Best practices voor datavalidatie
Verantwoord AI-gegevensbeheer

Maria Prokofieva
Lead ML engineer
Subgroeponderzoek




Ontbrekende data
- Veelvoorkomend in grote datasets
- Data verwijderen
- Imputatiestrategieën en modelgebaseerde aanpakken
- Subgroeponderzoek voor validatie
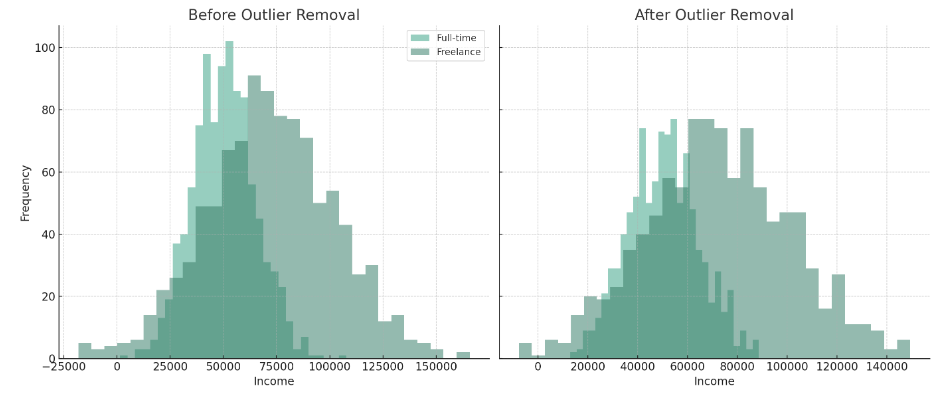
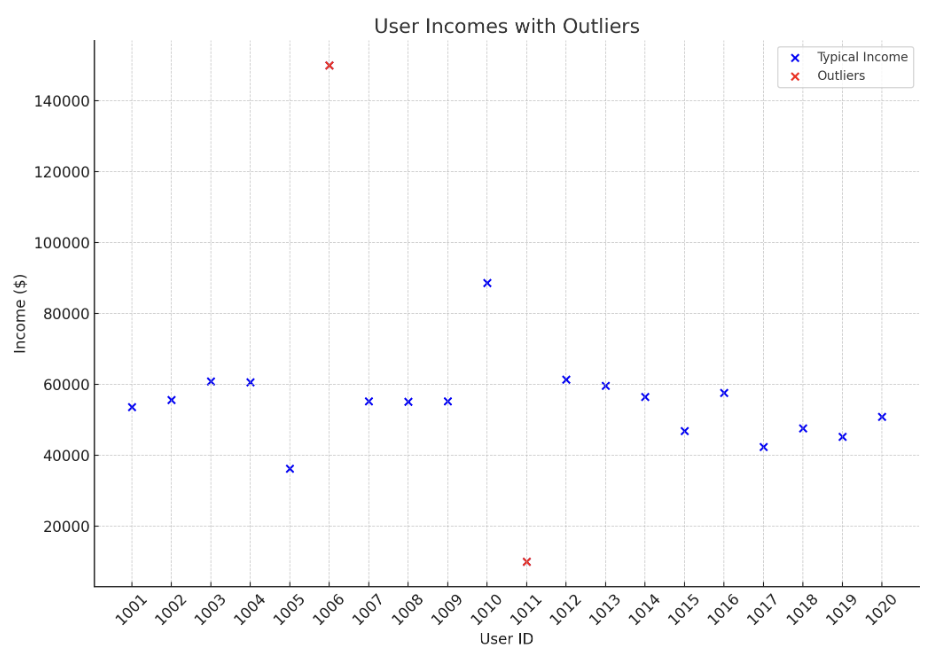
Uitschieters verwijderen
- Statistische methoden zoals z-scores en IQR, of robuuste schaling
- Valideer op eerlijke behandeling tussen segmenten
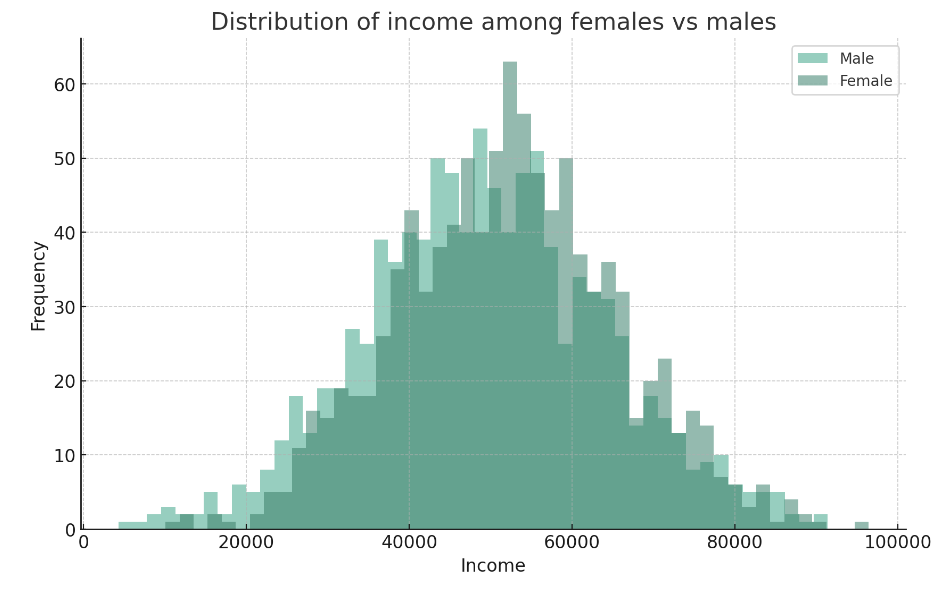
Feature scaling
- Feature scaling om invoerkenmerken te transformeren
- Valideer door verdelingen per groep te vergelijken
Dimensionality reduction
- Verminder features en behoud kerninformatie
- Kan bias introduceren
- Gebruik fairness-bewuste technieken zoals t-SNE
Financieel adviseur
- Features "Annual income" en "Investment frequency"
- Corrigeer uitschieters en schaal
- Subgroeponderzoek