Train-, test- en validatiesets maken
Modelvalidatie in Python

Kasey Jones
Data Scientist
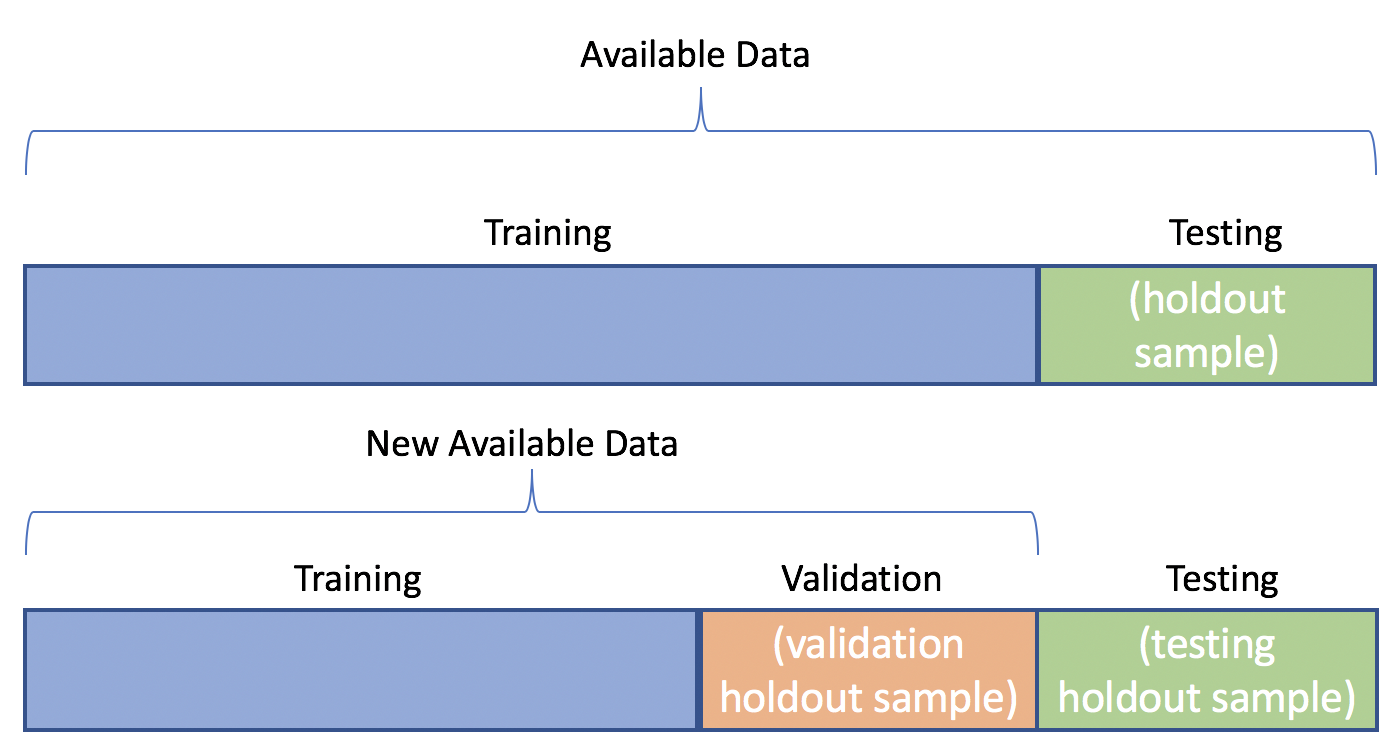
Traditionele train/test-split
- Geziene data (gebruikt voor training)
- Ongeziene data (niet gebruikt voor training)

Modelvalidatie in Python
Kasey Jones
Data Scientist

