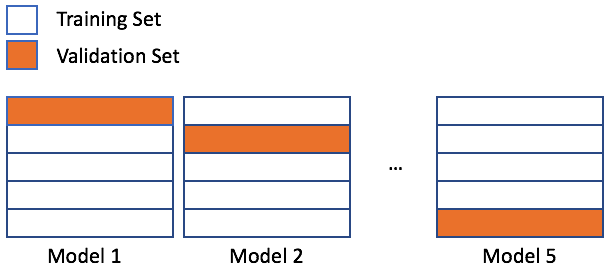
rfr = RandomForestRegressor(n_estimators=25, random_state=1111)
errors = []
for train_index, val_index in splits:
X_train, y_train = X[train_index], y[train_index]
X_val, y_val = X[val_index], y[val_index]
rfr.fit(X_train, y_train)
predictions = rfr.predict(X_val)
errors.append(<some_accuracy_metric>)
print(np.mean(errors))
4.25