Introductie van random search
Hyperparameter Tuning in Python

Alex Scriven
Data Scientist
Een kansreken-truc
Een grid search:
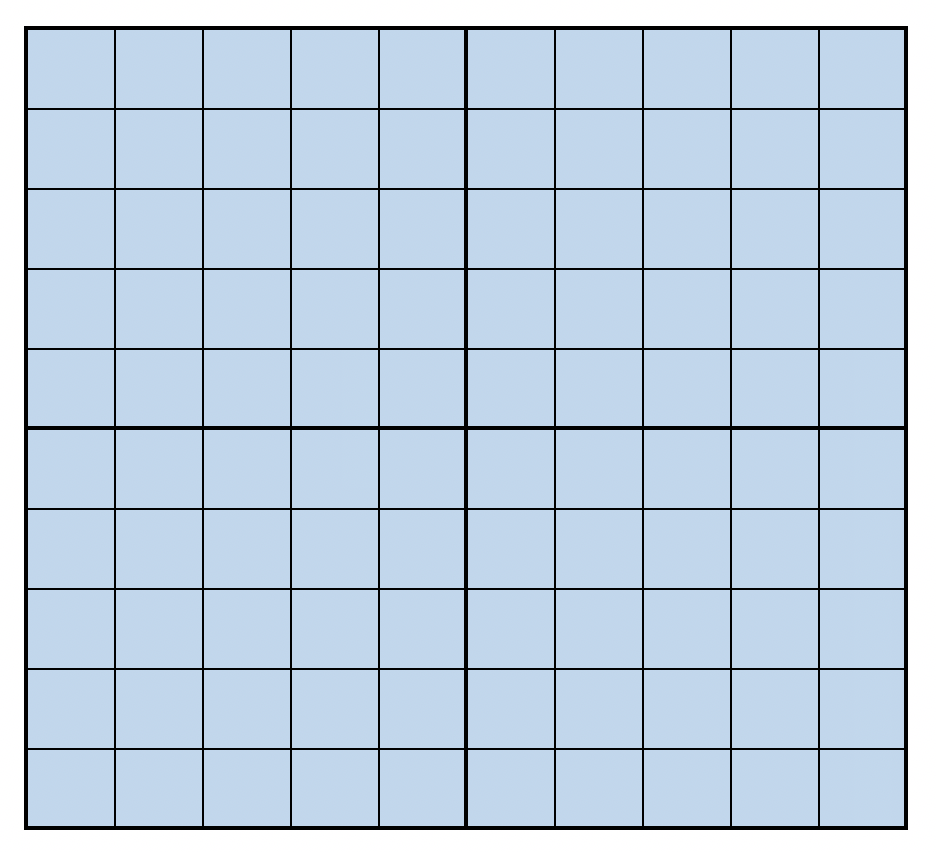
Hoeveel modellen moeten we draaien om 95% kans te hebben op een van de groene vakjes?
Onze beste modellen:
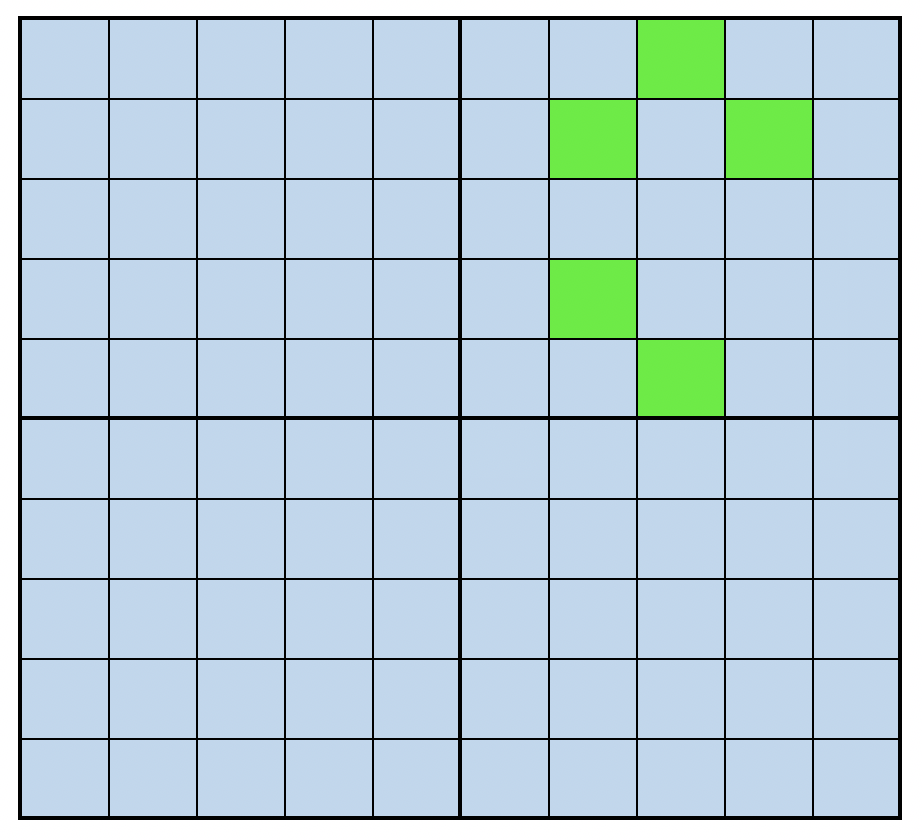
Random search visualiseren
We kunnen de dekking van random search ook visualiseren door de hyperparameterkeuzes op X- en Y-as te plotten.
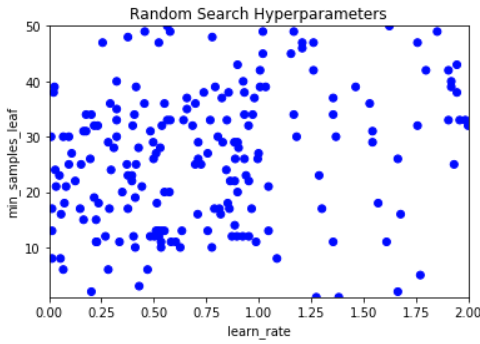
Zie je de brede spreiding maar geen diepe dekking?

