Methoden voor het verzamelen van feedback van hoge kwaliteit
Reinforcement Learning from Human Feedback (RLHF)

Mina Parham
AI Engineer
Methoden voor het verzamelen van feedback van hoge kwaliteit
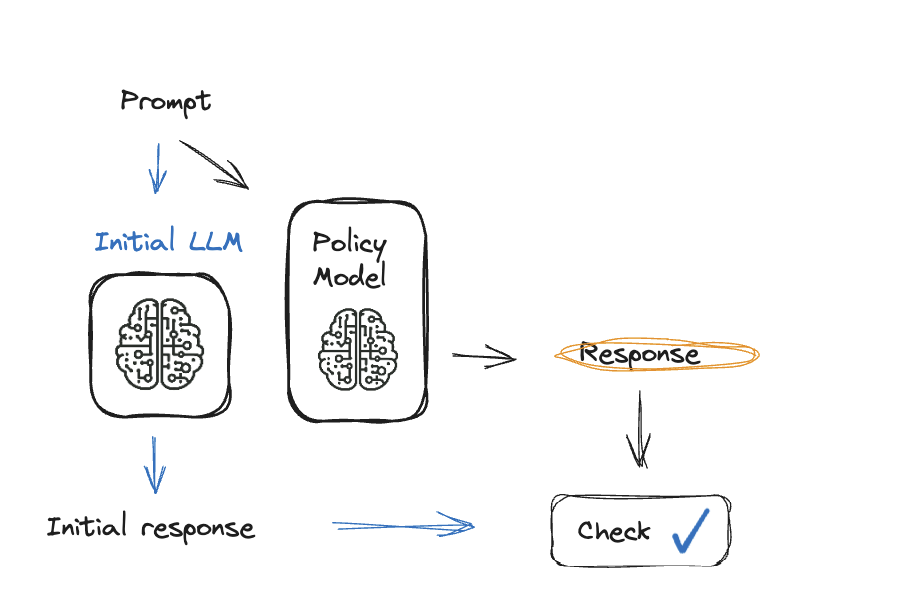
Methoden voor het verzamelen van feedback van hoge kwaliteit

Paargewijze vergelijkingen

Beoordelingen

Psychologische factoren

Richtlijnen voor het verzamelen van feedback van hoge kwaliteit


