Introductie tot RLHF
Reinforcement Learning from Human Feedback (RLHF)

Mina Parham
AI Engineer
Welkom bij de cursus!
- Onderwerp: Reinforcement Learning from Human Feedback (RLHF)

Welkom bij de cursus!
- Onderwerp: Reinforcement Learning from Human Feedback (RLHF)
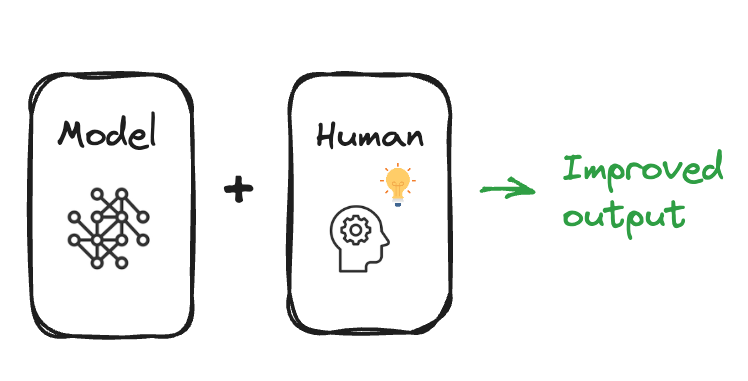
Herhaling reinforcement learning
Herhaling reinforcement learning

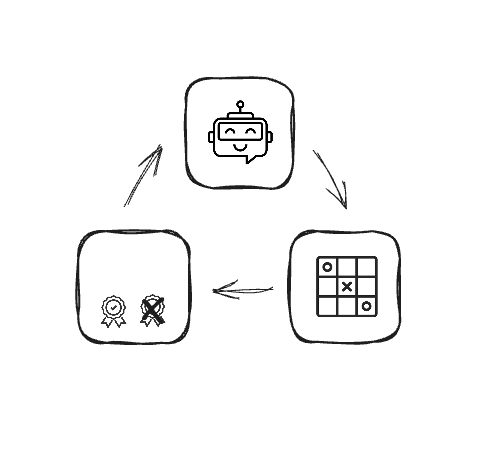
Herhaling reinforcement learning
Herhaling reinforcement learning
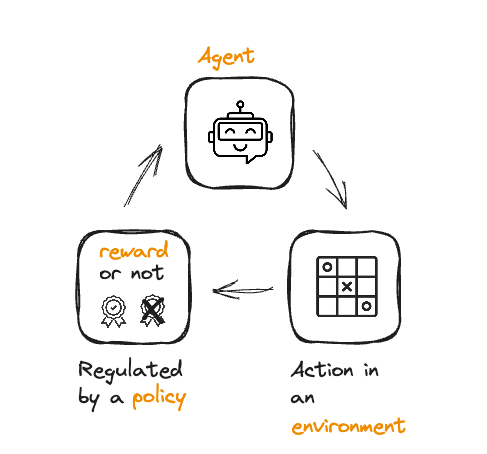
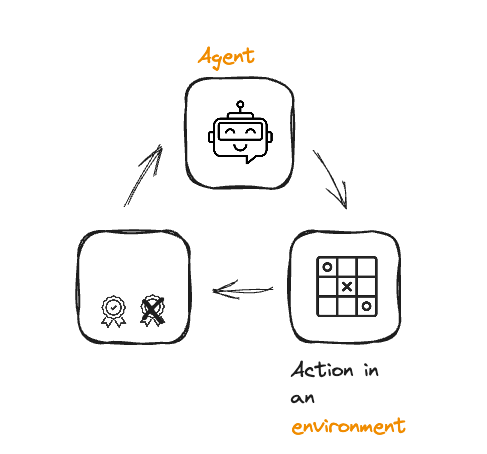
Van RL naar RLHF

Van RL naar RLHF
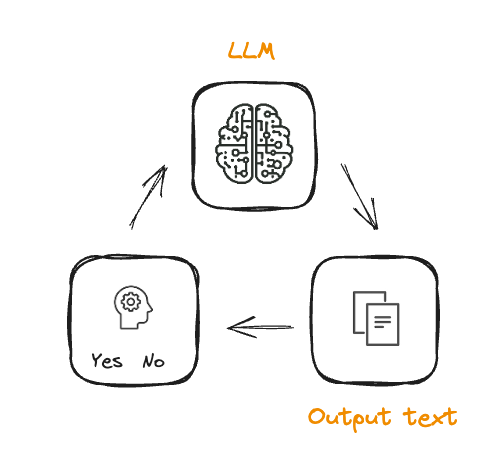
Van RL naar RLHF
- Trainen van het beloningsmodel
- Afstemmen op menselijke voorkeuren

LLM-finetuning in RLHF
LLM-finetuning in RLHF

Het volledige RLHF-proces

Het volledige RLHF-proces

Het volledige RLHF-proces

Het volledige RLHF-proces

Het volledige RLHF-proces
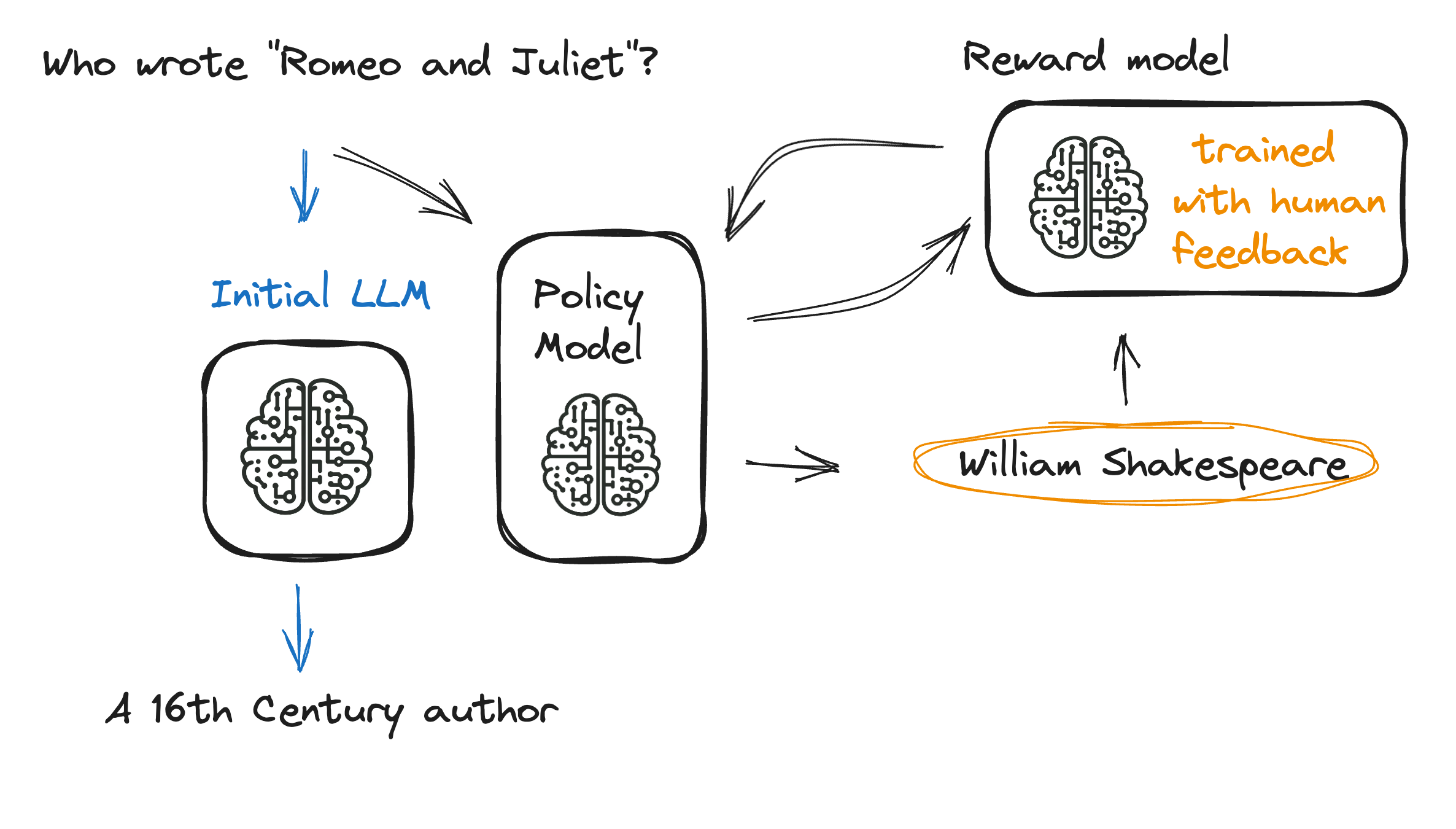
Het volledige RLHF-proces


