Random Search in Scikit-learn
Hyperparameter Tuning in Python

Alex Scriven
Data Scientist
Vergelijken met GridSearchCV
We hoeven het wiel niet opnieuw uit te vinden. Herhaal de stappen voor Grid Search:
- Kies een algoritme/estimator
- Bepaal welke hyperparameters je afstemt
- Bepaal een waardebereik per hyperparameter
- Stel een cross-validatieschema in; en
- Kies een scorefunctie
- Voeg extra nuttige info of functies toe
Vergelijken met Grid Search
Er is maar één verschil:
- Stap 7 = Bepaal hoeveel samples je neemt (en sample)
Dat is alles! (meestal)
Scikit-learn-modules vergelijken
De modules lijken ook op elkaar:
GridSearchCV:
sklearn.model_selection.GridSearchCV(estimator, param_grid,
scoring=None, fit_params=None,
n_jobs=None,
refit=True, cv='warn', verbose=0,
pre_dispatch='2*n_jobs',
error_score='raise-deprecating',
return_train_score='warn')
RandomizedSearchCV:
sklearn.model_selection.RandomizedSearchCV(estimator,
param_distributions, n_iter=10,
scoring=None, fit_params=None,
n_jobs=None, refit=True,
cv='warn', verbose=0,
pre_dispatch='2*n_jobs',
random_state=None,
error_score='raise-deprecating',
return_train_score='warn')
Belangrijkste verschillen
Twee belangrijke verschillen:
n_iteris het aantal samples dat de random search uit je grid neemt. In het vorige voorbeeld deed je er 300.param_distributionsverschilt licht vanparam_griden laat optioneel een verdeling voor sampling toe.- Standaard heeft elke combinatie evenveel kans om gekozen te worden.
Bouw een RandomizedSearchCV-object
Nu kunnen we een random search-object bouwen zoals bij grid search, maar met onze kleine aanpassing:
# Set up the sample space learn_rate_list = np.linspace(0.001,2,150) min_samples_leaf_list = list(range(1,51)) # Create the grid parameter_grid = { 'learning_rate' : learn_rate_list, 'min_samples_leaf' : min_samples_leaf_list}# Define how many samples number_models = 10
Bouw een RandomizedSearchCV-object
Nu kunnen we het object bouwen
# Create a random search object
random_GBM_class = RandomizedSearchCV(
estimator = GradientBoostingClassifier(),
param_distributions = parameter_grid,
n_iter = number_models,
scoring='accuracy',
n_jobs=4,
cv = 10,
refit=True,
return_train_score = True)
# Fit the object to our data
random_GBM_class.fit(X_train, y_train)
Analyseer de output
De output is precies hetzelfde!
Hoe zie je welke hyperparameters zijn gekozen?
De cv_results_-dictionary (in de relevante param_-kolommen)!
Haal de lijsten op:
rand_x = list(random_GBM_class.cv_results_['param_learning_rate'])
rand_y = list(random_GBM_class.cv_results_['param_min_samples_leaf'])
Analyseer de output
Bouw onze visualisatie:
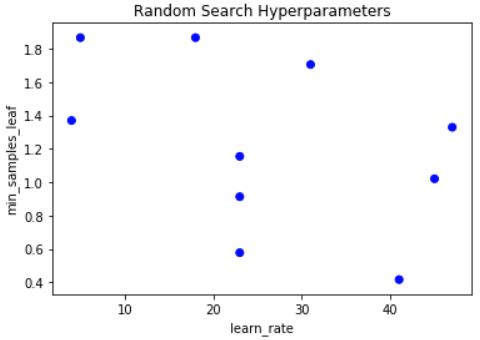
# Make sure we set the limits of Y and X appriately x_lims = [np.min(learn_rate_list), np.max(learn_rate_list)] y_lims = [np.min(min_samples_leaf_list), np.max(min_samples_leaf_list)]# Plot grid results plt.scatter(rand_y, rand_x, c=['blue']*10) plt.gca().set(xlabel='learn_rate', ylabel='min_samples_leaf', title='Random Search Hyperparameters') plt.show()
Analyseer de output
Een vergelijkbare grafiek als eerder:
Laten we oefenen!
Hyperparameter Tuning in Python

