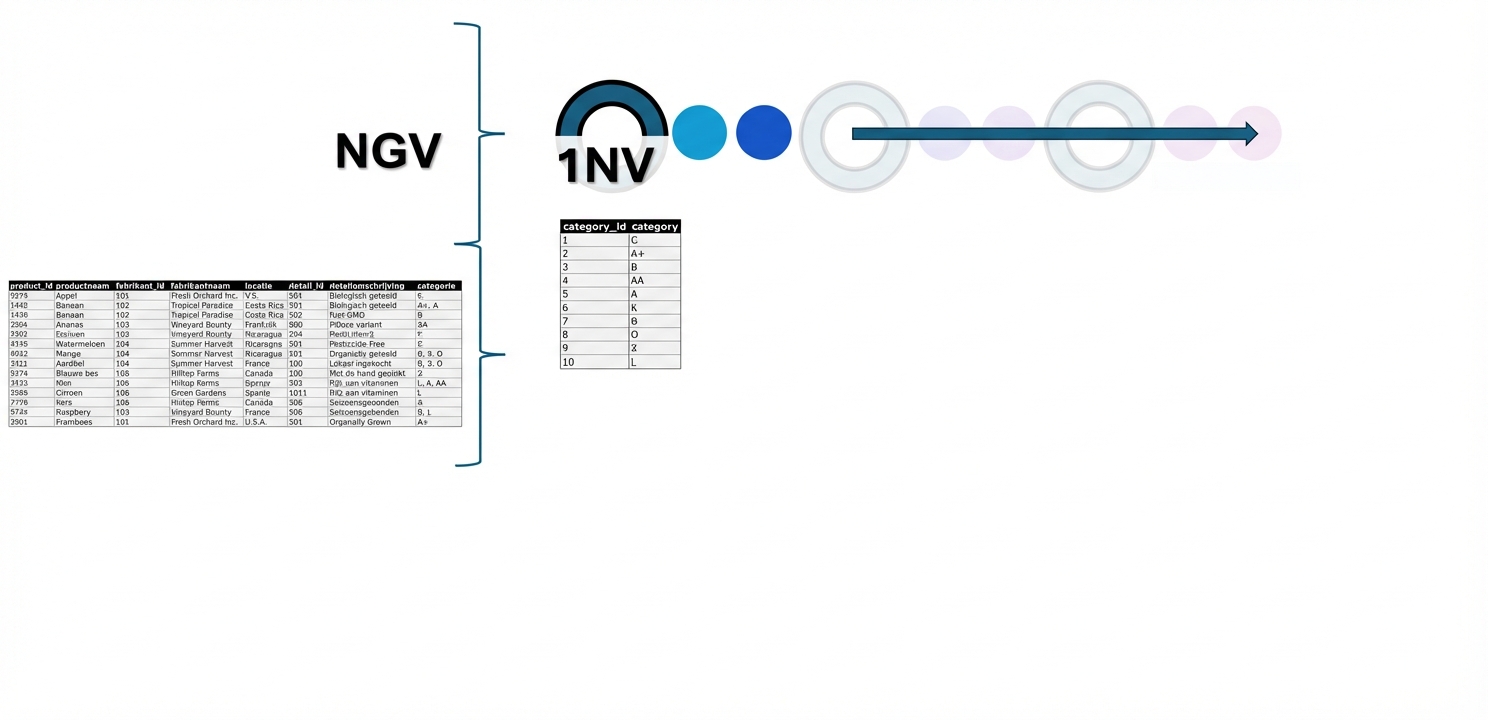
De eerste normaalvorm
Introductie tot datamodellering in Snowflake

Nuno Rocha
Director of Engineering
Het proces van datanormalisatie
- Datanormalisatie: Meertrapsproces om data te structureren en dubbels en afhankelijkheden te minimaliseren

Het proces van datanormalisatie (1)
- Datanormalisatie: Meertrapsproces om data te structureren en dubbels en afhankelijkheden te minimaliseren

Het proces van datanormalisatie (2)
- Datanormalisatie: Meertrapsproces om data te structureren en dubbels en afhankelijkheden te minimaliseren
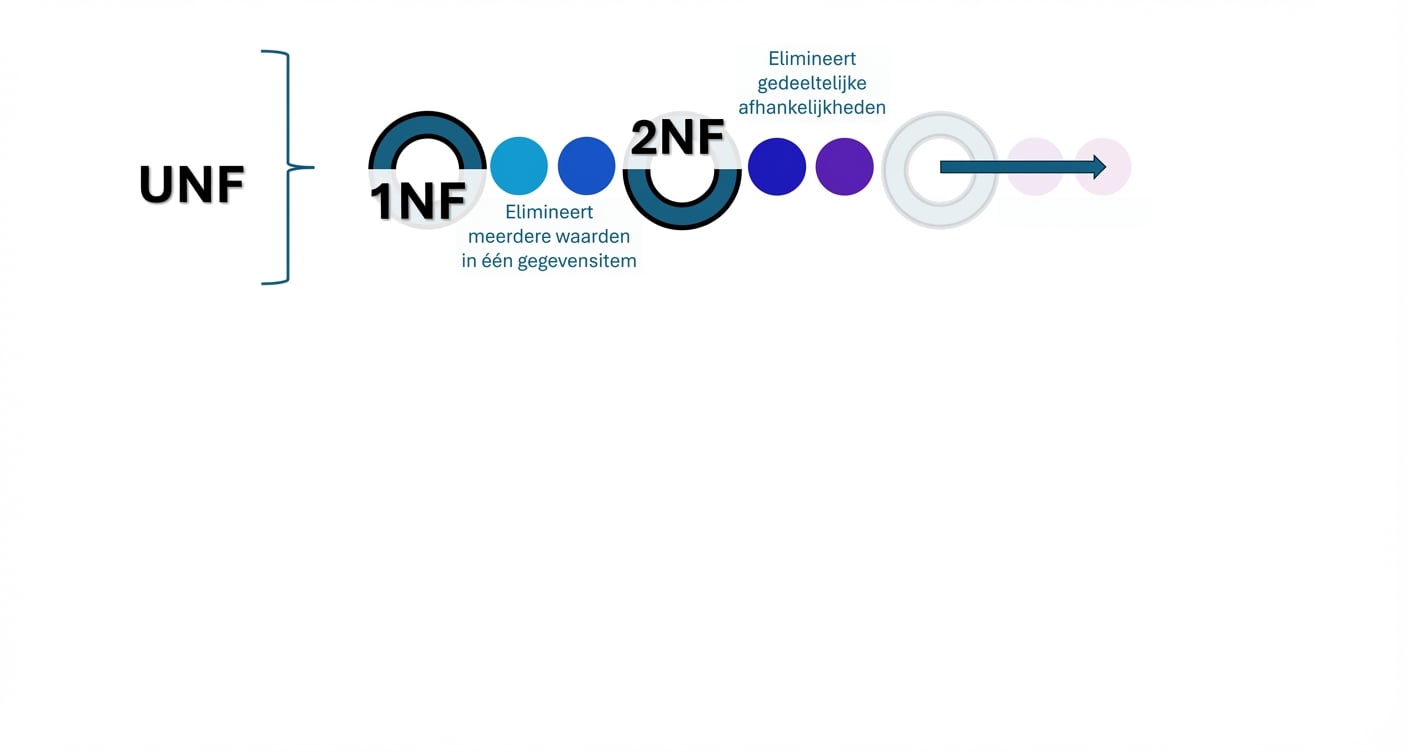
Het proces van datanormalisatie (3)
- Datanormalisatie: Meertrapsproces om data te structureren en dubbels en afhankelijkheden te minimaliseren
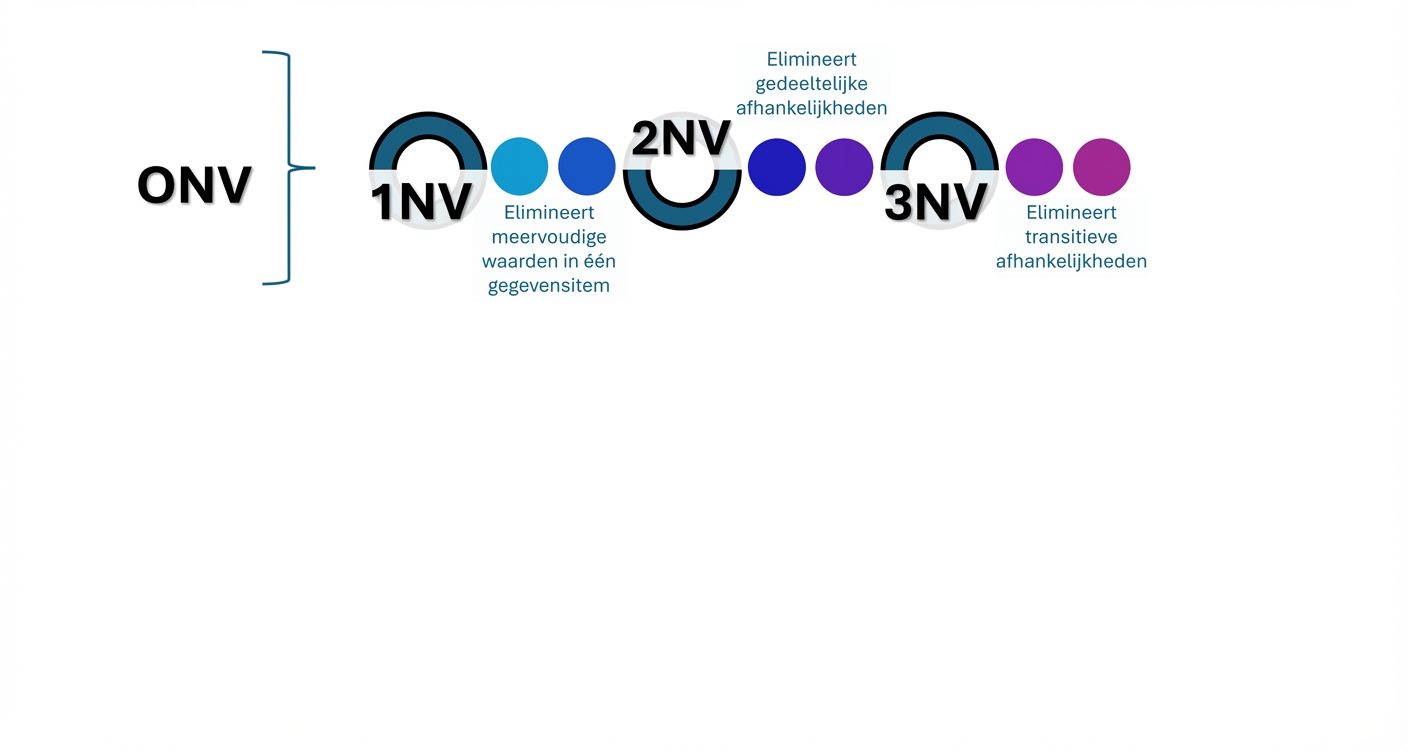
De eerste normaalvorm
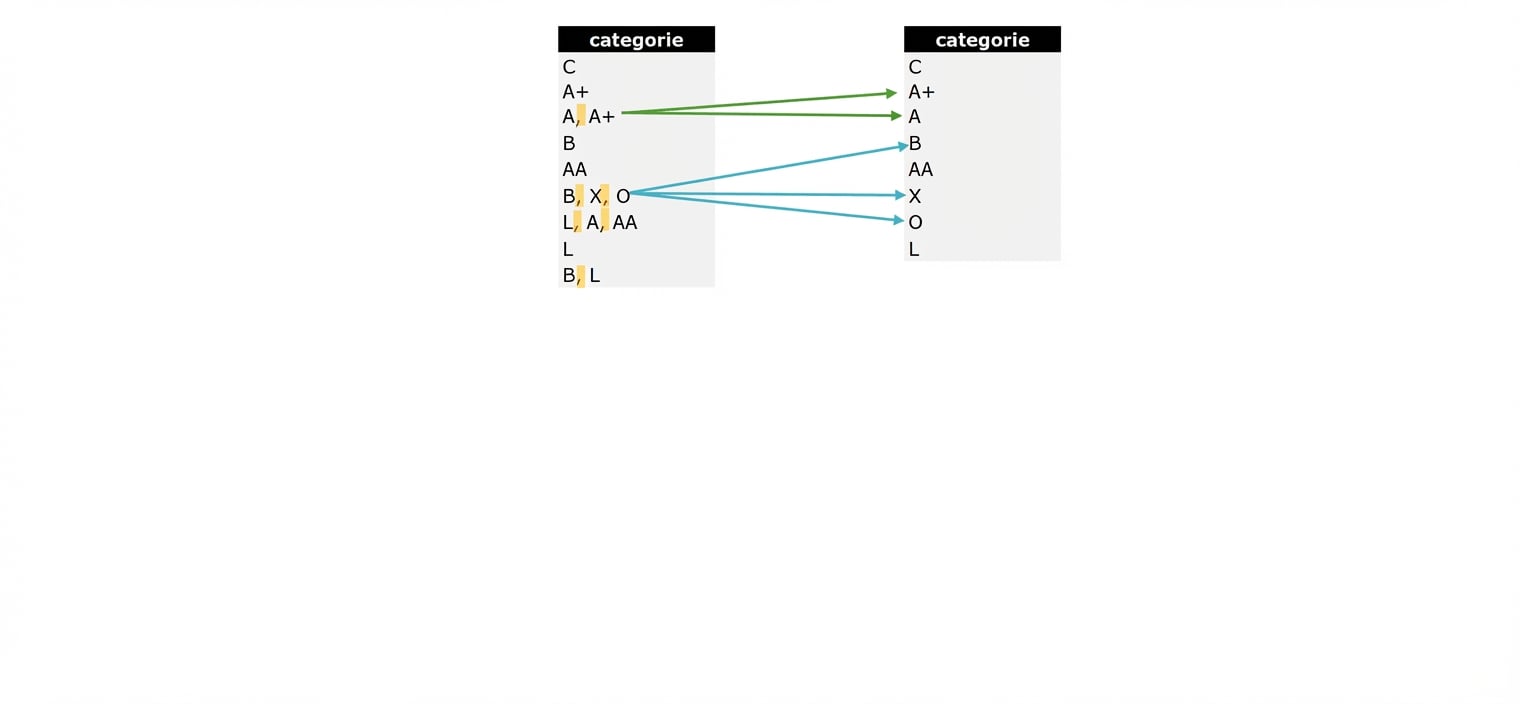
- Eerste normaalvorm (1NF): Zorgt dat elke kolom in een entiteit unieke, atomische waarden heeft
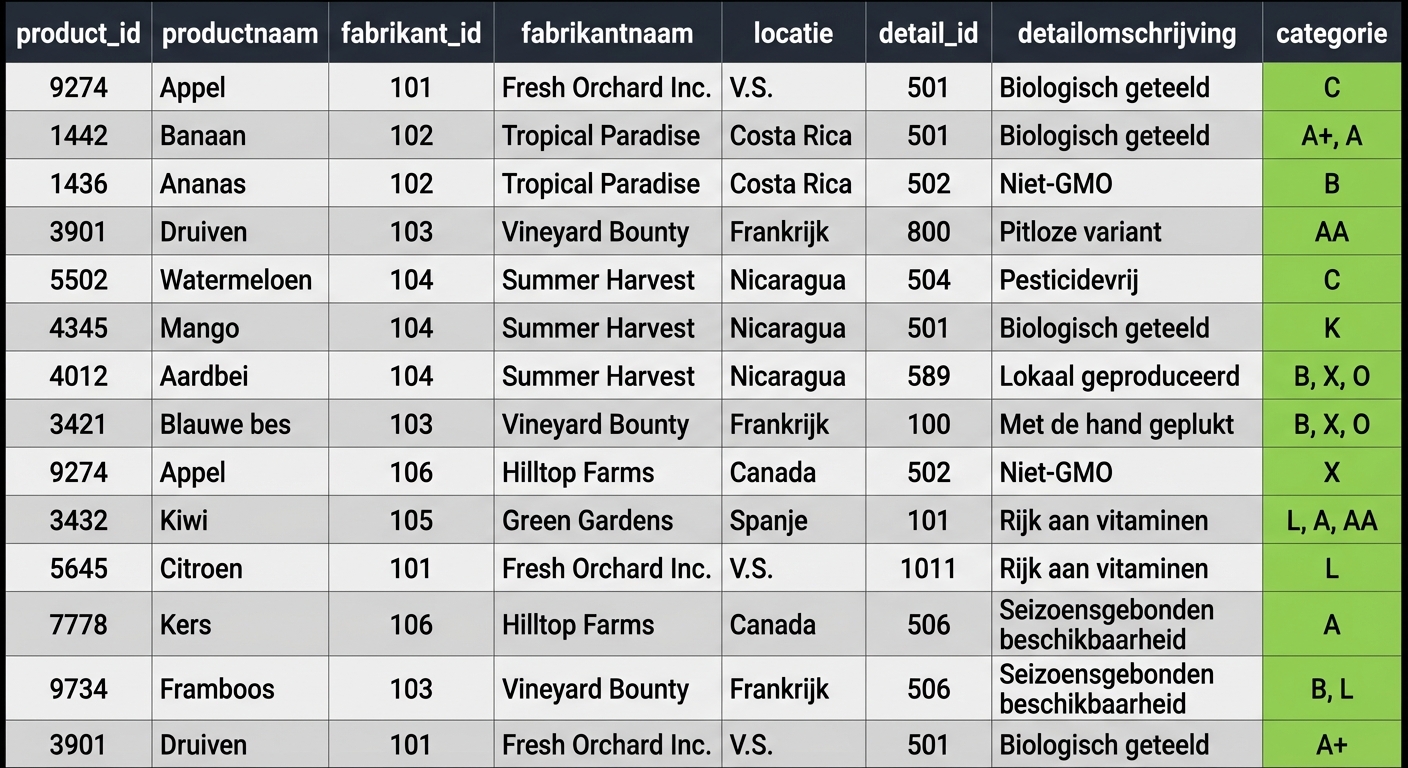
De eerste normaalvorm (1)
- UNF-categoriedata: L-categorie is niet geïsoleerd, dus waarden kun je niet apart bijwerken

De eerste normaalvorm (2)
- Validatiestap: Vraag unieke waarden op om te checken of aan 1NF is voldaan.
SELECT DISTINCT category
FROM allproducts;

Snowflake-functies voor 1NF
- TRIM: Verwijdert spaties aan begin en eind van waarden
SELECT TRIM(category)
FROM allproducts;

Snowflake-functies voor 1NF
- TRIM: Verwijdert spaties aan begin en eind van waarden.
- LATERAL & FLATTEN: Behandel een lijst met waarden als een tabel met losse items.
- SPLIT: Splitst waarden op een scheidingsteken.
SELECT TRIM(f.value)
FROM allproducts,
LATERAL FLATTEN(INPUT => SPLIT(allproducts.category, ',')) f;
Richting datanormalisatie