Voorgetrainde LLM’s verkennen
Reinforcement Learning from Human Feedback (RLHF)

Mina Parham
AI Engineer
Waarom fine-tunen belangrijk is
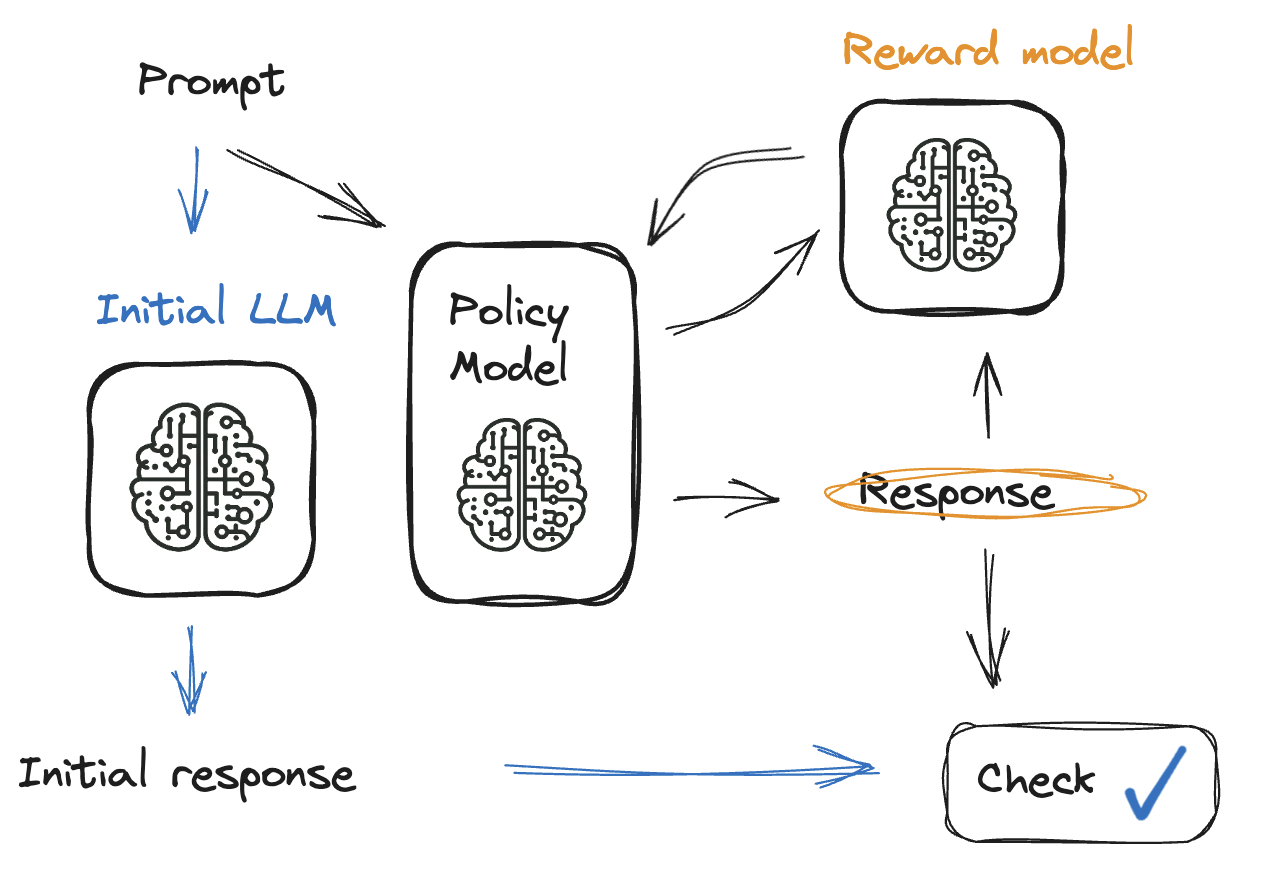
Waarom fine-tunen belangrijk is

Stapsgewijs fine-tunen van een LLM
Stapsgewijs fine-tunen van een LLM
Stapsgewijs fine-tunen van een LLM