Upserts batchen
Vector-databases voor embeddings met Pinecone

James Chapman
Curriculum Manager, DataCamp
Beperkingen bij upserts
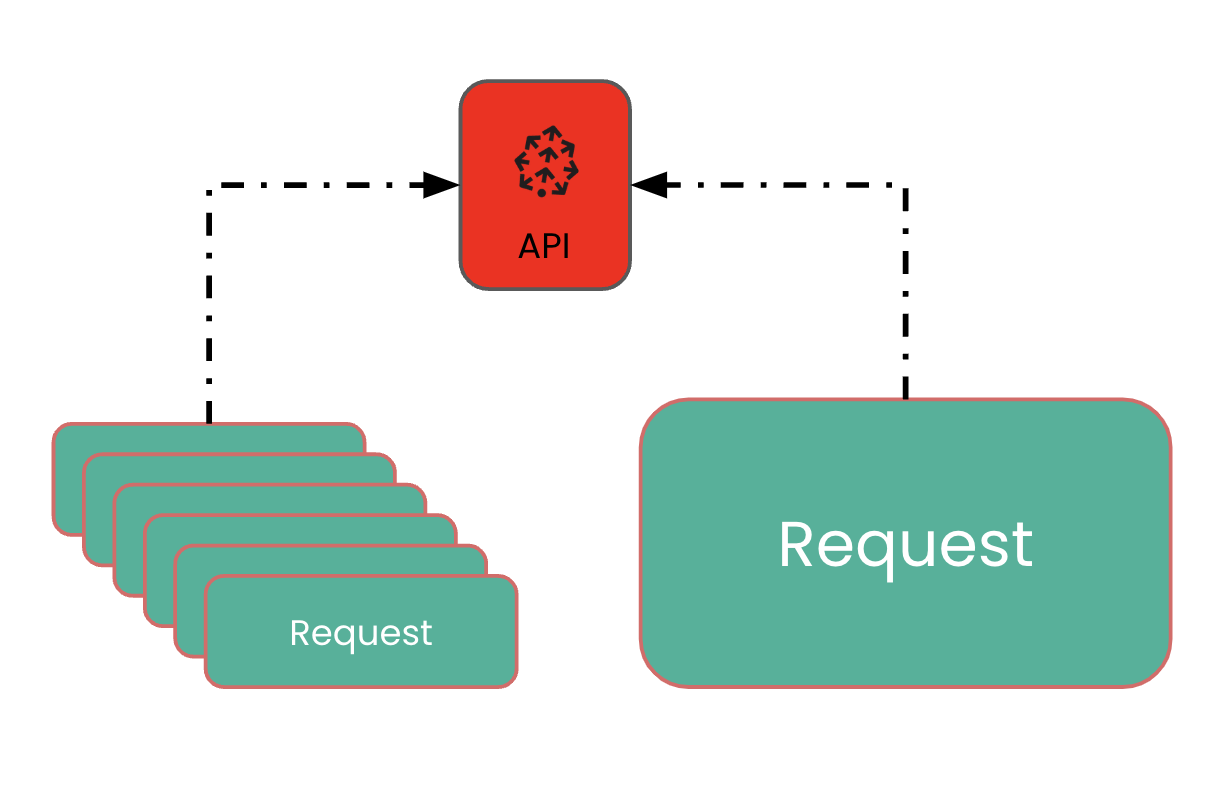
1 https://docs.pinecone.io/reference/quotas-and-limits#rate-limits
Vector-databases voor embeddings met Pinecone
James Chapman
Curriculum Manager, DataCamp

