Trainen met PPO
Reinforcement Learning from Human Feedback (RLHF)

Mina Parham
AI Engineer
Fine-tunen met reinforcement learning
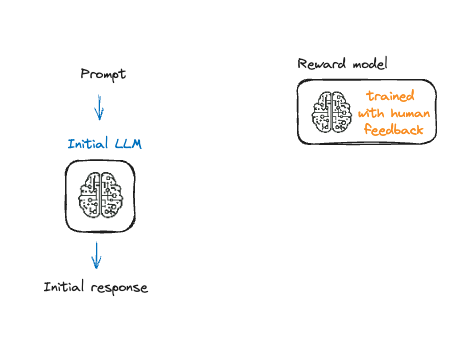
Fine-tunen met reinforcement learning
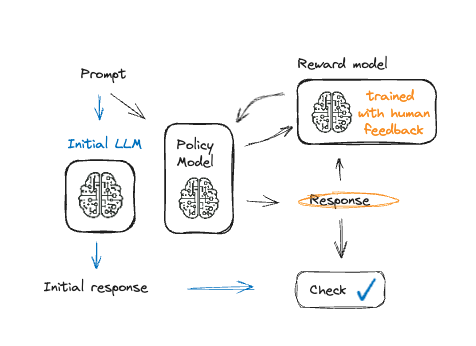
Een taalmodel fine-tunen met PPO
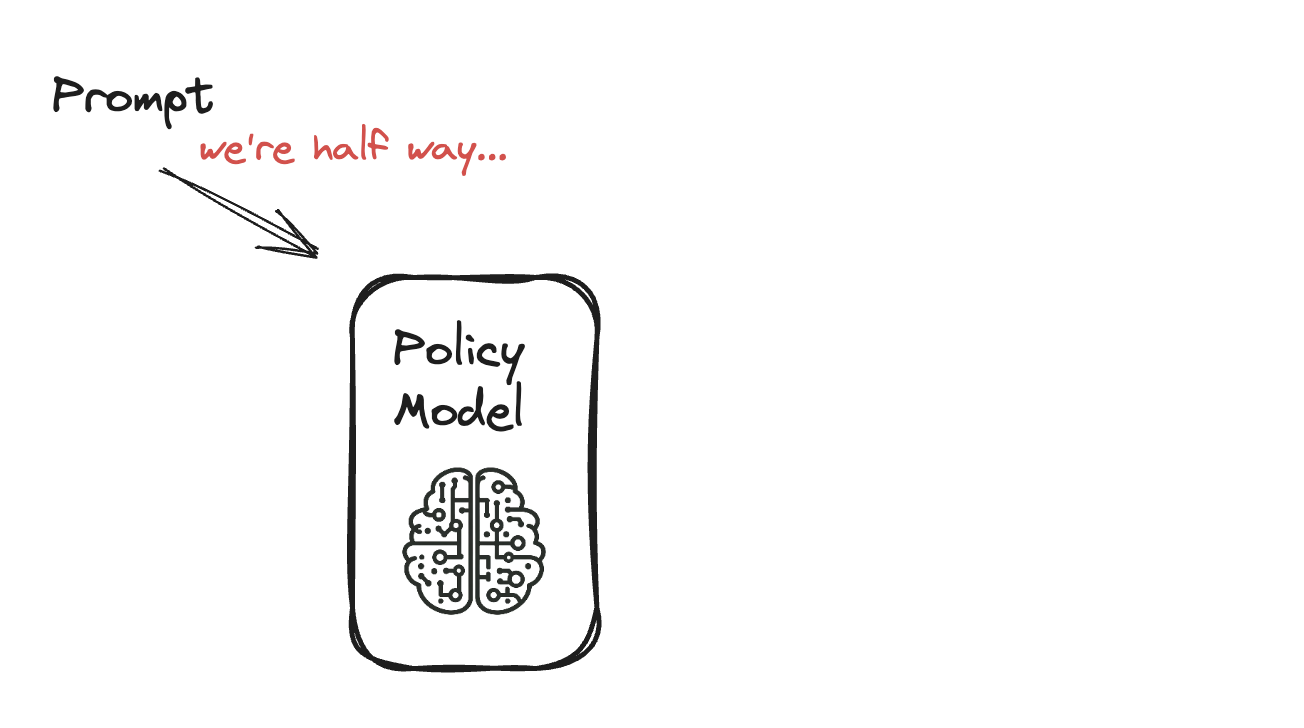
Een taalmodel fine-tunen met PPO
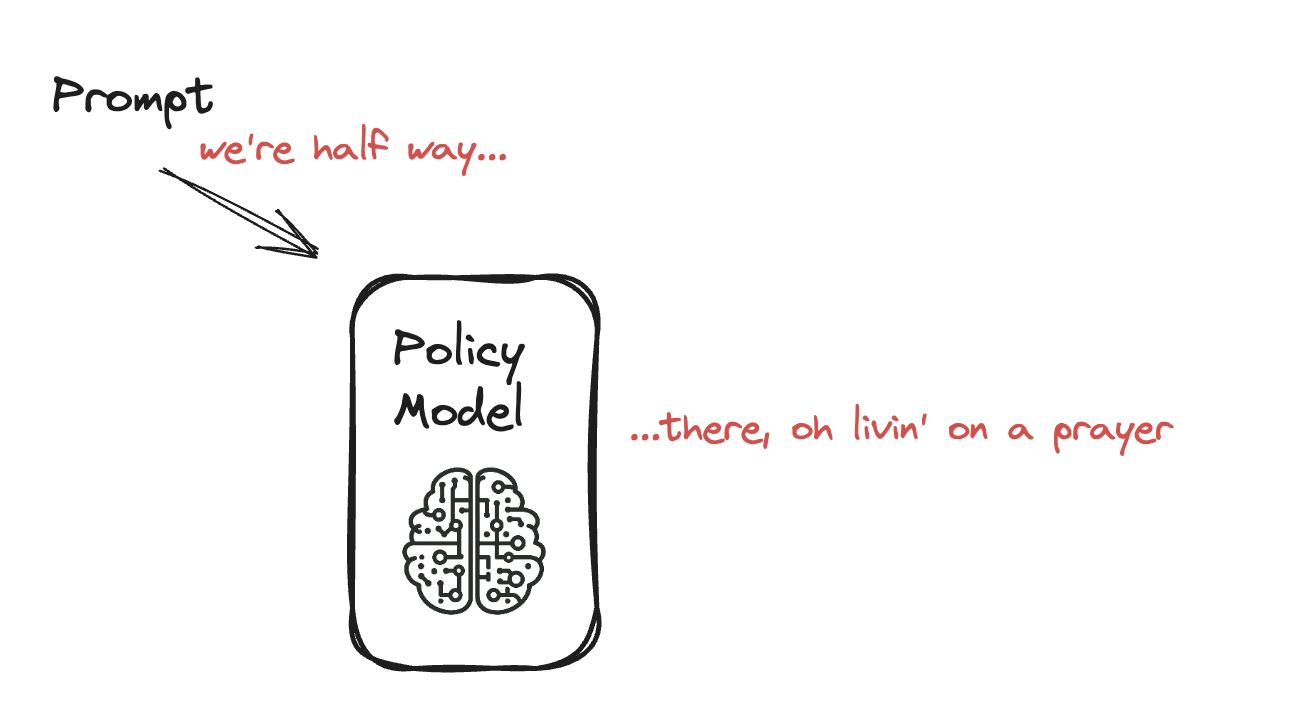
Een taalmodel fine-tunen met PPO
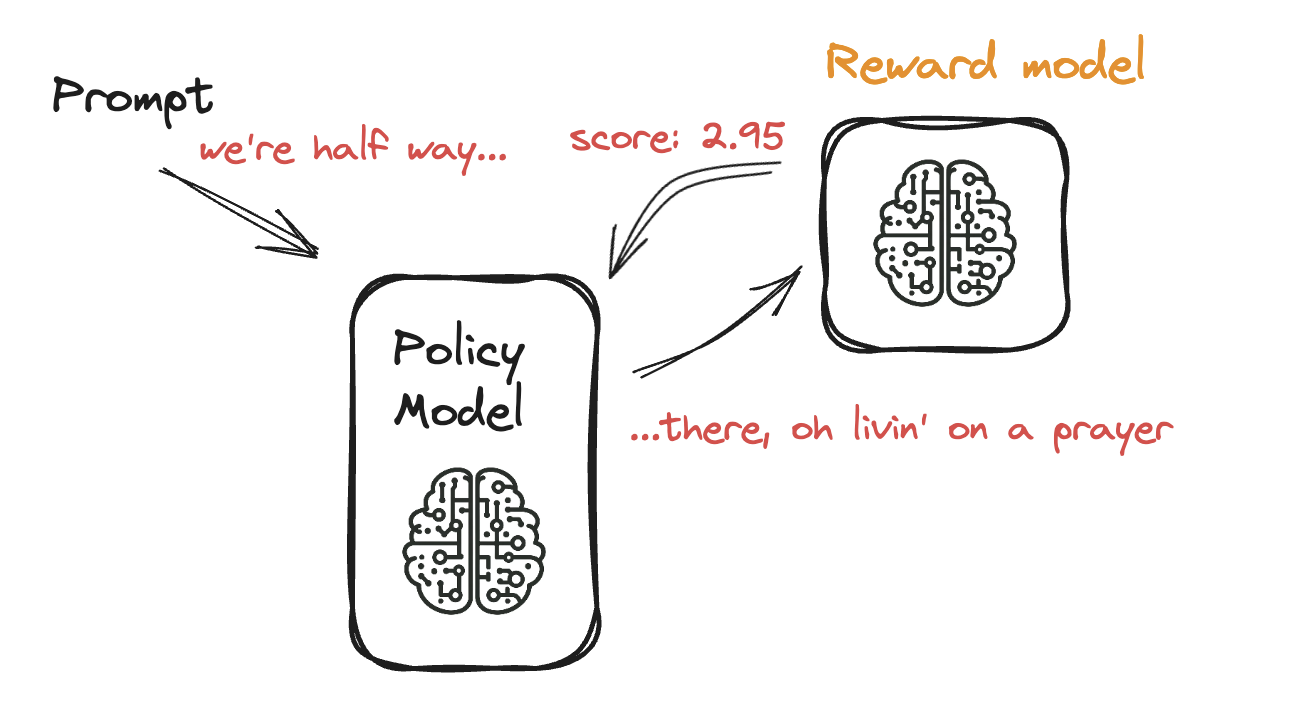
Een taalmodel fine-tunen met PPO
- PPO: geleidelijke aanpassing van het model
- Voorkomt overfitting op feedback


