Semantische gelijkenis meten met spaCy
Natural Language Processing met spaCy

Azadeh Mobasher
Principal Data Scientist
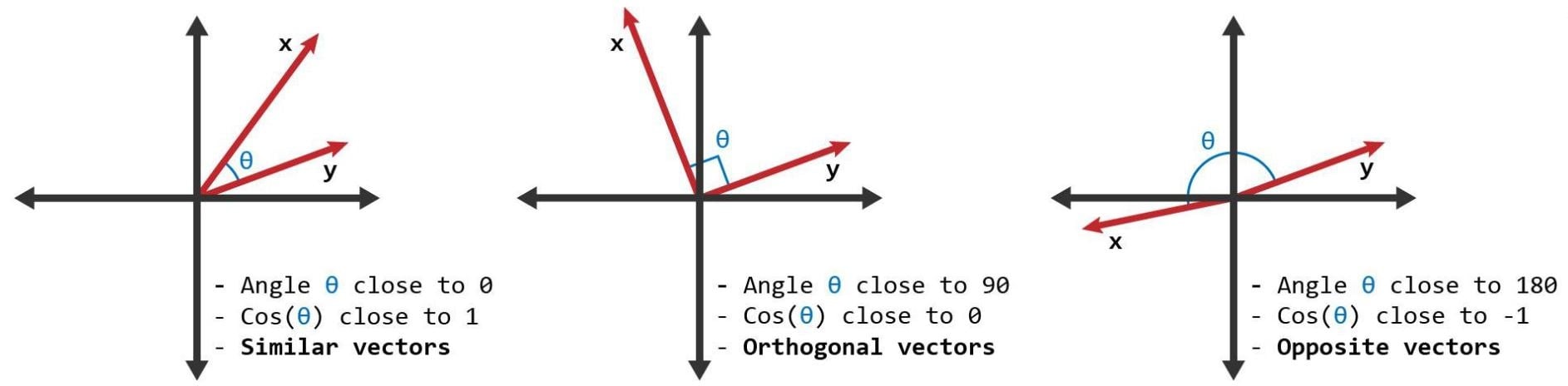
Similariteitsscore
- Een maat gedefinieerd voor teksten
- Voor gelijkenis: gebruik cosinusgelijkenis en woordvectoren
- Cosinusgelijkenis ligt tussen 0 en 1