Binning & feature engineering
Machine Learning met PySpark

Andrew Collier
Data Scientist, Fathom Data
Binning

Lengtes binnen
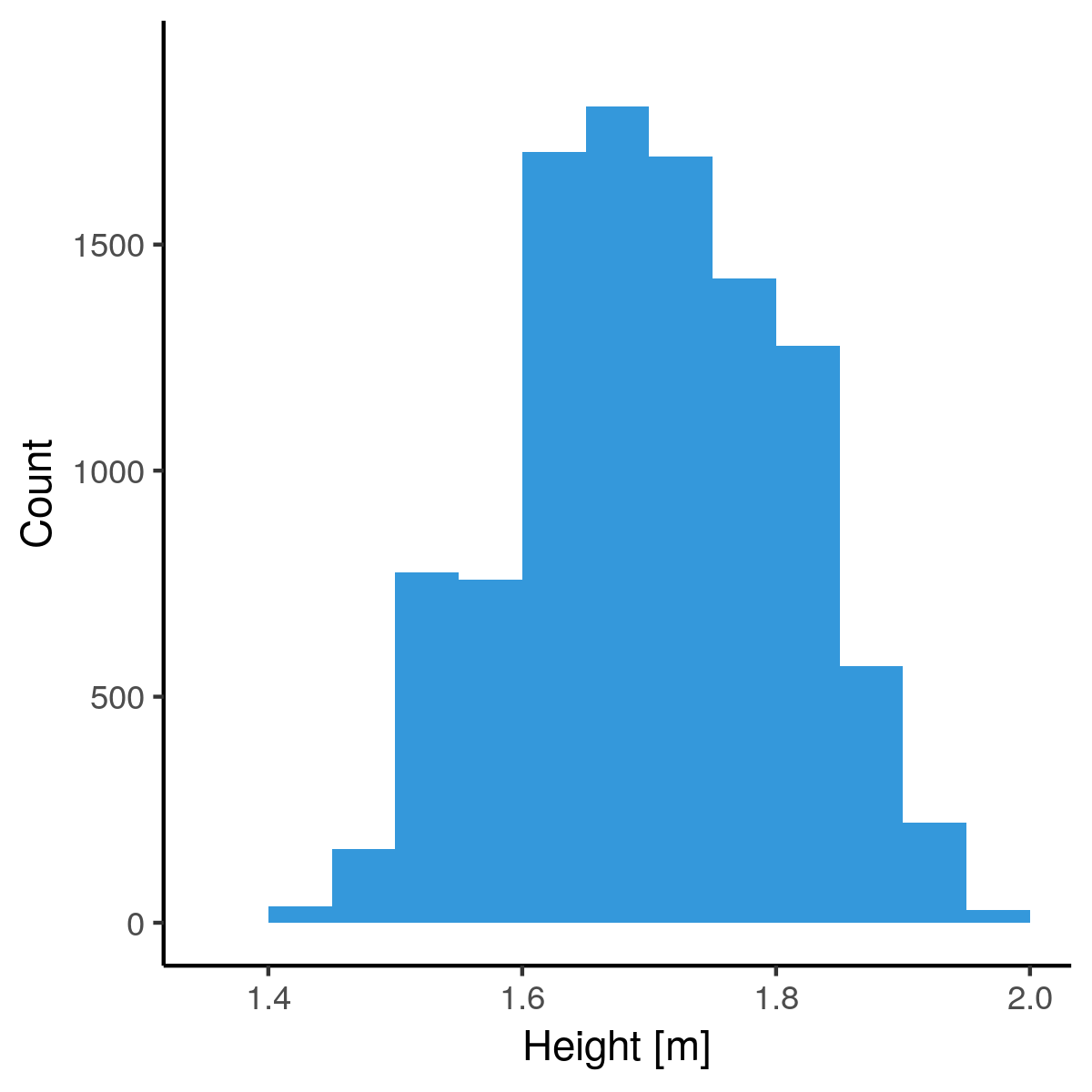
Lengtes binnen
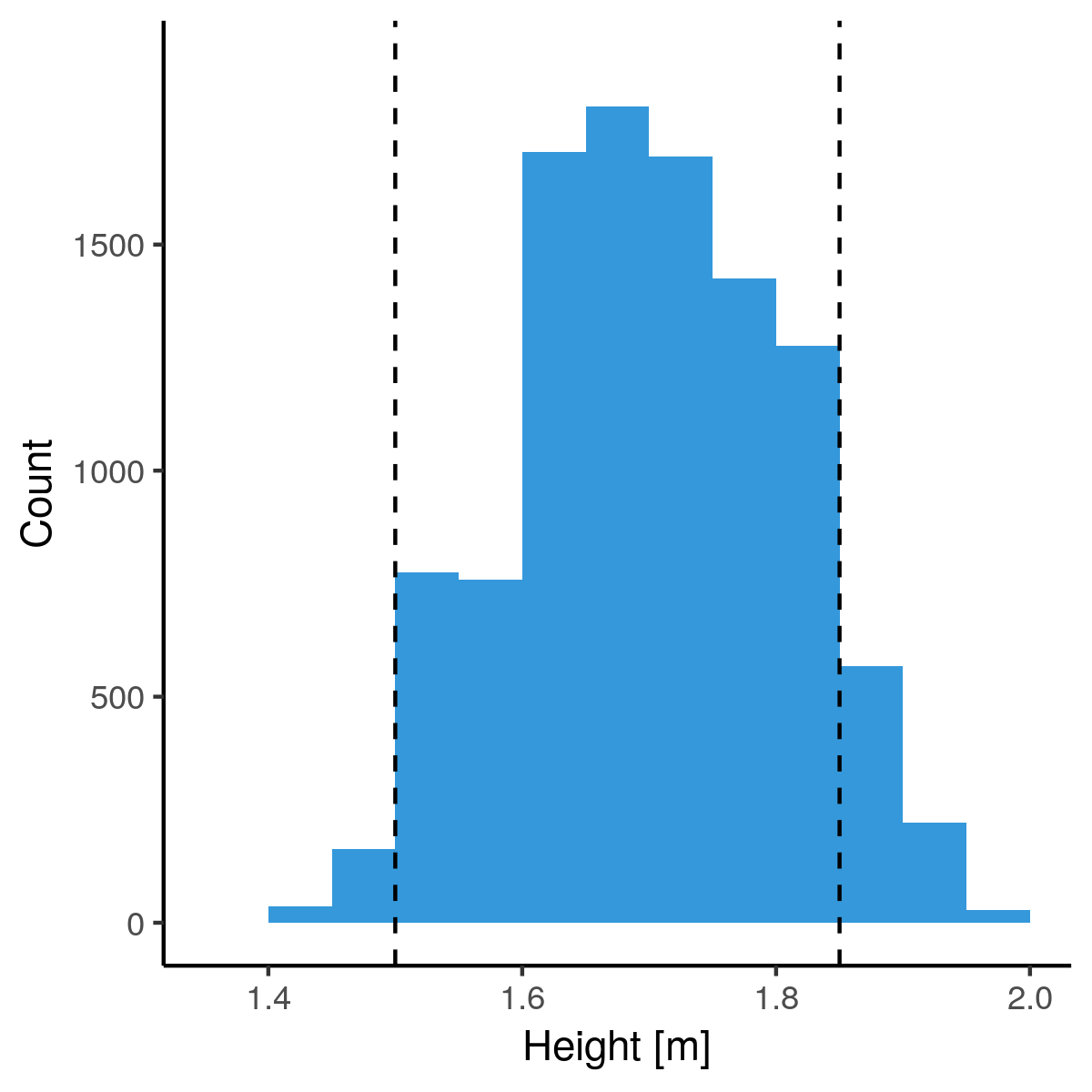
Lengtes binnen
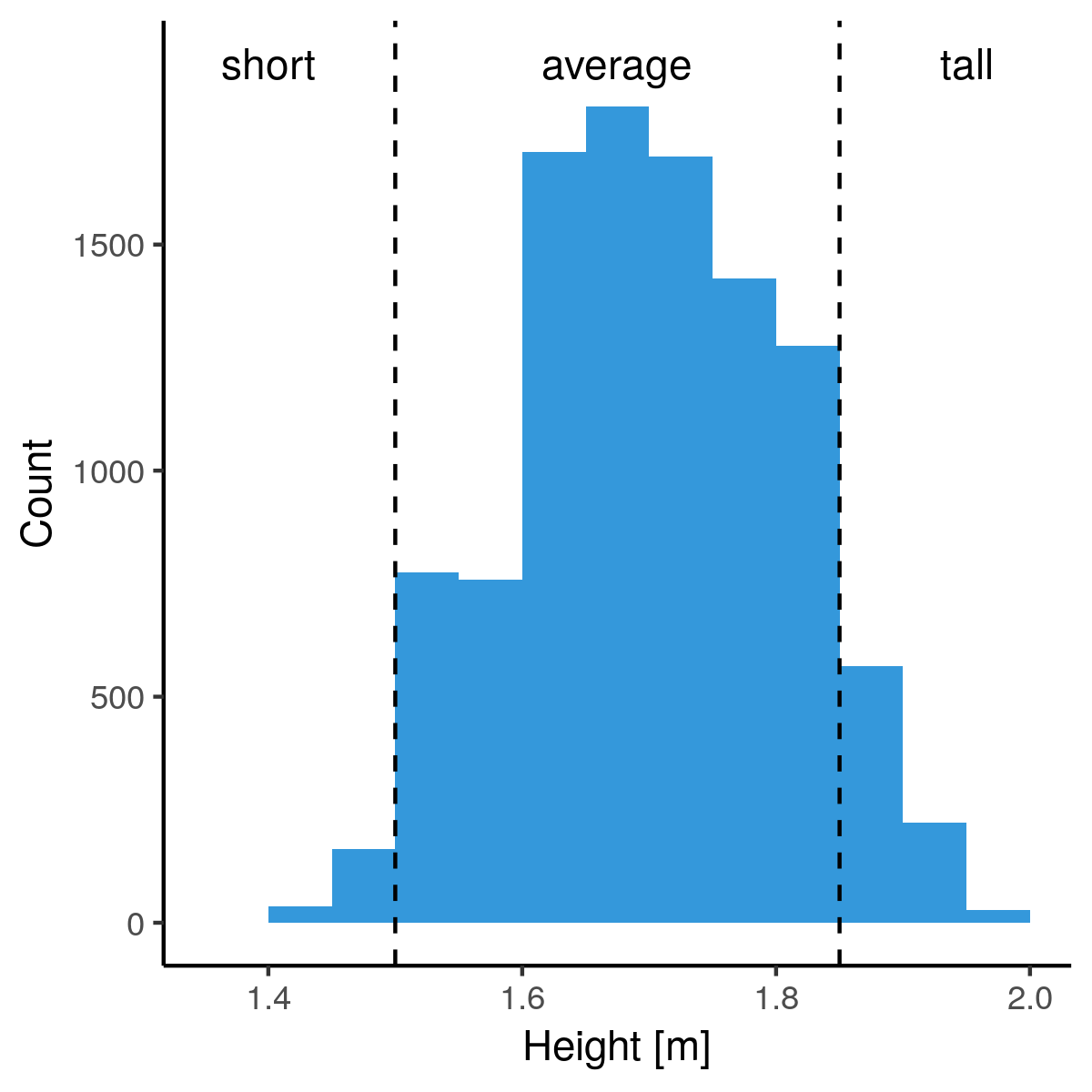
Lengtes binnen
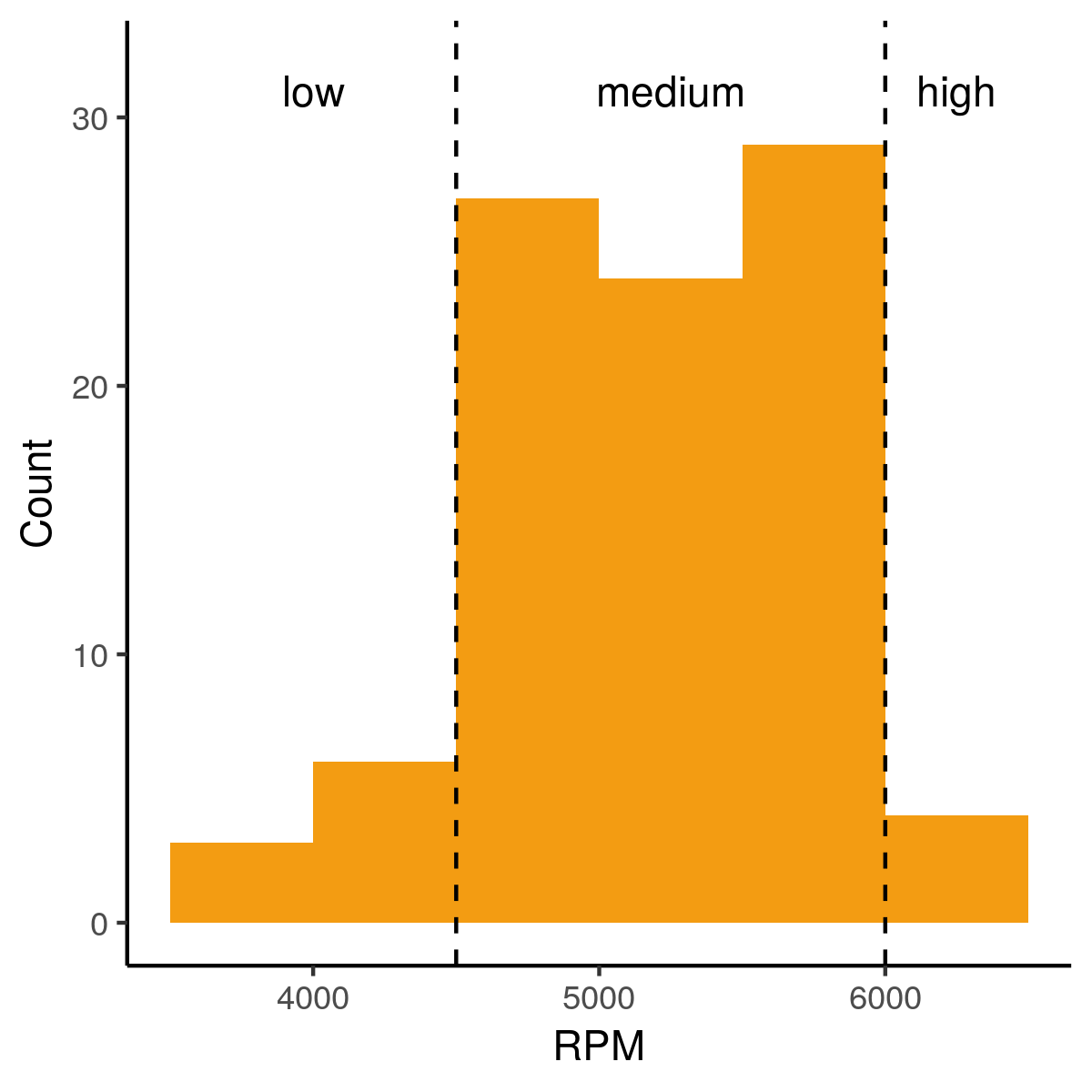
RPM-histogram
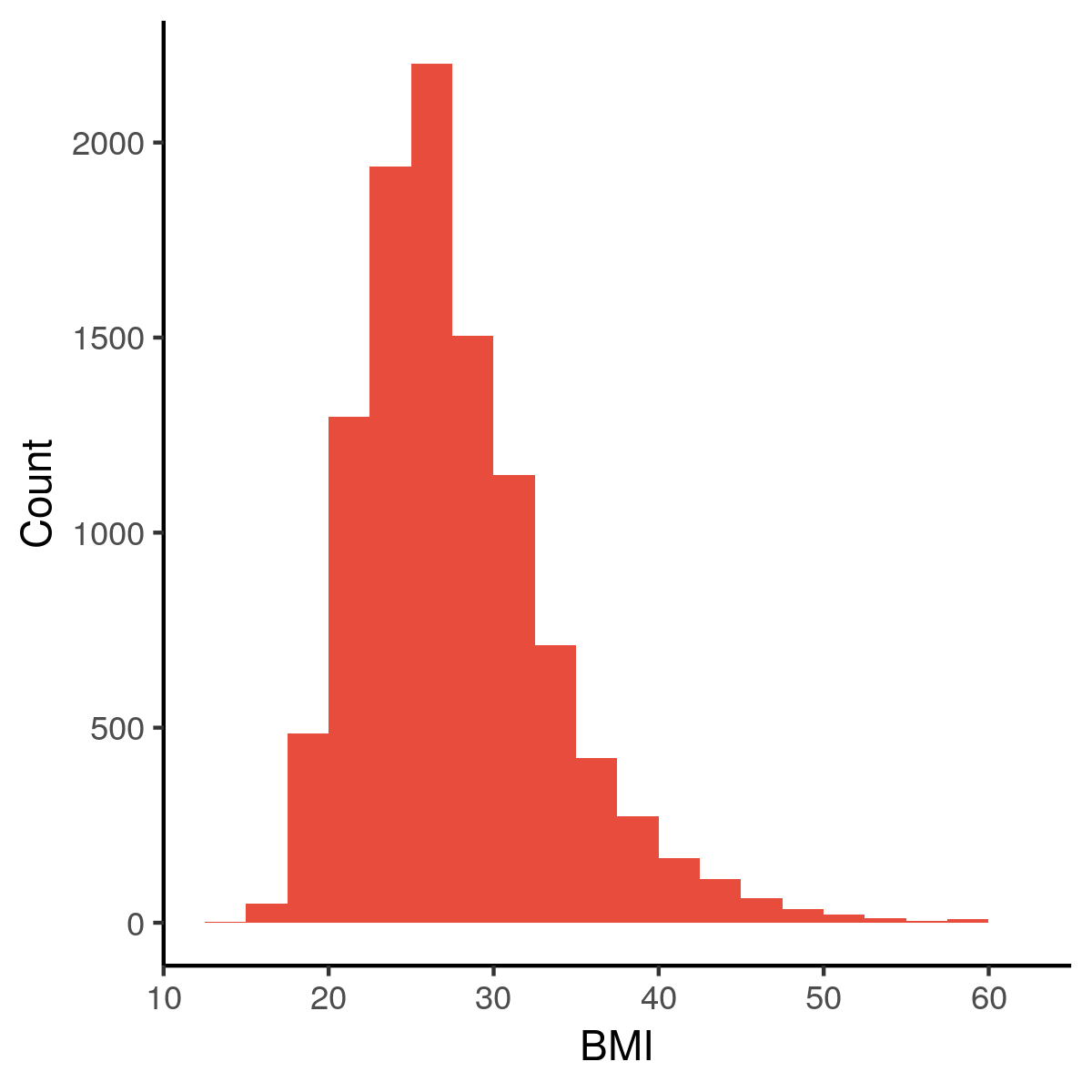
Massa & lengte naar BMI
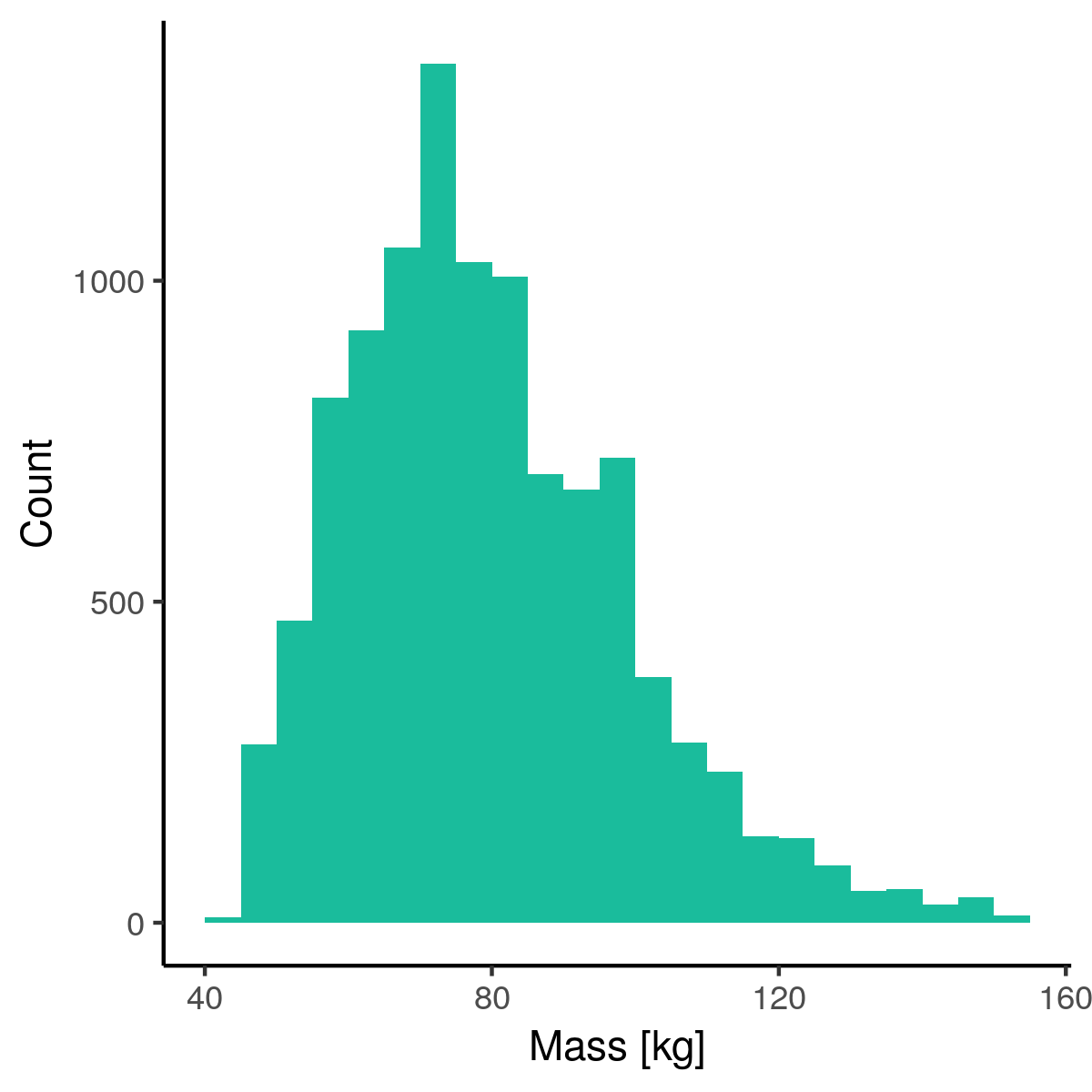
Massa & lengte naar BMI
Machine Learning met PySpark
Andrew Collier
Data Scientist, Fathom Data

