Grid search met Scikit Learn
Hyperparameter Tuning in Python

Alex Scriven
Data Scientist
GridSearchCV-object
Introductie van een GridSearchCV-object:
sklearn.model_selection.GridSearchCV(
estimator,
param_grid, scoring=None, fit_params=None,
n_jobs=None, refit=True, cv='warn',
verbose=0, pre_dispatch='2*n_jobs',
error_score='raise-deprecating',
return_train_score='warn')
Stappen van een grid search
Stappen van een grid search:
- Een algoritme om hyperparameters te tunen (een ‘estimator’)
- Bepalen welke hyperparameters we tunen
- Een waardenbereik per hyperparameter definiëren
- Een kruisvalidatieschema instellen; en
- Een scorefunctie kiezen om te bepalen welk vakje ‘het beste’ is
- Extra nuttige info of functies toevoegen
GridSearchCV-objectinputs
Belangrijke inputs:
estimatorparam_gridcvscoringrefitn_jobsreturn_train_score
GridSearchCV 'estimator'
De input estimator:
- In feite ons algoritme
- Je hebt al gewerkt met KNN, Random Forest, GBM, Logistic Regression
Onthoud:
- Slechts één estimator per GridSearchCV-object
GridSearchCV 'param_grid'
De input param_grid:
- Bepaalt welke hyperparameters en waarden je test
In plaats van lijsten:
max_depth_list = [2, 4, 6, 8]
min_samples_leaf_list = [1, 2, 4, 6]
Dit wordt:
param_grid = {'max_depth': [2, 4, 6, 8],
'min_samples_leaf': [1, 2, 4, 6]}
GridSearchCV 'param_grid'
De input param_grid:
Onthoud: de keys in je param_grid-dictionary moeten geldige hyperparameters zijn.
Bijv. voor een Logistic Regression-estimator:
# Incorrect
param_grid = {'C': [0.1,0.2,0.5],
'best_choice': [10,20,50]}
ValueError: Invalid parameter best_choice for estimator LogisticRegression
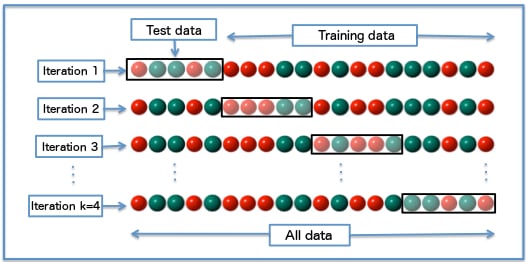
GridSearchCV 'cv'
De input cv:
- Keuze van kruisvalidatie
- Een geheel getal gebruikt k-fold cross-validation; 5 of 10 is gangbaar
GridSearchCV 'scoring'
De input scoring:
- Welke score je gebruikt om het beste vakje (model) te kiezen
- Gebruik je eigen of Scikit Learn’s
metrics-module
Alle ingebouwde scoringfuncties bekijken:
from sklearn import metrics
sorted(metrics.SCORERS.keys())
GridSearchCV 'refit'
De input refit:
- Past de beste hyperparameters op de trainingsdata toe
- Maakt de
GridSearchCV-object bruikbaar als estimator (voor predictie) - Erg handig!
GridSearchCV 'n_jobs'
De input n_jobs:
- Helpt met parallelle uitvoering
- Laat meerdere modellen tegelijk trainen i.p.v. na elkaar
Handige code:
import os
print(os.cpu_count())
Let op met al je cores gebruiken als je ook ander werk wilt doen!
GridSearchCV 'return_train_score'
De input return_train_score:
- Logt statistieken over de uitgevoerde trainingsruns
- Handig voor bias-variance-analyse, maar kost extra rekenwerk
- Helpt niet bij het kiezen van het beste model; alleen voor analyse
Een GridSearchCV-object bouwen
Een eigen GridSearchCV-object bouwen:
# Create the grid param_grid = {'max_depth': [2, 4, 6, 8], 'min_samples_leaf': [1, 2, 4, 6]}#Get a base classifier with some set parameters. rf_class = RandomForestClassifier(criterion='entropy', max_features='auto')
Een GridSearchCV-object bouwen
Alles samenvoegen:
grid_rf_class = GridSearchCV(
estimator = rf_class,
param_grid = parameter_grid,
scoring='accuracy',
n_jobs=4,
cv = 10,
refit=True,
return_train_score=True)
Een GridSearchCV-object gebruiken
Omdat we refit op True zetten, kunnen we het object direct gebruiken:
#Fit the object to our data
grid_rf_class.fit(X_train, y_train)
# Make predictions
grid_rf_class.predict(X_test)
Laten we oefenen!
Hyperparameter Tuning in Python

