Introductie van grid search
Hyperparameter Tuning in Python

Alex Scriven
Data Scientist
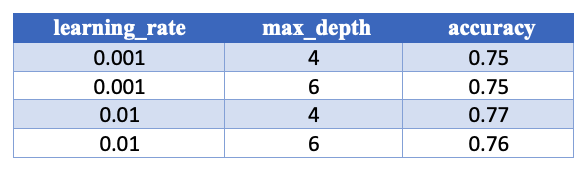
Automatiseren van 2 hyperparameters
We kunnen deze resultaten ook in een DataFrame zetten en printen:
results_df = pd.DataFrame(results_list, columns=['learning_rate', 'max_depth', 'accuracy'])
print(results_df)
Introductie van grid search
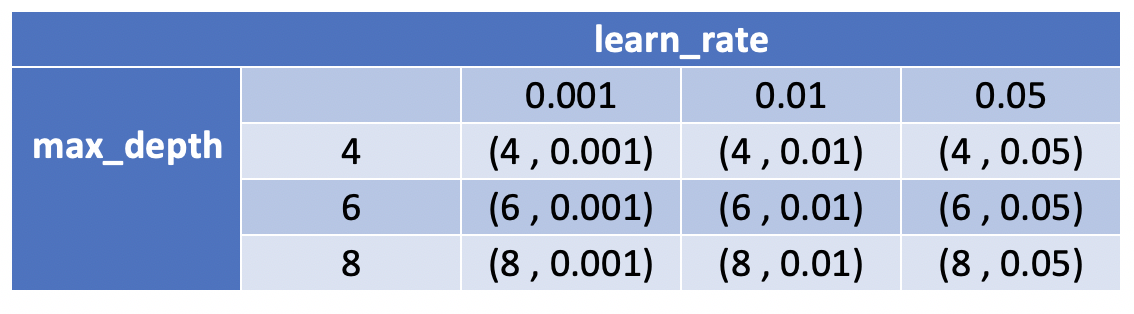
Laten we een grid maken:
- Links alle waarden van max_depth
- Bovenaan alle waarden van learning_rate
Introductie van grid search
Werk cel voor cel door het grid:
(4,0.001) komt overeen met deze estimator:
GradientBoostingClassifier(max_depth=4, learning_rate=0.001)

