Feedback uit diverse bronnen integreren
Reinforcement Learning from Human Feedback (RLHF)

Mina Parham
AI Engineer
Betere generalisatie van het model

Minder bias
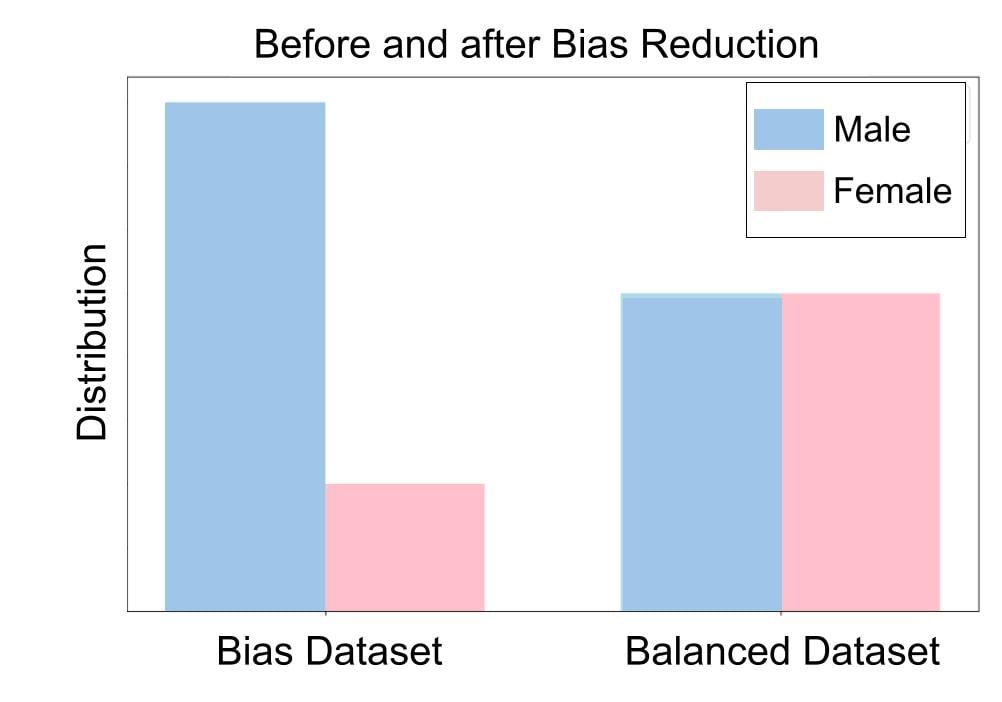
Betere afstemming op menselijke waarden

Meer aanpassingsvermogen

Meer robuustheid
Preferentiedata uit meerdere bronnen integreren
Preferentiedata preference_df met bronnen 'Journalist', 'Social Media Influencer' en 'Marketing Professional':

Onbetrouwbare preferentiebronnen
Preferentiedata preference_df2 met dezelfde drie experts:


