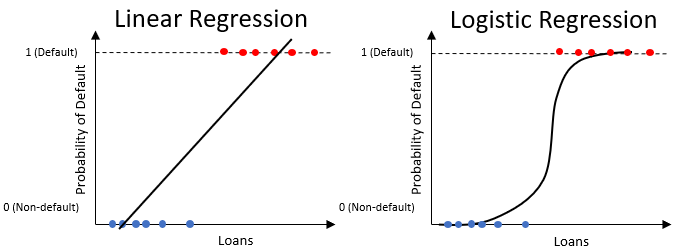
Logistische regressie
- Lijkt op lineaire regressie, maar geeft alleen waarden tussen
0en1