Modelmetrics en -afstellingen
Reinforcement Learning from Human Feedback (RLHF)

Mina Parham
AI Engineer
Waarom een referentiemodel gebruiken?

Modeloutput controleren
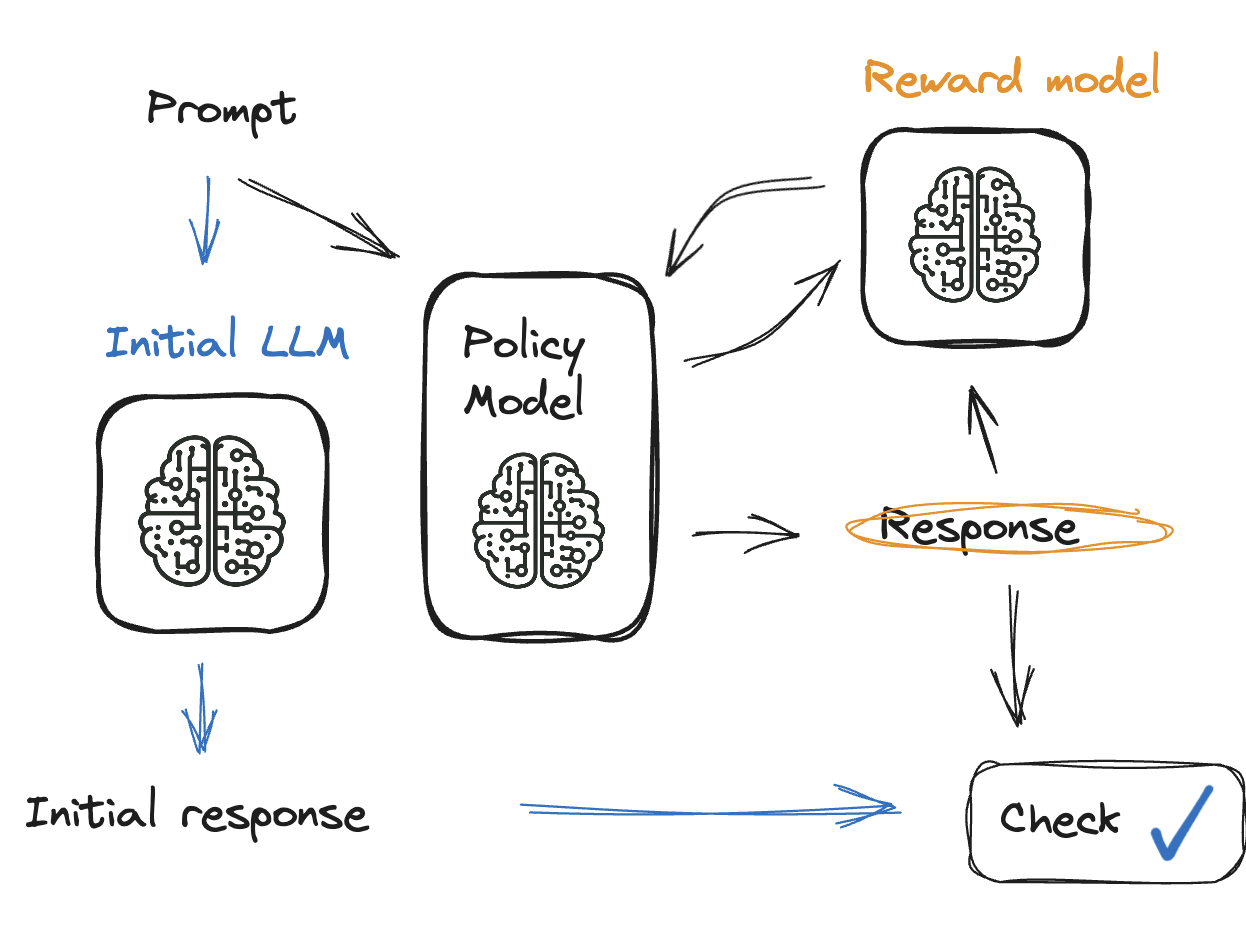
Oplossing: KL-divergentie
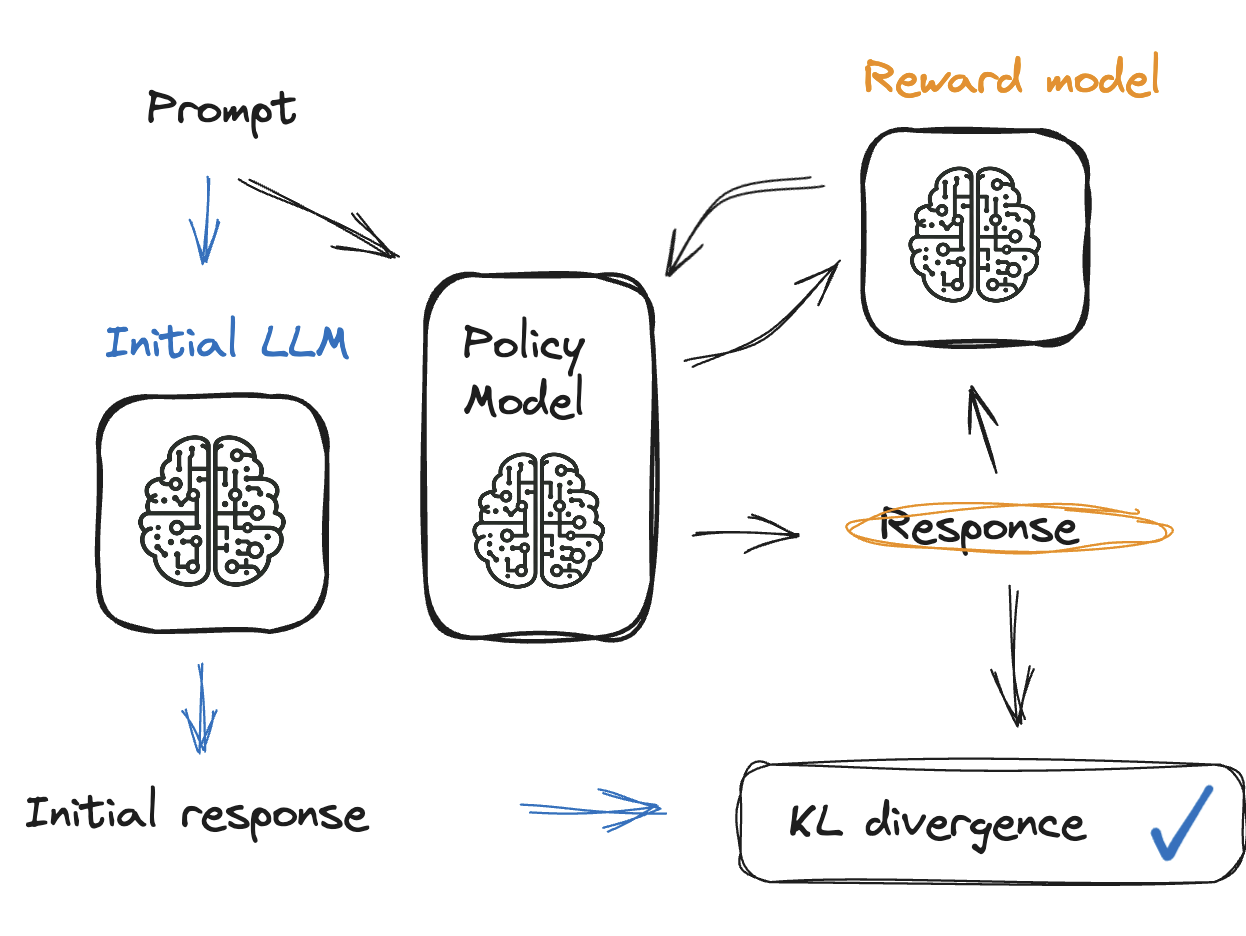
Oplossing: KL-divergentie
- Er wordt een straf aan het rewardmodel toegevoegd
- Straf stuurt het model bij bij irrelevante outputs
- KL-divergentie vergelijkt huidige en rewardmodel

- Tussen 0 en 10, en nooit negatief

