Informed search: van grof naar fijn
Hyperparameter Tuning in Python

Alex Scriven
Data Scientist
Informed vs. uninformed
Het proces tot nu toe:
Een alternatieve manier:
Visualiseren: van grof naar fijn
We doen een random search op 500 combinaties.
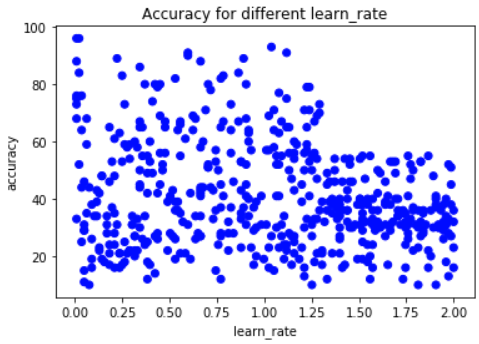
Hier plotten we de accuraciescores:
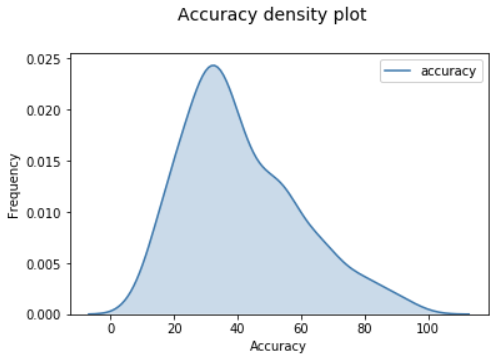
Welke modellen waren goed?
Visualiseren: van grof naar fijn
Visualiseer max_depth versus accuracyscore:
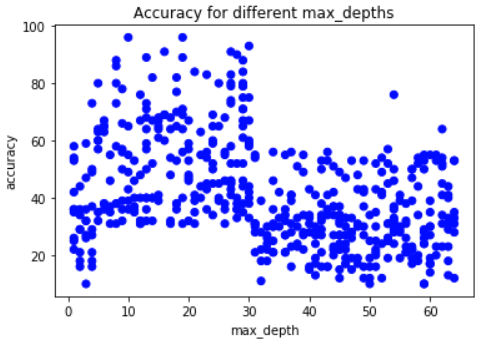
Visualiseren: van grof naar fijn
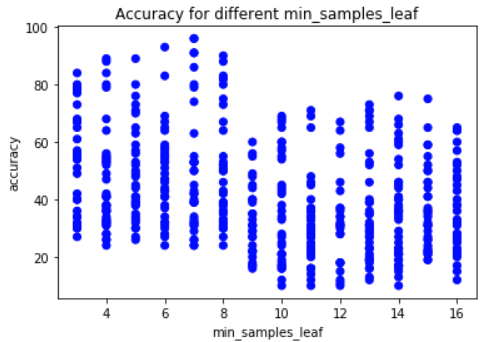
min_samples_leaf beter onder 8
learn_rate slechter boven 1.3