Een gridsearch-uitvoer begrijpen
Hyperparameter Tuning in Python

Alex Scriven
Data Scientist
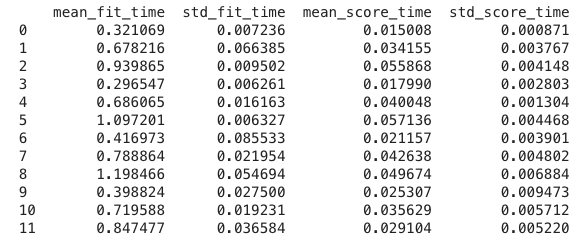
De .cv_results_ 'time'-kolommen
De time-kolommen geven de tijd voor fitten (en scoren) aan.
We deden 5-fold cross-validatie. Dit draaide 5 keer en sloeg gemiddelde en standaardafwijking in seconden op.
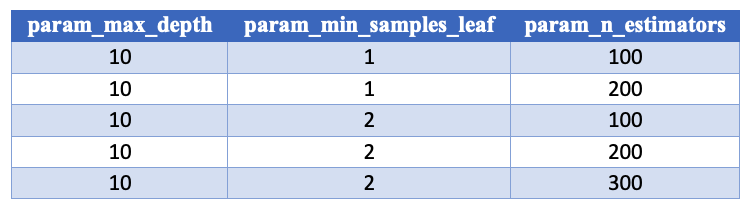
De .cv_results_ 'param_'‑kolommen
De param_-kolommen slaan per rij de geteste parameters op, één kolom per parameter.
De .cv_results_ 'param'-kolom
De kolom params bevat een dictionary met alle parameters:
pd.set_option("display.max_colwidth", -1)
print(cv_results_df.loc[:, "params"])

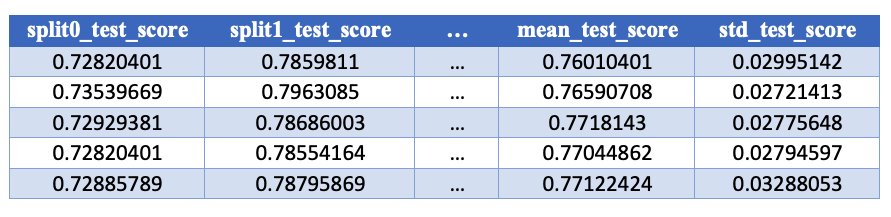
De .cv_results_ 'test_score'-kolommen
De test_score-kolommen bevatten de scores op onze testset per fold plus samenvattingsstatistieken:
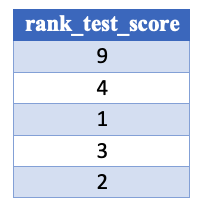
De .cv_results_ 'rank_test_score'-kolom
De rangkolom ordent de mean_test_score van best naar slechtst:
De beste rij extraheren
Selecteer de beste gridcel eenvoudig uit cv_results_ met de kolom rank_test_score
best_row = cv_results_df[cv_results_df["rank_test_score"] == 1]
print(best_row)

De property best_estimator_
print(grid_rf_class.best_estimator_)


