Regressie
Machine Learning met PySpark

Andrew Collier
Data Scientist, Fathom Data
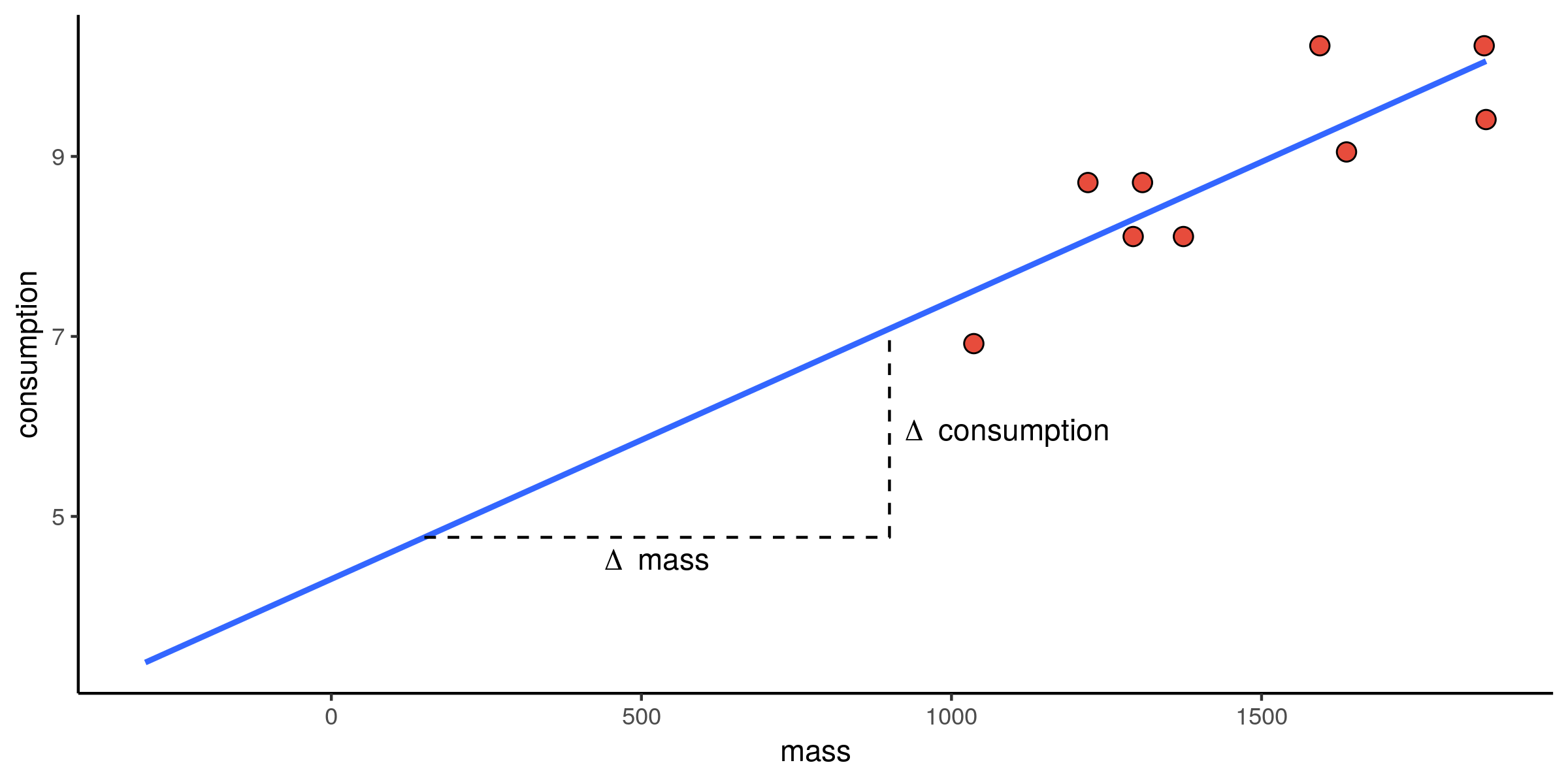
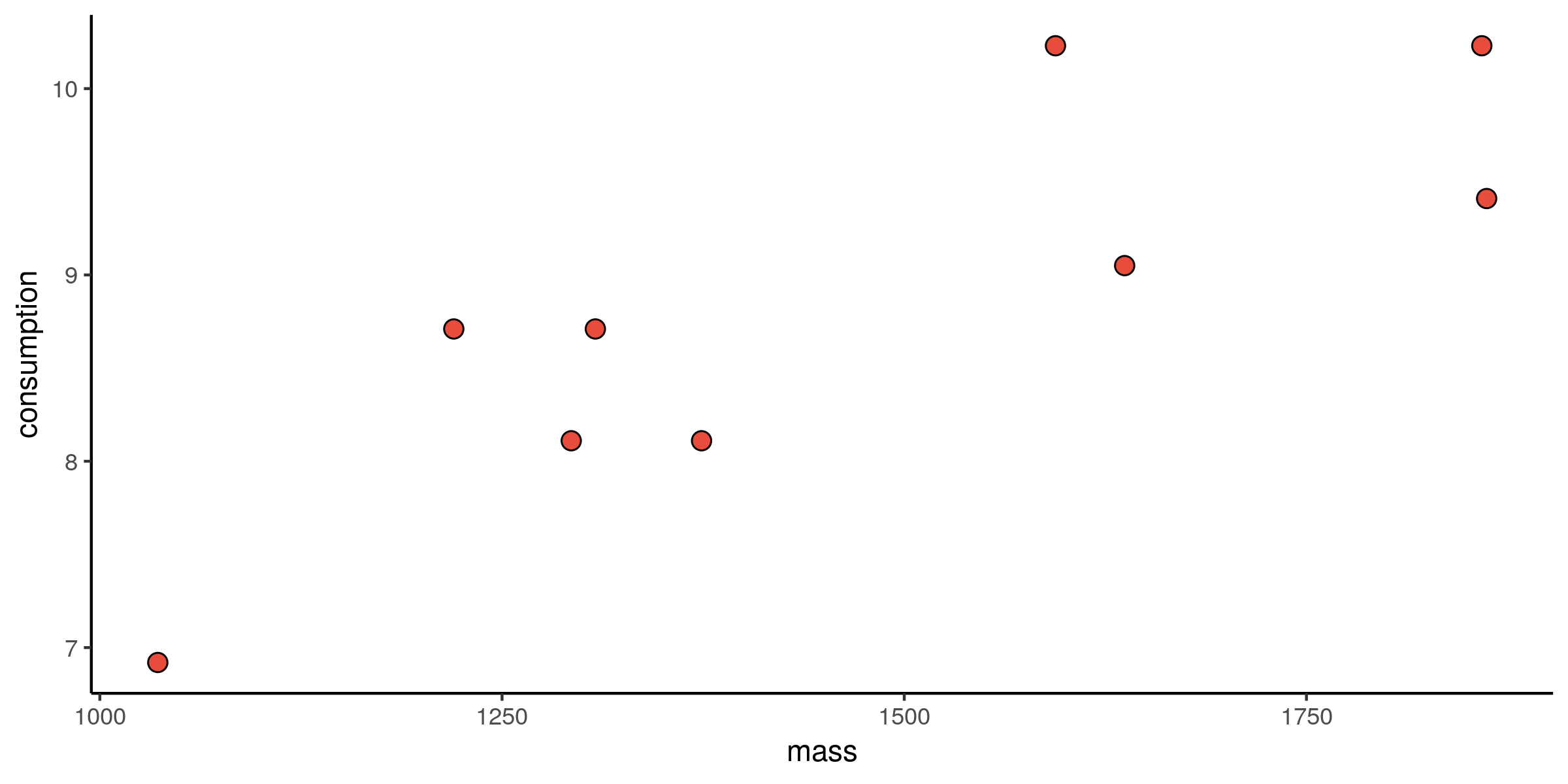
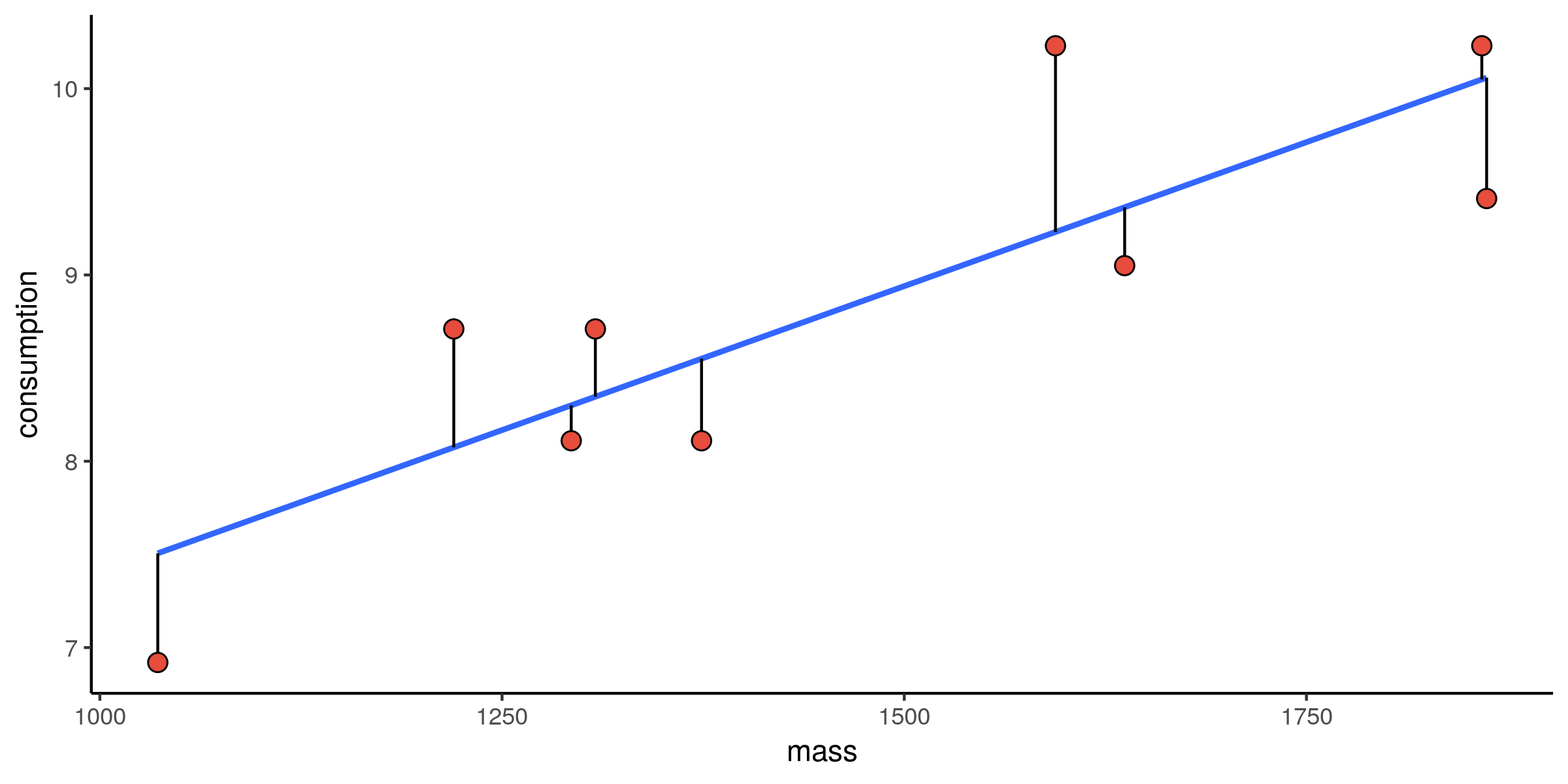
Verbruik vs. massa: spreiding
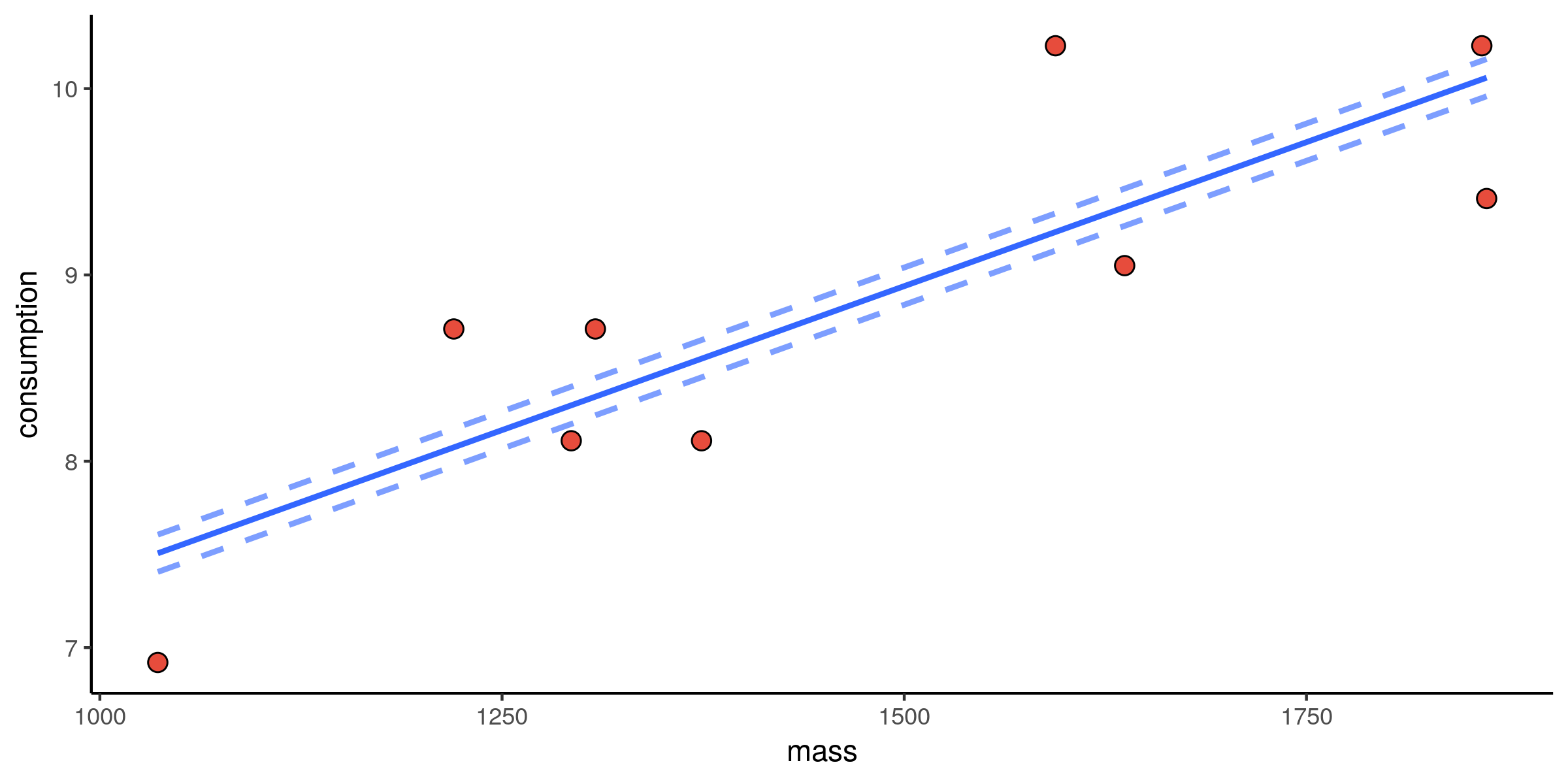
Verbruik vs. massa: fit
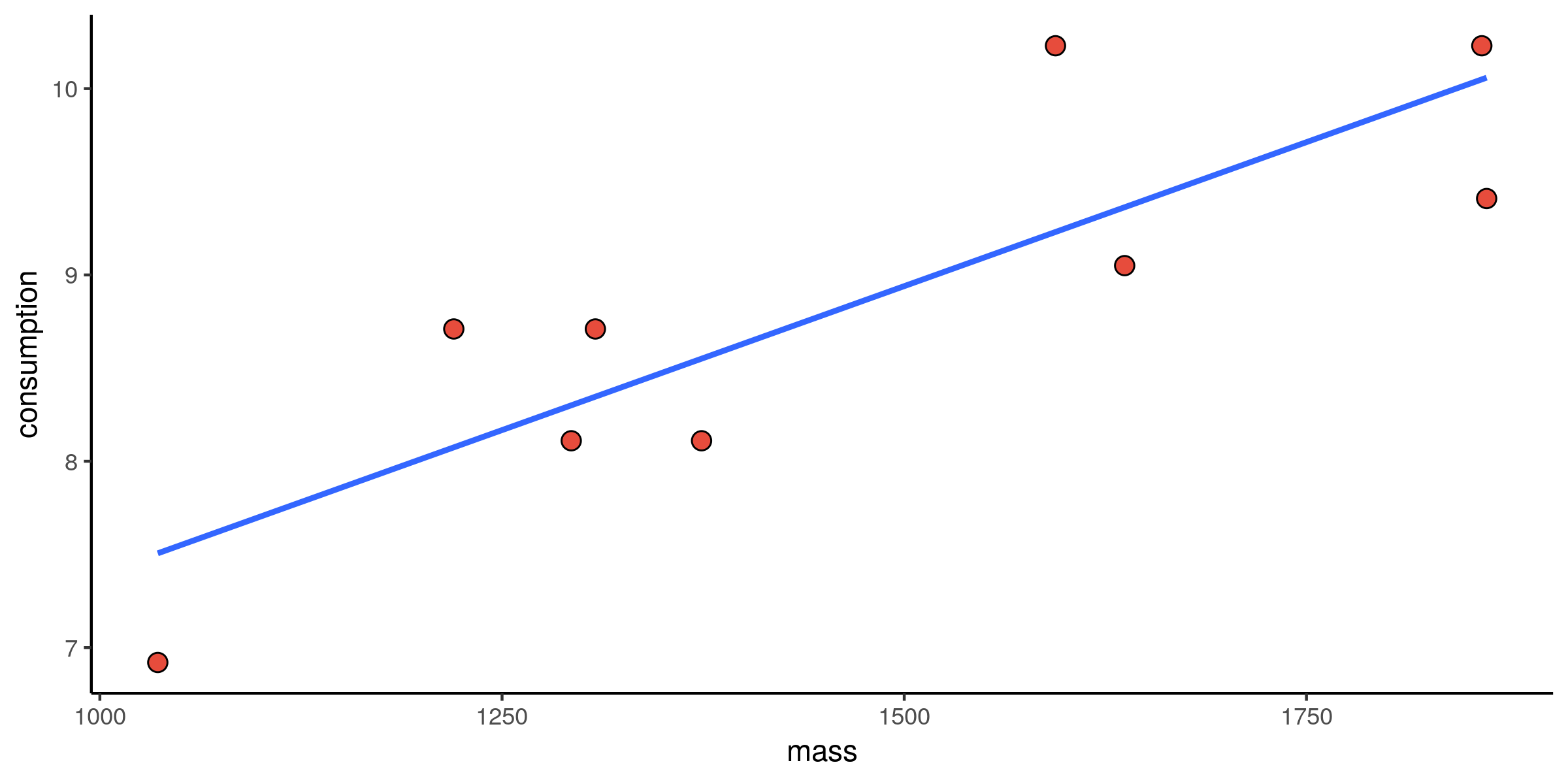
Verbruik vs. massa: alternatieve fits
Verbruik vs. massa: residuen
Verliesfunctie
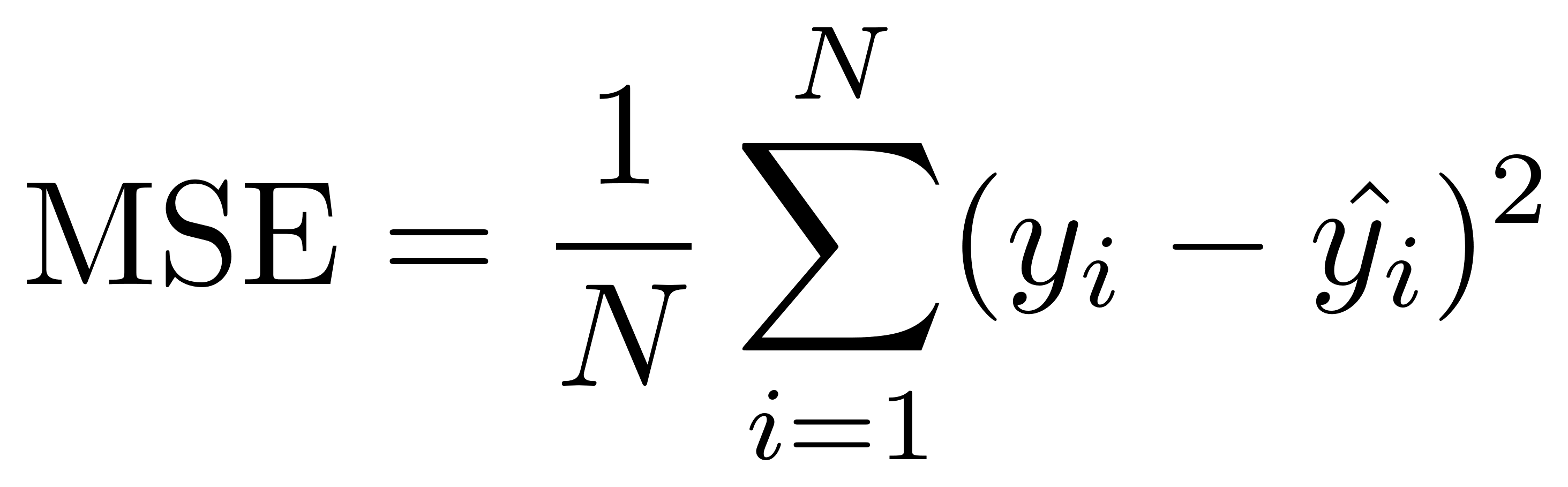
MSE = "Mean Squared Error"
Verliesfunctie: Geobserveerde waarden
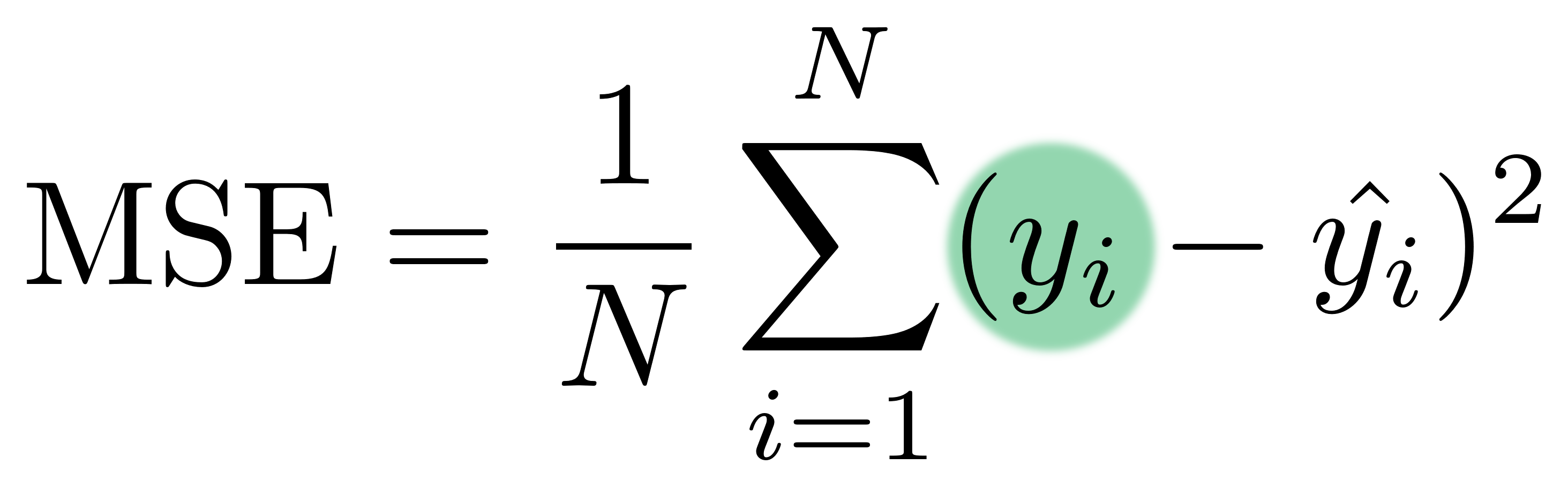
$y_i$ — geobserveerde waarden
Verliesfunctie: Modelwaarden
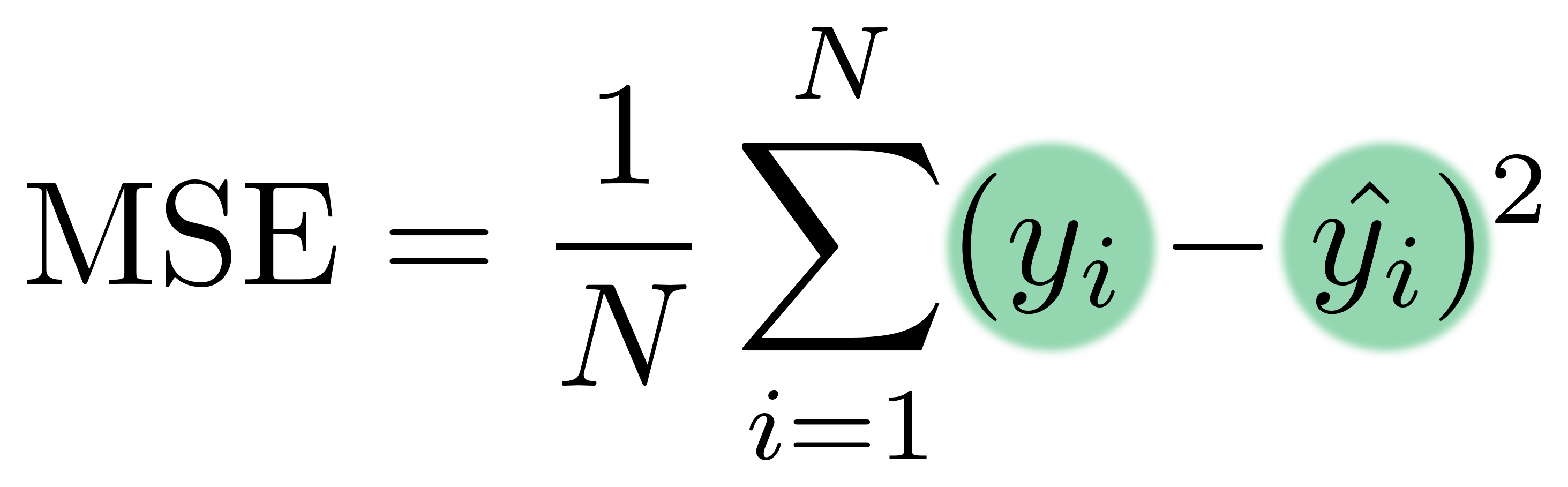
$y_i$ — geobserveerde waarden
$\hat{y_i}$ — modelwaarden
Verliesfunctie: Gemiddelde
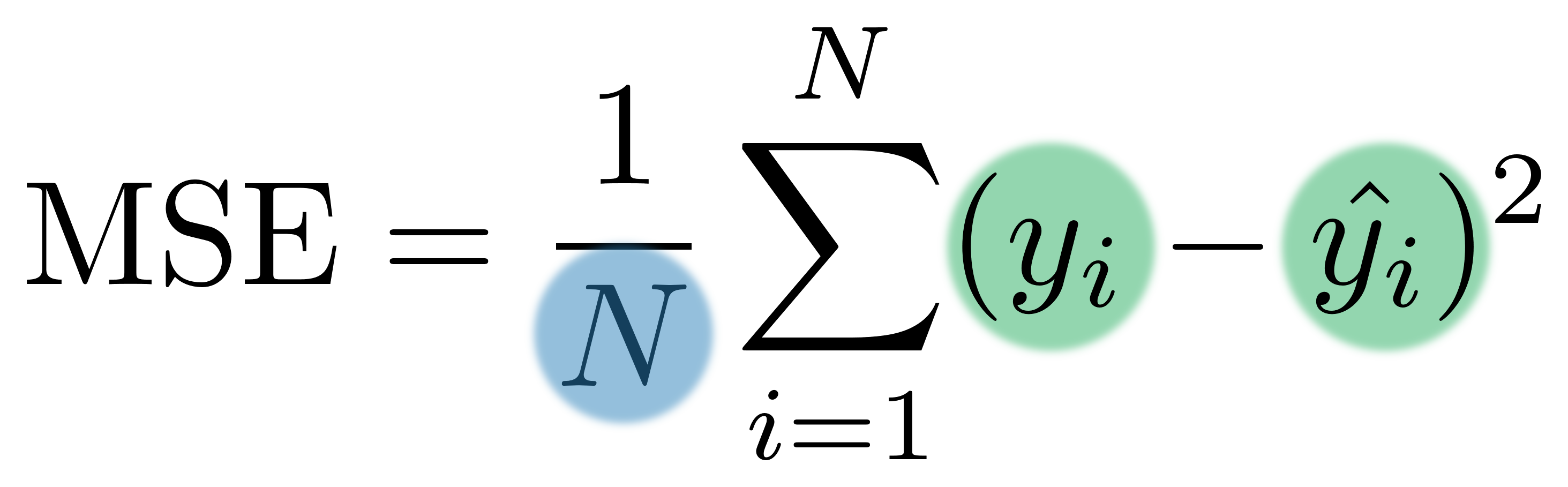
$y_i$ — geobserveerde waarden
$\hat{y_i}$ — modelwaarden
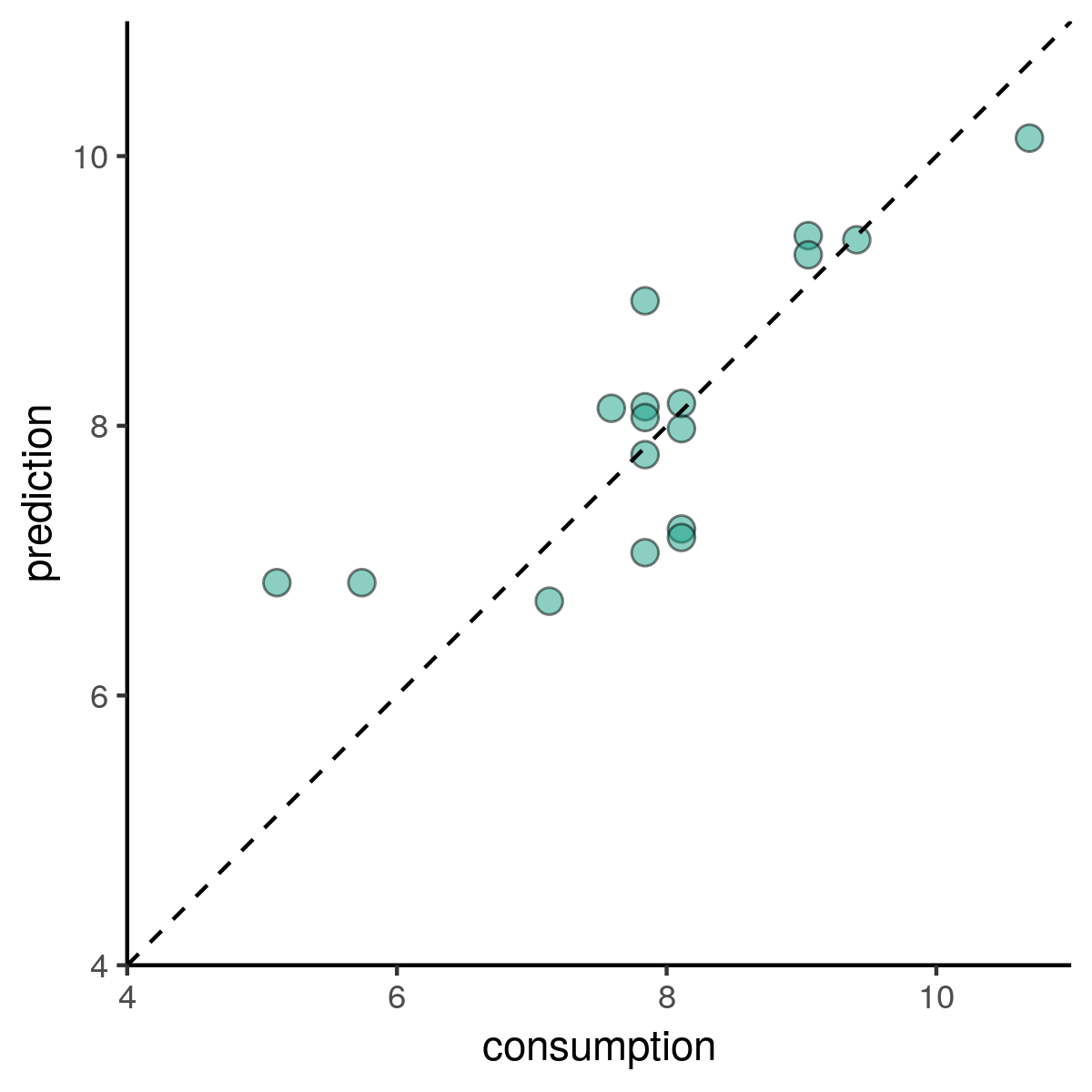
Voorspellingen bekijken
Verbruik vs. massa: intercept
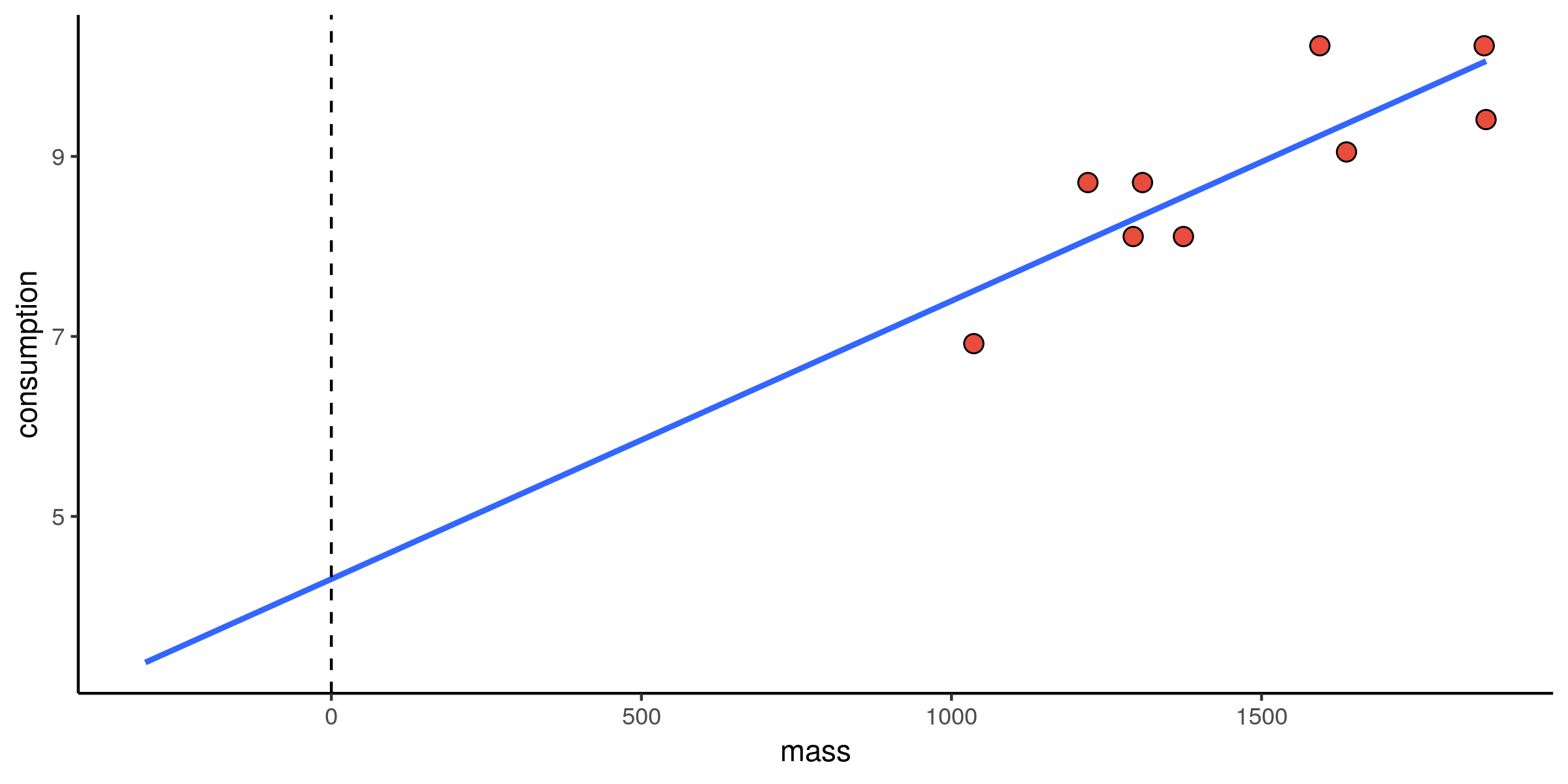
Verbruik vs. massa: helling