Kruisvalidering
Machine Learning met PySpark

Andrew Collier
Data Scientist, Fathom Data


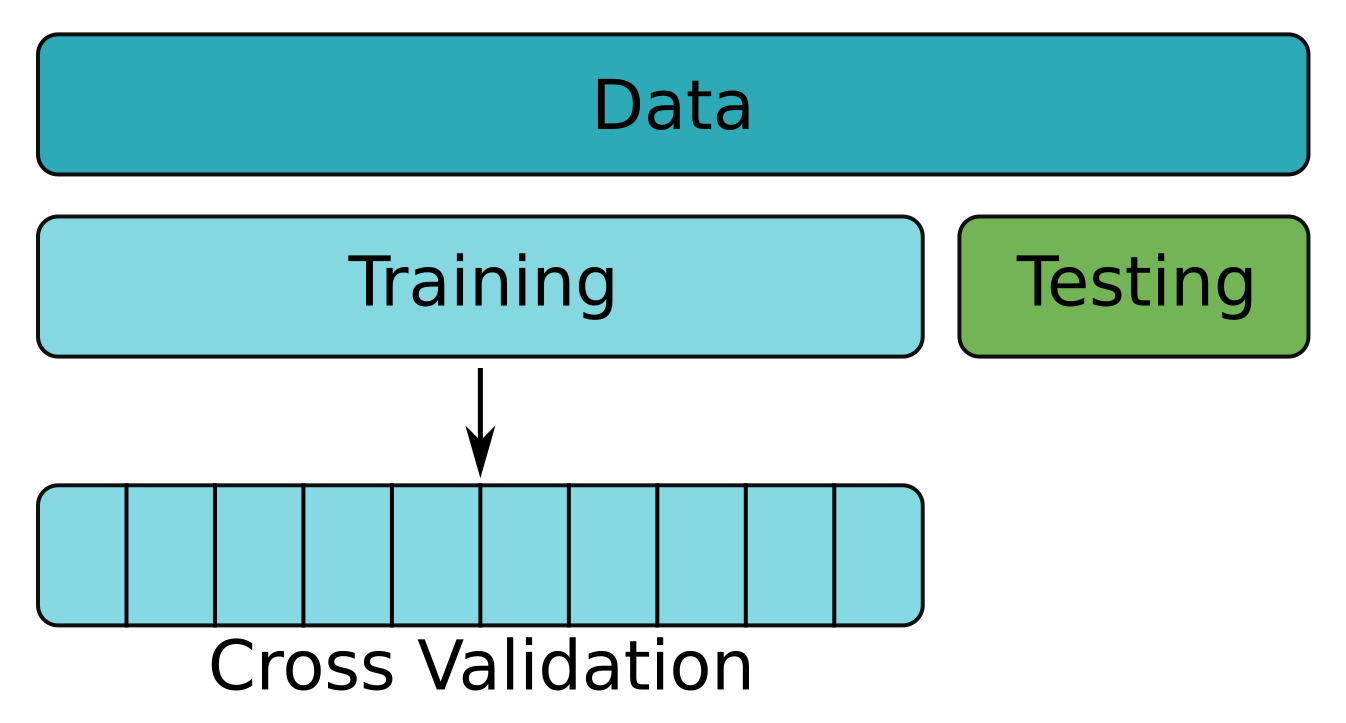
Fold na fold - eerste fold

Fold na fold - tweede fold
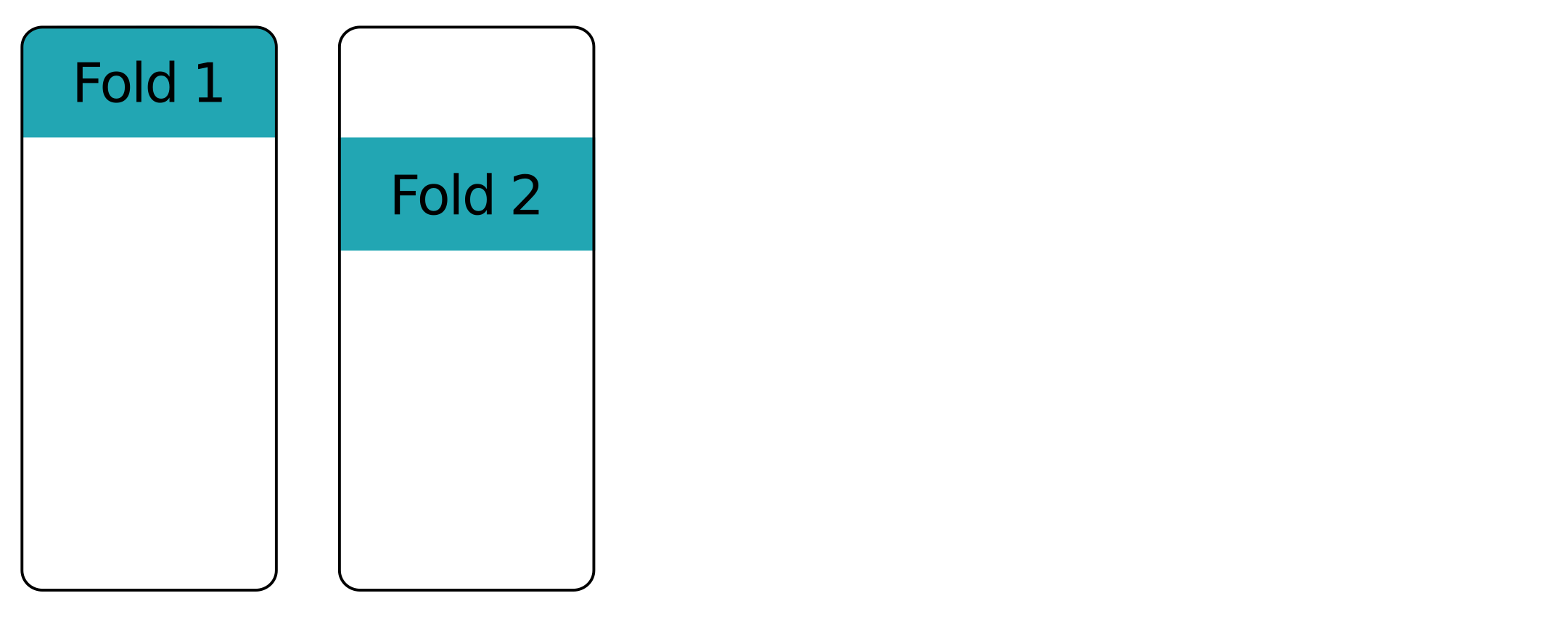
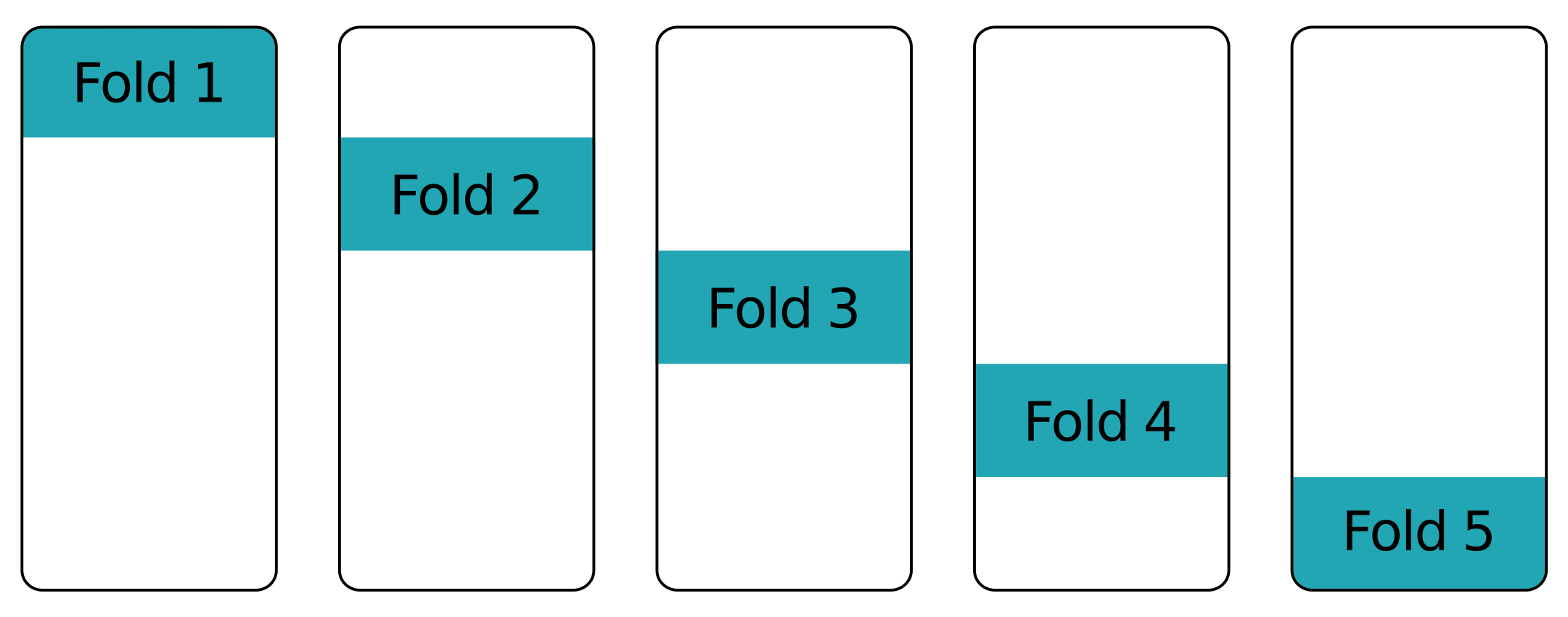
Fold na fold - overige folds
Machine Learning met PySpark
Andrew Collier
Data Scientist, Fathom Data

