Efficiënt finetunen in RLHF
Reinforcement Learning from Human Feedback (RLHF)

Mina Parham
AI Engineer
Parameter-efficiënt finetunen
- Een volledig model finetunen
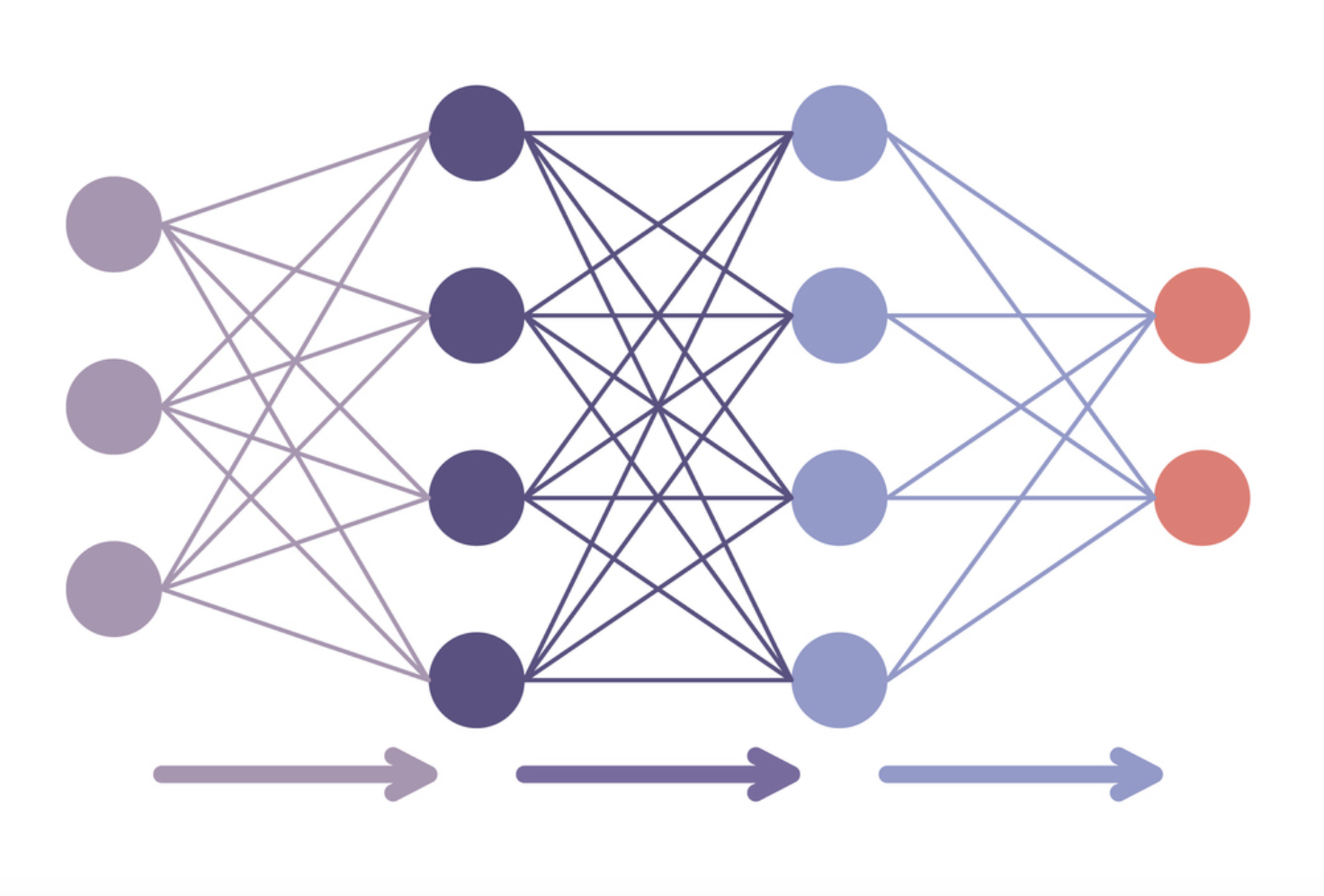
Parameter-efficiënt finetunen
- Finetunen met PEFT
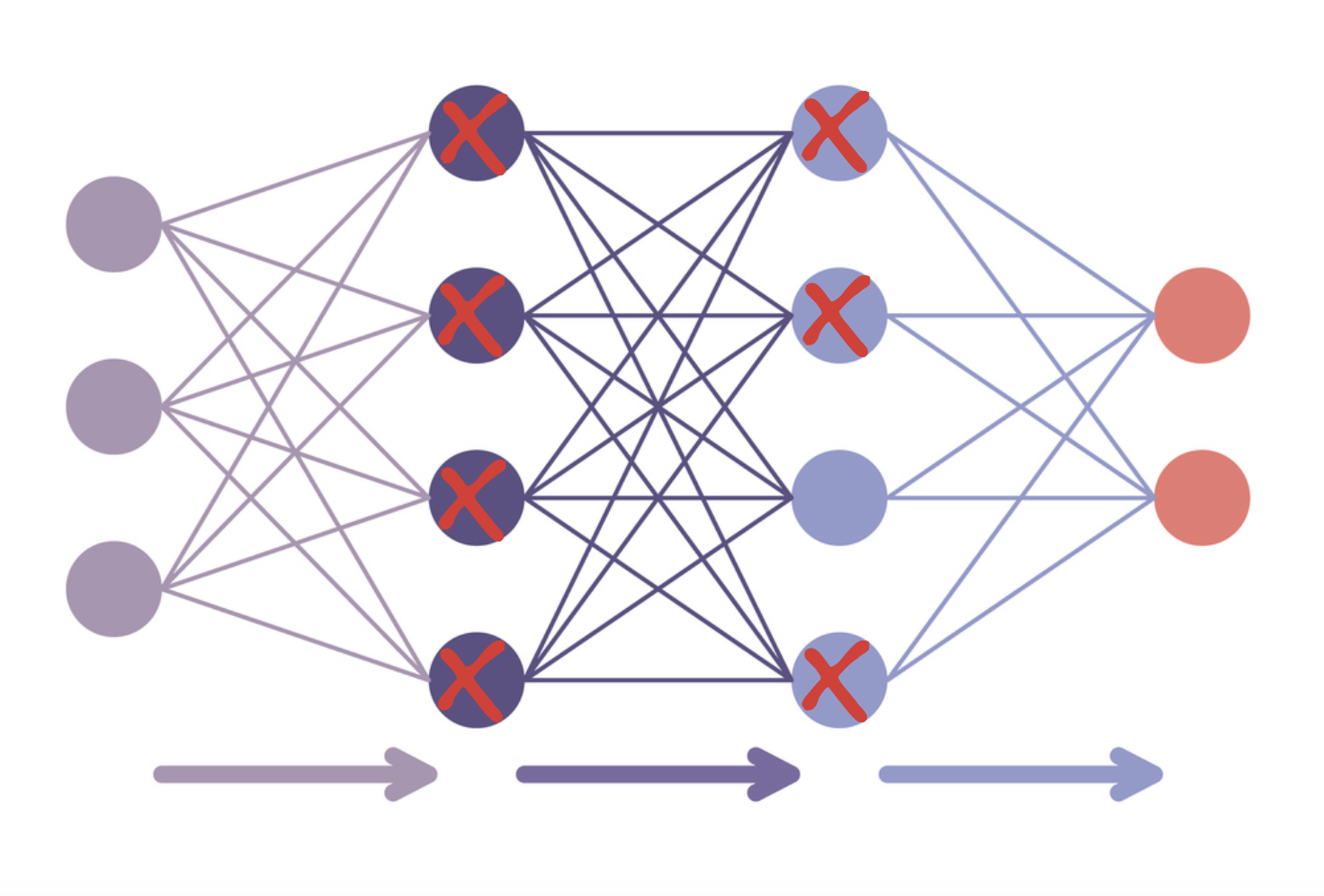
- LoRA: past slechts enkele lagen aan
- Kwantisatie: verlaagt datatype-precisie

