RLHF-modellen evalueren
Reinforcement Learning from Human Feedback (RLHF)

Mina Parham
AI Engineer
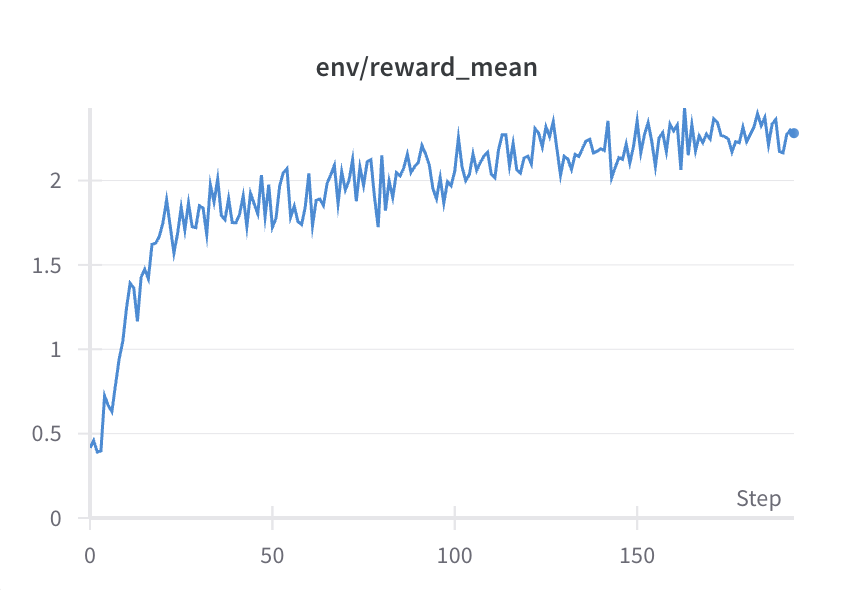
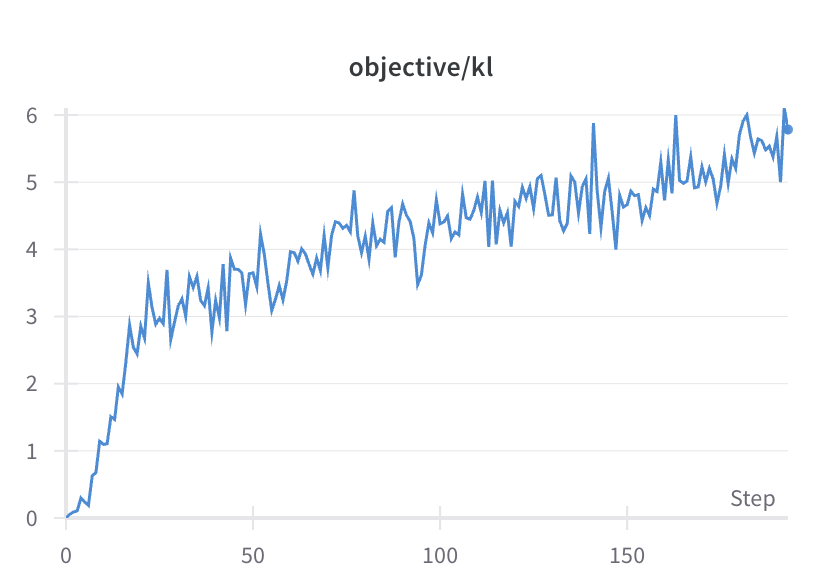
Artefactcurves

Artefactcurves
- Beloning stijgt naarmate het model leert.
- De KL-curve moet geleidelijk stijgen.
Mensgerichte evaluatie
- Humanevaluatie: subjectieve oordelen of diep contextbegrip

- Modelevaluatie: schaalbaar en consistent


